보상에 맞춘 탐색 가치 기반 구조적 샘플링과 최적화
초록
본 논문은 자동 회귀 기반 생성 추천 모델을 강화학습으로 미세조정할 때 발생하는 확률‑보상 불일치를 해결한다. 저자는 가치‑가이드 효율적 디코딩(VED)으로 탐색이 중요한 노드를 선별하고, 형제‑GRPO로 트리 구조 내 상대적 어드밴티지를 학습한다. 실험 결과 V‑STAR가 정확도와 후보 다양성 모두에서 기존 최첨단 방법들을 능가함을 보인다.
상세 분석
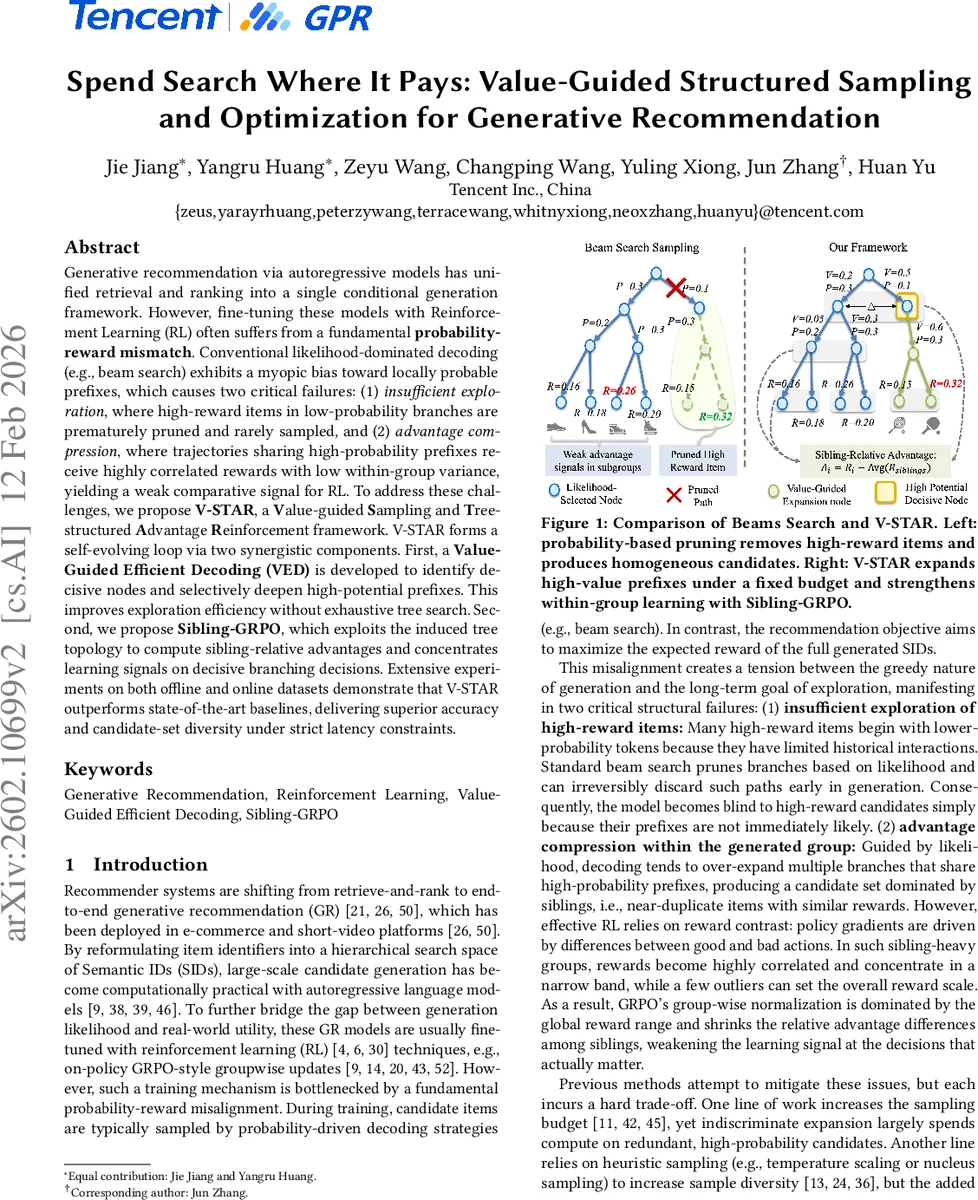
V‑STAR는 생성 추천에서 “확률‑보상 불일치”라는 근본적인 문제를 두 가지 현상으로 구체화한다. 첫째, 전통적인 빔 서치는 확률이 높은 프리픽스만을 확장해 저확률이지만 고보상을 가진 아이템을 조기에 차단한다(탐색 부족). 둘째, 동일 프리픽스를 공유하는 후보들이 군집을 이루면서 보상의 분산이 감소하고, 그룹 정규화된 어드밴티지가 거의 동일해지는(어드밴티지 압축) 현상이 발생한다. 이러한 구조적 결함은 RL‑기반 정책 업데이트의 학습 신호를 약화시킨다.
