IBISAgent: 의료 영상에서 픽셀 수준 시각 추론을 강화하는 새로운 에이전트 기반 MLLM
초록
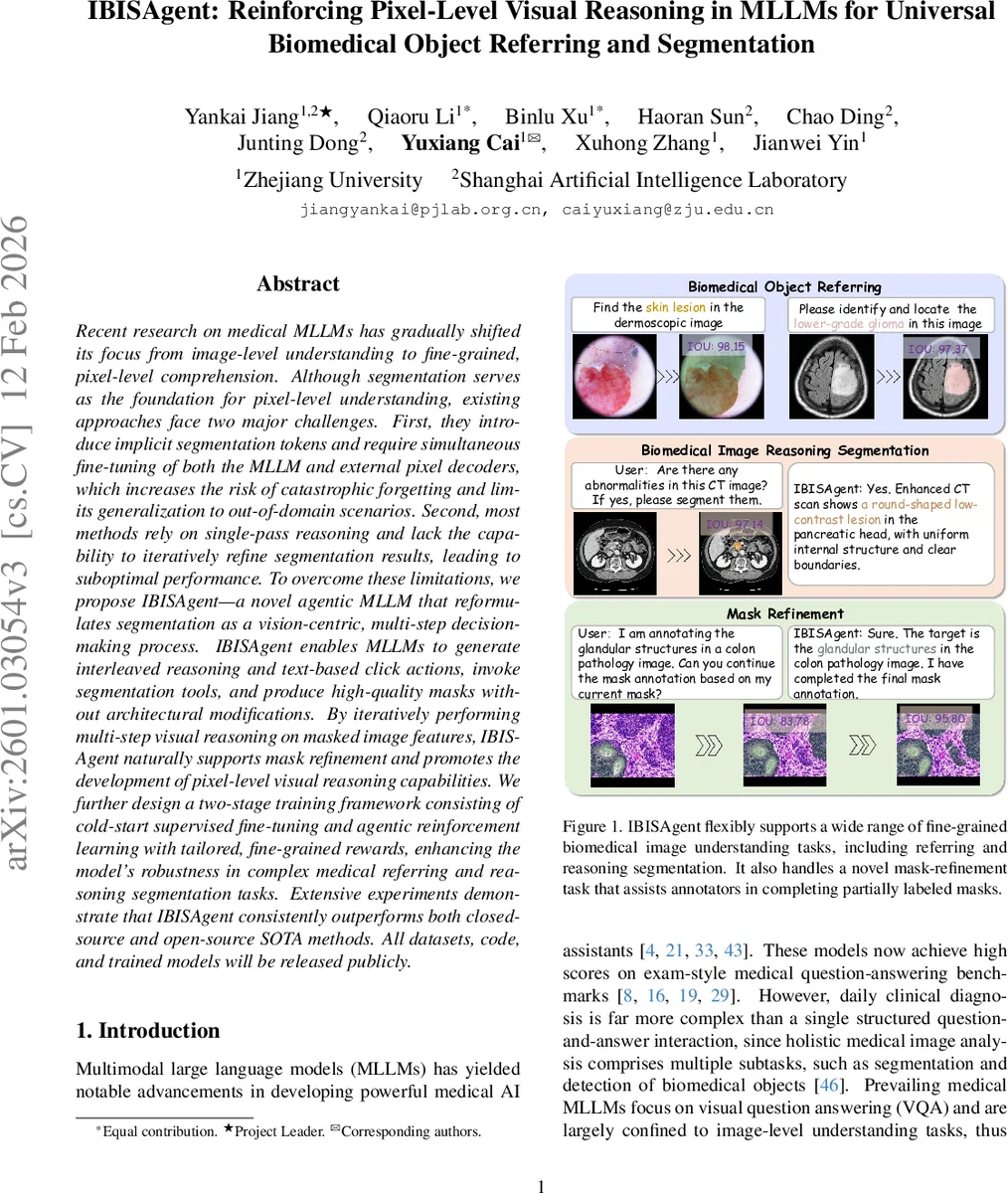
IBISAgent는 멀티모달 대형 언어 모델에 시각‑중심의 다단계 의사결정 과정을 도입해, 암시적 세그멘테이션 토큰 없이도 의료 이미지의 픽셀‑레벨 객체를 정확히 찾아내고 마스크를 반복적으로 정제한다. 냉각‑시작 지도학습과 세밀한 보상이 설계된 강화학습을 결합한 두 단계 학습 프레임워크를 통해 기존 방법들을 지속적으로 능가한다.
