자연어 통계로부터 신경망 스케일링 법칙 유도
초록
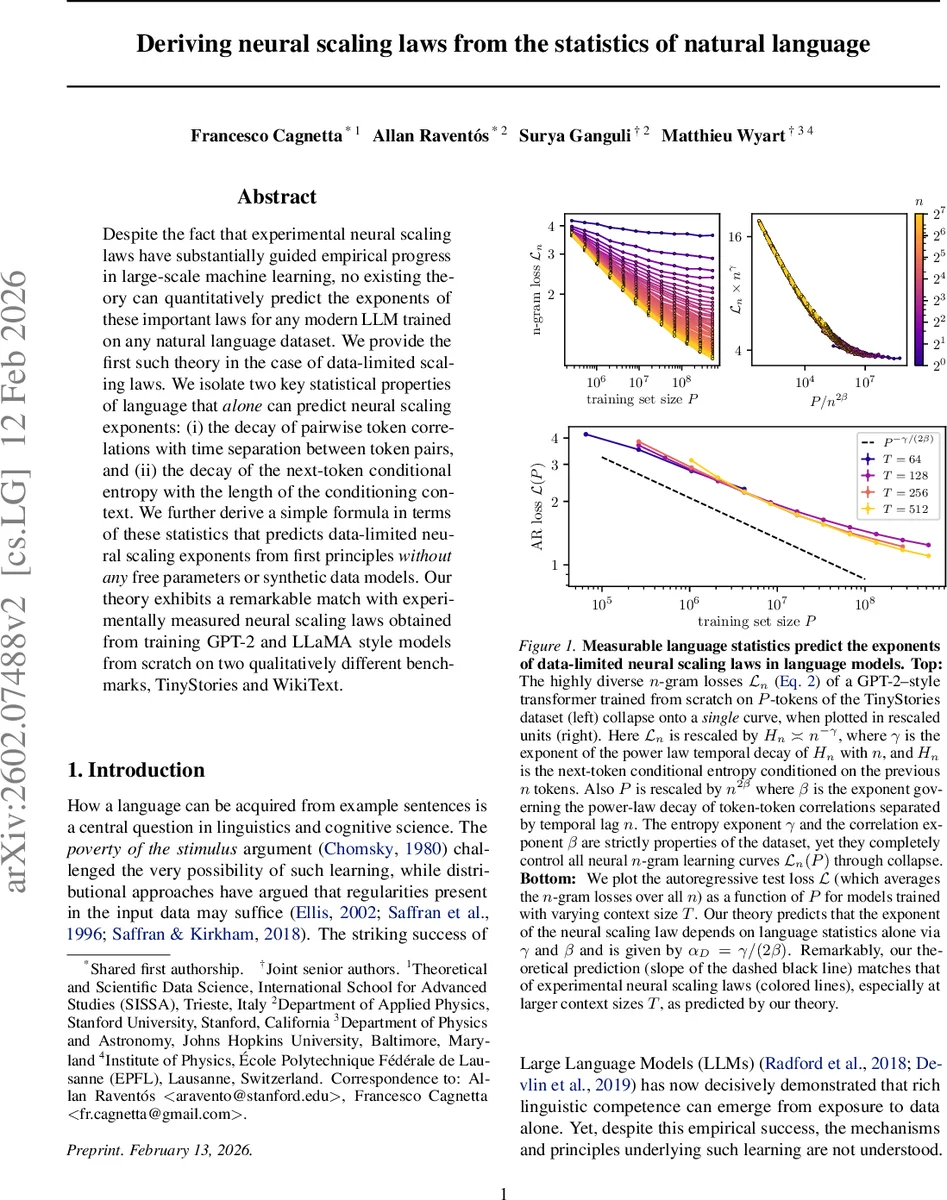
본 논문은 데이터 제한 상황에서 대규모 언어 모델의 손실 감소율(스케일링 지수)을 자연어 자체의 두 가지 통계적 특성, 즉 토큰 간 상관감소 지수 β와 조건부 엔트로피 감소 지수 γ만으로 예측하는 이론을 제시한다. 이론적 공식 α_D = γ/(2β)를 실험적으로 검증하기 위해 TinyStories와 WikiText‑103 두 데이터셋에 대해 GPT‑2 및 LLaMA 스타일 모델을 다양한 컨텍스트 길이와 데이터 양으로 학습시켰으며, 측정된 β, γ 값으로부터 얻은 예측 지수가 실제 학습 곡선의 지수와 매우 높은 일치도를 보였다. 또한 n‑gram 손실 곡선들을 β와 γ에 기반한 재스케일링을 통해 하나의 마스터 커브로 붕괴(collapse)시키는 현상을 확인하였다.