V‑STAR는 이를 해결하기 위해 두 가지 핵심 모듈을 설계한다. ① 가치‑가이드 효율적 디코딩(VED)은 후보 트리를 얕게 빔 서치로 초기 탐색한 뒤, 각 프리픽스에 대해 경량 가치 함수 Vφ와 불확실성(예: 정책 엔트로피)을 평가한다. 가치가 높고 다음 토큰 선택이 애매한 “결정적” 노드만을 선택해 추가 디코딩 예산을 할당함으로써, 저확률 고보상 경로를 복구하고 탐색 효율을 크게 향상시킨다. Vφ는 사전 학습된 텍스트 인코더의 아이템 임베딩을 활용한 의미‑기반 밀집 보상 신호를 사용해, 희소한 최종 보상 대신 단계별 의미 유사도 기반 보상을 제공한다.
② 형제‑GRPO는 트리 구조에서 형제 그룹을 형성하고, 각 그룹 내부에서 상대 어드밴티지를 계산한다. 기존 GRPO가 전체 후보 집합에 대해 전역 평균·표준편차로 정규화하는 반면, 형제‑GRPO는 부모 프리픽스 아래의 형제 후보들만을 대상으로 평균·표준편차를 구한다. 이렇게 하면 고확률 프리픽스에 의해 발생하는 보상 군집의 압축을 완화하고, 분기 결정 단계에서의 신호 강도를 높인다. 또한, 형제‑GRPO는 리스트‑와이즈 랭킹 목표와 유사하게 후보 간 상대적 순위를 직접 최적화하므로, 정책 그라디언트의 분산을 감소시킨다.
두 모듈은 서로 순환적으로 개선된다. VED가 더 다양하고 가치가 높은 후보를 제공하면, 형제‑GRPO는 더 풍부한 어드밴티지 차이를 학습해 정책을 강화한다. 강화된 정책은 다시 VED의 가치 추정 정확도를 높여, 다음 라운드에서 더욱 정교한 탐색을 가능하게 만든다.
실험에서는 오프라인 공개 데이터와 실제 서비스 환경(온라인 A/B 테스트) 모두에서 V‑STAR가 클릭‑스루‑레이트(CTR), 정밀도, 후보 다양성(다양성 지표)에서 기존 빔 서치+GRPO, 온도 샘플링, MCTS 기반 방법들을 크게 앞선다. 특히 동일한 디코딩 지연(≤ 30 ms) 내에서 탐색 효율을 2배 이상 개선했으며, 어드밴티지 압축을 완화한 덕분에 학습 안정성도 향상되었다.
요약하면, V‑STAR는 (1) 가치‑가이드 디코딩으로 탐색을 목표‑중심적으로 재배분하고, (2) 트리‑구조형 형제‑GRPO로 학습 신호를 구조화함으로써, 생성 추천 시스템에서 확률‑보상 불일치를 근본적으로 해소한다는 점에서 의의가 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기