시각‑언어 앵커가 이끄는 정밀 강화학습: MLLM 추론의 새로운 패러다임
초록
본 논문은 멀티모달 대형 언어 모델(MLLM)에서 시각‑언어 토큰 간 연결성을 분석하고, 전체 토큰 중 약 15%만이 높은 시각‑텍스트 결합을 보인다는 ‘앵커 토큰’ 현상을 발견한다. 이를 기반으로 고연결성 토큰에 집중적으로 강화학습 신호를 전달하는 Anchor‑Token Reinforcement Learning(AT‑RL) 프레임워크를 제안하여, 32B 모델이 72B‑Instruct 기준을 능가하는 성능을 달성하면서도 연산 오버헤드가 1.2%에 불과함을 입증한다.
상세 분석
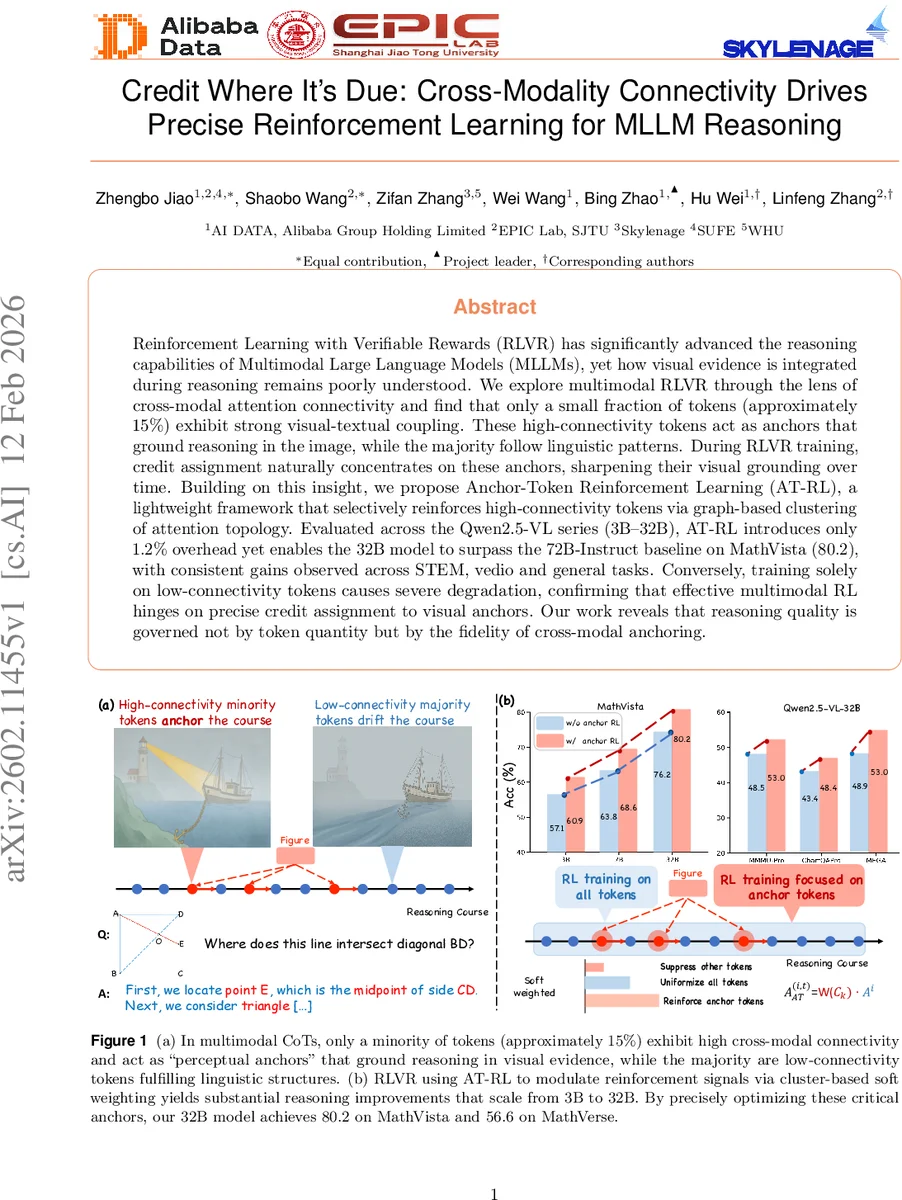
본 연구는 멀티모달 추론 과정에서 시각적 근거가 실제로 어떻게 활용되는지를 정량적으로 밝히는 데 초점을 맞춘다. 저자들은 Qwen2.5‑VL 시리즈 모델의 크로스‑모달 어텐션 행렬을 층·헤드별로 집계하고, 시각 패치와 텍스트 토큰 사이의 연결 강도를 ‘연결성(connectivity)’이라는 스칼라값으로 정의한다. 이때 전체 토큰 중 약 15%만이 시각 패치와 높은 어텐션 가중치를 공유하며, 이 토큰들을 ‘퍼셉추얼 앵커(perceptual anchors)’라 명명한다. 앵커 토큰은 체인‑오브‑소트(Chain‑of‑Thought) 과정에서 시각 정보를 직접 참조해 문제 해결의 핵심 단계를 형성하고, 나머지 토큰은 언어적 흐름을 유지하는 보조 역할을 수행한다는 점을 실험적으로 검증한다.
RLVR( reinforcement learning with verifiable rewards) 기존 알고리즘은 보상 신호를 모든 토큰에 균등하게 전파한다. 저자들은 이러한 균등 배분이 시각‑언어 상호작용을 희석시켜, 실제로 시각 근거가 필요한 단계에서 학습 효율이 떨어진다고 지적한다. 