바운딩 박스 기반 정책으로 모든 물체 조작하기 데이터 스케일링 법칙 탐구
초록
본 논문은 텍스트 명령만으로는 복잡한 환경에서 목표 물체에 집중하기 어려운 문제를 해결하고자, 손에 들 수 있는 라벨링 장치 Label‑UMI를 이용해 바운딩 박스 형태의 시각적 지시를 자동으로 생성한다. 바운딩 박스가 입력된 확산 기반 정책(BBox‑DP)은 객체 검출 모듈과 결합해 높은 일반화 성능을 보이며, 실험을 통해 객체 수와 성공률 사이에 거듭 제곱법칙 형태의 스케일링 법칙이 존재함을 확인한다.
상세 분석
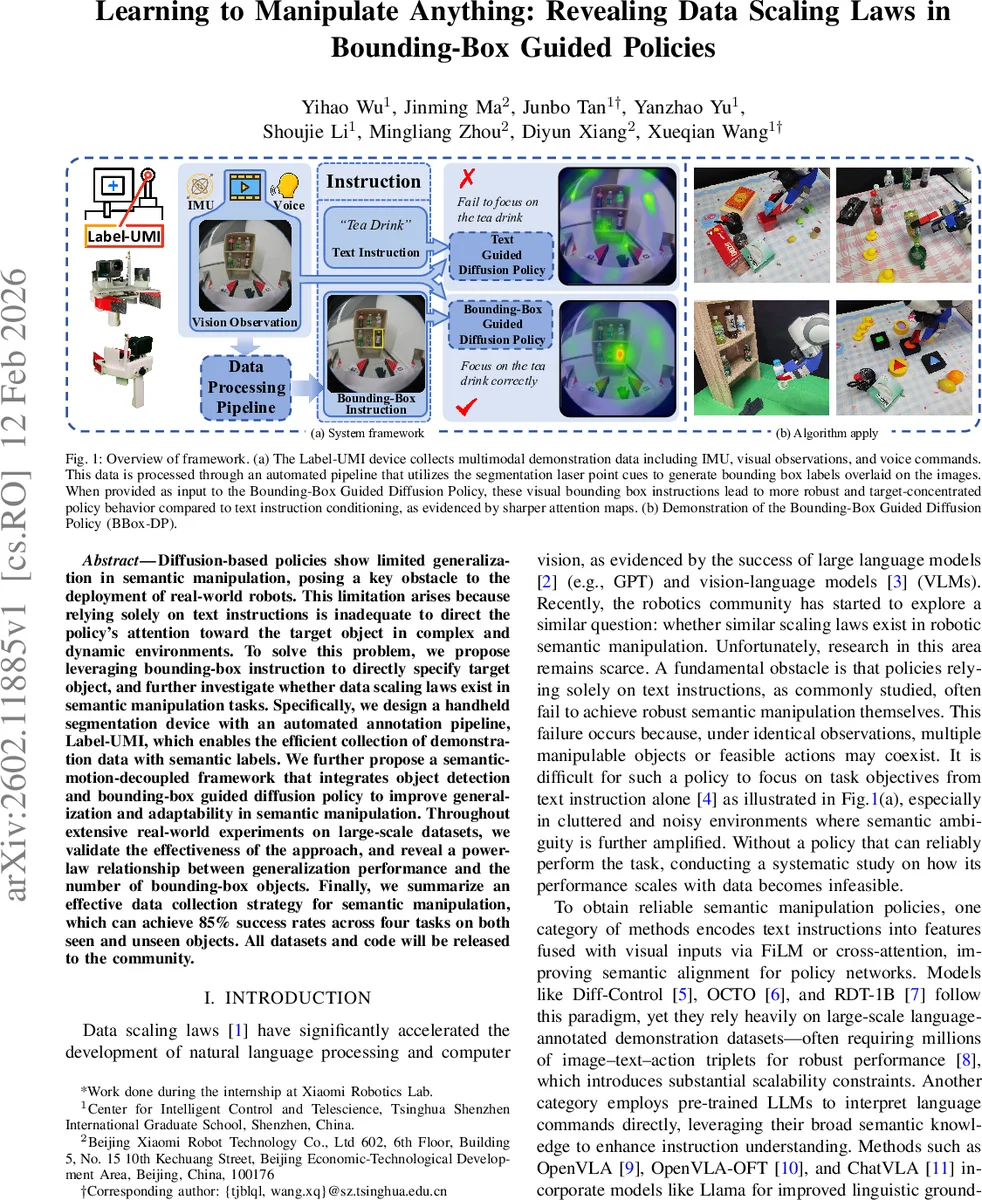
이 연구는 로봇 조작 분야에서 “텍스트‑만” 지시가 갖는 한계를 명확히 짚고, 시각적 지시인 바운딩 박스를 활용한 새로운 패러다임을 제시한다. 먼저, 저자들은 라벨링 장치 Label‑UMI를 설계하였다. 이 장치는 레이저 포인트와 조이스틱을 결합해 사용자가 목표 물체에 레이저를 정확히 조준하도록 하며, 동시에 영상, IMU, 음성 데이터를 동시 수집한다. 수집된 영상의 첫 프레임에서 레이저 점을 YOLOv8s‑ 기반 모델로 검출하고, 이를 SAM2에 점 프롬프트로 제공해 객체 마스크를 자동 생성한다. 마스크에서 최소 바운딩 박스를 추출함으로써, 별도의 수작업 라벨링 없이도 고정밀 바운딩 박스 라벨을 대량 확보한다. 이 파이프라인은 라벨링 비용을 크게 낮추면서도 정확도를 유지한다는 점에서 기존의 VR 텔레오퍼레이션이나 수동 라벨링 방식보다 뛰어나다.
다음으로, 저자들은 “Semantic‑Motion‑Decoupled” 아키텍처를 제안한다. 객체 검출 모듈(YOLO 혹은 DINOv2 등)이 텍스트 명령을 바운딩 박스로 변환하고, 변환된 시각적 지시를 확산 기반 정책에 조건으로 제공한다. 