멀티모달 이해를 위한 완전 이산 모델 켈릭
초록
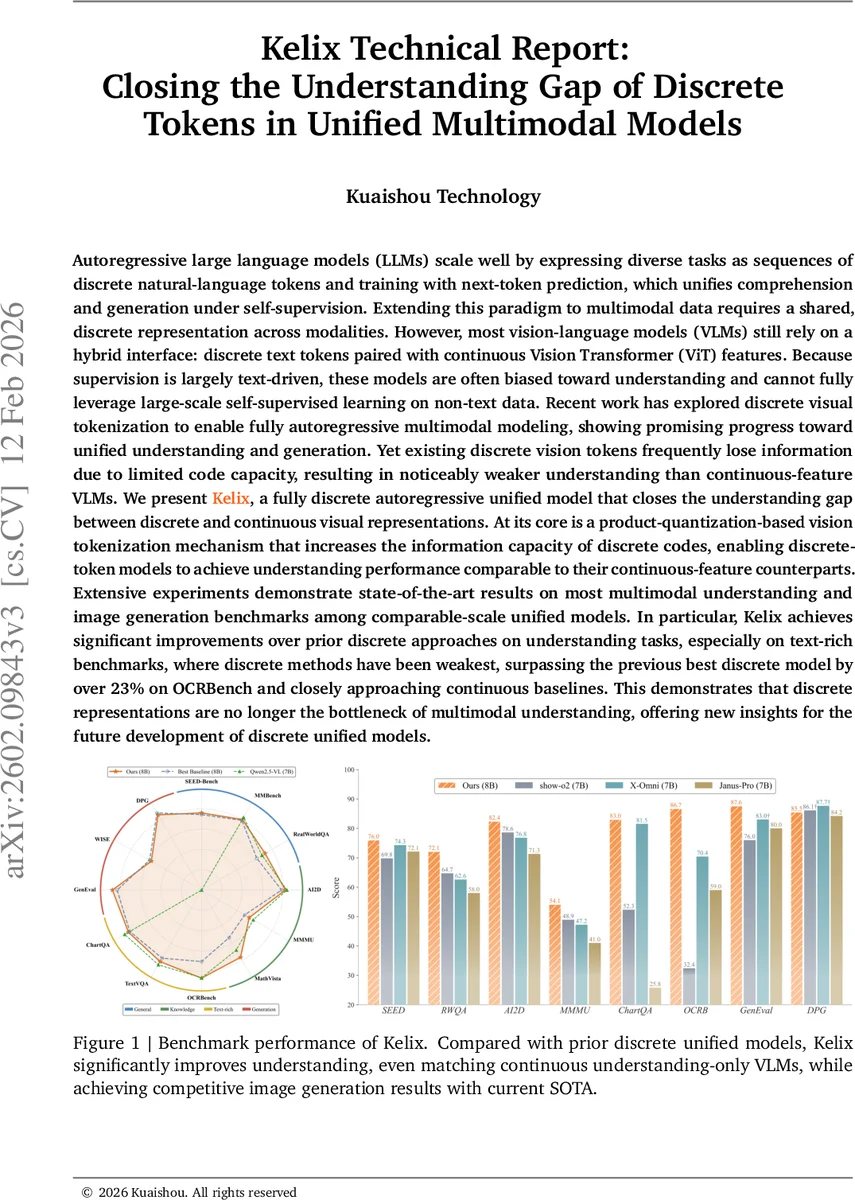
켈릭은 제품 양자화 기반의 고용량 시각 토크나이저와 차세대 블록 예측 방식을 도입해, 기존 이산 비전 토큰이 갖는 정보 손실 문제를 극복하고, 연속형 피처 기반 VLM과 동등한 수준의 멀티모달 이해 성능을 달성한 완전 이산 자동회귀 모델이다.
상세 분석
본 논문은 대규모 언어 모델(LLM)의 성공 요인을 멀티모달 영역에 그대로 적용하기 위해, 텍스트와 시각 정보를 동일한 이산 토큰 공간으로 매핑하는 방법론을 제시한다. 기존 비전‑언어 모델(VLM)은 텍스트 토큰은 이산 형태이지만, 이미지 특징은 연속형 ViT 임베딩을 그대로 사용해 하이브리드 인터페이스를 구성한다. 이 접근법은 텍스트 중심의 학습 편향을 초래하고, 비텍스트 데이터에 대한 자기지도 학습 활용을 제한한다. 켈릭은 이러한 한계를 해소하기 위해 두 가지 핵심 기술을 도입한다. 첫째, 제품 양자화(Product Quantization, PQ)를 기반으로 한 시각 토크나이저를 설계한다. 기존 VQ‑VAE 방식은 하나의 코드북 인덱스로 1024‑차원 임베딩을 압축해 16비트 정도의 정보만 전달한다. 반면 PQ는 각 패치 임베딩을 N개의 서브스페이스로 분할하고, 각각 독립적인 서브코드북에 매핑함으로써 조합 가능한 코드 수가 K^N(예: 8 × 8192 = 65 536)까지 확대된다. 이렇게 얻어진 N개의 이산 토큰은 합산(pooling) 과정을 거쳐 하나의 복합 토큰으로 변환되어 LLM 입력 길이를 유지하면서도 정보 용량은 크게 늘어난다. 둘째, 차세대 블록 예측(Next‑Block Prediction, NBP) 방식을 도입해 시각 블록을 N개의 토큰 +
댓글 및 학술 토론
Loading comments...
의견 남기기