스냅MLA FP8 양자화 기반 장기 컨텍스트 디코딩 가속화
초록
SnapMLA는 DeepSeek MLA 구조의 디코딩 단계에서 FP8 양자화를 적용하기 위한 하드웨어‑소프트웨어 공동 최적화 프레임워크이다. RoPE‑Aware 토큰‑단위 KV 양자화, PV 연산 파이프라인 재구성, 그리고 엔드‑투‑엔드 데이터 흐름 최적화를 통해 장기 컨텍스트에서 최대 1.91배의 처리량 향상을 달성하면서 정확도 저하를 최소화한다.
상세 분석
SnapMLA 논문은 FP8 양자화를 MLA(멀티‑헤드 라텐트 어텐션) 디코딩에 적용할 때 발생하는 세 가지 핵심 문제를 체계적으로 분석한다. 첫 번째는 KV 캐시가 압축된 콘텐츠와 고정밀 RoPE(회전 위치 임베딩) 두 부분으로 분리되면서, 동일한 스케일로 양자화하면 RoPE의 동적 범위가 크게 손실되는 ‘수치 이질성’이다. 저자들은 실험을 통해 콘텐츠는 ±10¹ 수준에 집중되는 반면 RoPE는 ±10³까지 확장됨을 확인하고, FP8 양자화가 RoPE에 적용될 경우 MSE가 급격히 증가한다는 사실을 제시한다. 이를 해결하기 위해 ‘RoPE‑Aware Per‑Token KV Quantization’을 제안한다. 여기서는 콘텐츠만 FP8로 양자화하고 RoPE는 BF16으로 유지하며, 토큰 단위로 즉시 양자화함으로써 “tail buffer” 관리 비용을 없앤다.
두 번째 문제는 FP8 PV GEMM 연산 시 Hopper 텐서 코어가 요구하는 k‑major 레이아웃과, MLA가 KV를 공유 구조로 사용하면서 V의 스케일이 감소 차원에 정렬되는 구조적 불일치이다. 기존의 post‑GEMM 역스케일링이 불가능해 성능 저하가 발생한다. 논문은 이를 ‘Scale‑Fusion PV Quantization’으로 해결한다. V 스케일을 어텐션 확률 행렬 P에 사전 결합하고, 블록‑와이즈 동적 양자화를 적용해 P′의 동적 범위를 조정한다. 이후 Softmax 단계에서 암묵적으로 역스케일링을 수행해 별도 디퀀타이징 연산 없이 정확한 결과를 얻는다.
세 번째는 시스템 수준 최적화이다. KV 양자화와 PV 연산 재구성을 지원하기 위해 맞춤형 CUDA 커널을 설계하고, 데이터 읽기·쓰기 흐름을 파이프라인화한다. 특히 RoPE‑Aware 양자화에서 발생하는 혼합 정밀도 누적 문제를 해결하기 위해 RoPE를 콘텐츠 스케일의 역수로 사전 스케일링해 FP8 도메인에 맞춘다. 이렇게 하면 기존 고성능 QK GEMM 커널의 스레드 그룹 스케줄링을 그대로 유지하면서 추가 동기화 비용을 회피한다.
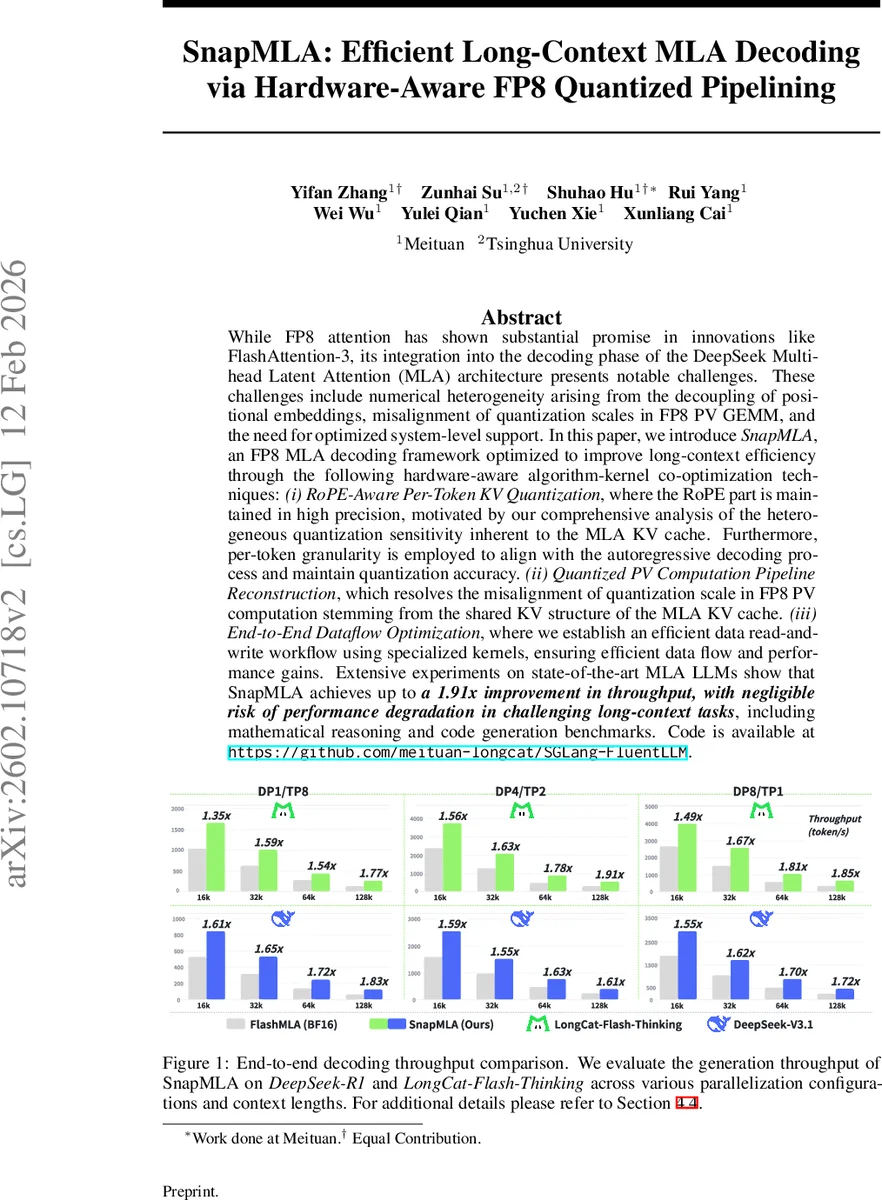
실험 결과는 DeepSeek‑R1 및 LongCat‑Flash‑Thinking 모델을 대상으로 다양한 컨텍스트 길이와 병렬 설정에서 평가되었다. SnapMLA는 평균 1.45×, 최악의 경우 1.91×까지 처리량을 향상시켰으며, 수학적 추론, 코드 생성 등 장기 컨텍스트가 중요한 벤치마크에서 정확도 손실은 미미했다. 전체적으로 이 논문은 MLA 구조의 고유한 수치 특성을 정밀히 분석하고, 하드웨어 제약을 고려한 양자화 스케일 관리 기법을 제시함으로써 FP8 기반 장기 디코딩의 실용성을 크게 확장한다.
댓글 및 학술 토론
Loading comments...
의견 남기기