상세 분석
IBISAgent는 기존 의료 MLLM이 겪는 두 가지 근본적인 한계를 혁신적으로 해소한다. 첫째, 기존 모델은
둘째, 기존 방법은 단일 패스(single‑pass) 추론에 머물러, 초기 클릭이나 프롬프트가 부정확할 경우 결과를 바로잡을 수 없다. IBISAgent는 세그멘테이션을 마코프 결정 과정(MDP)으로 재구성한다. 매 단계 t에서 모델은 (rₜ, aₜ, oₜ) 삼중항을 생성한다. 여기서 rₜ는 텍스트 기반 사고, aₜ는 “positive/negative click + 좌표” 형태의 행동, oₜ는 클릭과 이전 마스크를 입력으로 하는 외부 세그멘테이션 툴(예: MedSAM2)에서 반환된 마스크이다. 이렇게 얻은 oₜ는 반투명 오버레이 형태로 이미지에 재삽입돼 다음 단계의 입력이 되므로, 모델은 자신의 이전 예측을 직접 시각적으로 검토하고, 필요 시 추가 클릭을 통해 마스크를 점진적으로 개선한다.
학습 측면에서 저자는 두 단계 전략을 채택한다. 첫 번째 단계인 “cold‑start supervised fine‑tuning (SFT)”에서는 대규모 바이오메디컬 이미지‑마스크 데이터(3.4M 쌍)에서 자동 클릭 시뮬레이션(F_cs)으로 생성한 단계별 트래젝터리를 이용해, 모델이 올바른 사고·행동·관찰 순서를 학습하도록 한다. 두 번째 단계인 “agentic reinforcement learning (RL)”에서는 세밀하게 설계된 보상 함수를 도입한다. 보상은 (1) 클릭 위치가 실제 오류 영역에 얼마나 가까운가를 평가하는 region‑based click reward, (2) 각 단계마다 IoU 향상 정도를 측정하는 progressive IoU reward, (3) 불필요한 단계 수를 억제하는 trajectory length penalty 등을 포함한다. 이러한 보상은 모델이 단순히 인간 트레이스 복제에 머무르지 않고, 자체적으로 효율적인 클릭 정책을 탐색하도록 유도한다.
실험 결과는 IBISAgent가 폐쇄형·오픈소스 최첨단 모델들을 일관되게 앞선다는 점을 보여준다. 특히 도메인 외 데이터셋에서의 zero‑shot 성능과, 부분 마스크를 입력받아 완전한 마스크로 확장하는 “mask refinement” 시나리오에서 두드러진 개선을 기록한다. 또한, 다중 클릭을 동시에 처리하고, 다양한 의료 영상 모달리티(CT, 병리 슬라이드, 피부 사진 등)에 적용 가능함을 입증한다.
핵심 기여는 (1) 구조적 변형 없이 LLM의 텍스트 기반 사고와 시각적 행동을 결합한 에이전트 프레임워크, (2) 자동화된 트래젝터리 생성과 두 단계 학습 파이프라인, (3) 정밀 보상 설계로 구현된 자기‑반복적 마스크 정제 메커니즘이다. 이 접근법은 향후 의료 이미지 분석뿐 아니라, 일반 이미지 분야에서도 인간과 유사한 인터랙티브 세그멘테이션을 구현하는 데 중요한 토대를 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기