상세 분석
이 연구는 기존의 커널 기반 스케일링 이론이 LLM의 특징 학습 메커니즘을 포착하지 못한다는 점을 지적하고, 언어 자체가 가진 장기 의존성 구조가 데이터 제한 스케일링을 결정한다는 새로운 관점을 제시한다. 핵심 가정은 두 가지 통계량: (i) 토큰‑토큰 공분산 행렬의 최고 특이값이 시간 지연 n에 대해 ∥C(n)∥op ∝ n^(-β) 로 감소한다는 점, (ii) 다음 토큰의 조건부 엔트로피 H_n이 n에 대해 H_n - H∞ ∝ n^(-γ) 로 감소한다는 점이다. 이 두 지수를 측정하면, 데이터 양 P에 대해 모델이 효과적으로 활용할 수 있는 예측 시간 지평선 n*(P) ≈ P^{1/(2β)} 를 얻을 수 있다. 손실은 H_{n*}와 내부 예측 오차 E_n의 합으로 분해되며, E_n이 충분히 빠르게 감소한다는 가정 하에 전체 자동 회귀 손실 L_AR(P) - H_∞ ≈ P^{-γ/(2β)} 가 도출된다. 즉, 스케일링 지수 α_D는 언어 통계만으로 α_D = γ/(2β) 로 완전히 결정된다.
실험에서는 두 데이터셋에서 γ와 β를 각각 약 0.7, 0.35 정도로 측정했으며, 이 값으로부터 α_D ≈ 1.0 정도를 예측했다. 실제로 다양한 컨텍스트 길이 T(64~512)와 모델 크기에서 측정된 손실 감소율은 이 예측과 거의 일치했으며, 특히 큰 T일수록 이론과의 차이가 최소화되는 경향을 보였다. 또한 n‑gram 손실 L_n(P)를 P/n^{2β} 로 재스케일링하고, 수직축을 n^{-γ} 로 정규화하면 모든 n에 대해 동일한 마스터 곡선 ℓ(·) 위에 겹쳐지는 현상이 관찰되었다. 이는 데이터 양이 증가함에 따라 모델이 점차 더 긴 컨텍스트를 활용하게 되고, 그 과정이 언어의 장기 상관 구조에 의해 지배된다는 이론적 주장과 일치한다.
이론적 프레임워크는 몇 가지 제한점을 가진다. 첫째, E_n(P)의 빠른 감소가 실제로 깊은 트랜스포머에만 적용된다는 가정이며, 얕은 네트워크나 고정 커널 모델에서는 이 가정이 깨질 수 있다. 둘째, 토큰‑토큰 상관을 단일 특이값으로 요약하는 것이 실제 언어의 복합적 구조를 충분히 포착하는지에 대한 검증이 필요하다. 셋째, 데이터 제한 스케일링 외에 모델 크기 제한이나 계산 제한 영역에서는 다른 지수가 작용할 가능성이 있다. 그럼에도 불구하고, 언어 자체의 통계적 지표만으로 스케일링 지수를 정확히 예측한다는 점은 LLM 설계와 데이터 수집 전략에 실질적인 가이드라인을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기