정책은 U‑Net 구조의 디퓨전 모델을 사용해 행동 시퀀스를 점진적으로 디노이즈하며, 최종적으로 목표 물체를 정확히 잡고 조작한다. 텍스트와 시각 정보를 FiLM 혹은 Cross‑Attention으로 결합하는 기존 방식과 달리, 바운딩 박스는 공간 정보를 명시적으로 제공하므로 정책이 목표 물체에 집중하기 쉬워진다. 또한, 시각적 지시를 별도 모듈로 분리함으로써 검출 모델을 교체하거나 업그레이드해도 정책 자체는 재학습 없이 그대로 활용할 수 있다.
실험에서는 네 가지 실세계 작업(쓰레기 처리, 음료 집어오기, 버튼 누르기, 물 붓기)을 수행했으며, 라벨링된 객체 수를 50, 100, 200, 300개 등으로 단계적으로 늘려가며 성능 변화를 측정했다. 결과는 성공률이 객체 수에 대해 로그‑로그 플롯에서 거의 직선 형태를 보이며, $Success \propto N^{\alpha}$ (α≈0.45)와 같은 거듭 제곱법칙을 따랐음을 보여준다. 즉, 데이터 규모가 커질수록 일반화 성능이 예측 가능한 비율로 향상된다. 특히, 본 방법은 동일한 데이터 양에서도 텍스트‑조건 정책 대비 20~30% 높은 성공률을 기록했으며, 훈련에 사용되지 않은 새로운 물체에 대해서도 85% 수준의 성공률을 유지했다.
마지막으로, 저자들은 효율적인 데이터 수집 전략을 제시한다. 라벨링 장치와 자동 파이프라인을 활용해 “1분당 10~12개의 고품질 바운딩 박스 라벨”을 생성할 수 있으며, 이는 기존 수동 라벨링 대비 5배 이상 빠른 속도이다. 이러한 전략은 대규모 로봇 조작 데이터베이스 구축에 실질적인 가이드라인을 제공한다. 전체적으로, 바운딩 박스 기반 시각적 지시와 확산 정책의 결합은 로봇이 복잡한 환경에서도 목표 물체를 정확히 인식·조작하도록 하는 강력한 방법임을 입증한다.
댓글 및 학술 토론
Loading comments...
의견 남기기