이를 해결하기 위해 AT‑RL은 세 단계로 구성된다. 첫째, 연결성 행렬을 정규화·편향 보정(Bias‑Correction)한 뒤, 상위 15% 토큰을 자동으로 식별한다. 둘째, 토큰‑레벨 그래프를 구축하고, 그래프 파티셔닝(예: Louvain 알고리즘)으로 의미적 클러스터를 형성한다. 셋째, 각 클러스터의 평균 연결성 밀도에 비례하는 가중치를 부여해 시퀀스‑레벨 어드밴티지를 토큰‑레벨 신호로 재스케일링한다. 이때 가중치는 ‘소프트’ 방식으로 적용돼, 앵커 토큰에 강화학습 신호가 집중되면서도 비앵커 토큰의 언어적 일관성은 유지된다.
실험 결과는 두드러진데, 3B‑32B 규모 모델에 AT‑RL을 적용했을 때 MathVista, MathVerse, VideoMMMU 등 다양한 멀티모달 벤치마크에서 일관된 성능 향상이 관찰된다. 특히 32B 모델은 80.2점으로 72B‑Instruct 기준을 넘어섰으며, 연산 비용은 기존 RLVR 대비 1.2%만 추가되었다. 반대로 저연결성 토큰에만 강화학습을 적용하거나 무작위 가중치를 부여하면 성능이 급격히 저하되는 현상이 보고돼, 시각‑언어 앵커에 대한 정확한 크레딧 할당이 멀티모달 RL의 핵심임을 실증한다.
한계점으로는 현재 연결성 임계값과 클러스터링 파라미터가 고정돼 있어, 도메인별 최적화가 필요할 수 있다는 점, 그리고 어텐션 기반 연결성만을 사용함에 따라 시각‑언어 상호작용의 다른 형태(예: 멀티‑헤드 상호보완성)를 포착하지 못한다는 점을 들 수 있다. 향후 연구에서는 동적 임계값 조정, 멀티‑모달 포지션 인코딩 결합, 그리고 비지도 시각‑언어 정합성 평가 지표를 도입해 AT‑RL을 확장할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기