프리트레인에서 파인튜닝까지: 지식 전이와 캘리브레이션의 마법적 상관관계
초록
이 논문은 대형 언어 모델이 사전학습 단계에서 얻은 정확도와 신뢰도(Confidence)가 지도학습 파인튜닝(SFT) 후에도 유지되는지를 다섯 가지 상관관계 프로토콜로 정량화한다. 240M·1B 파라미터 모델을 9가지 데이터 혼합으로 사전학습하고, 20개 벤치마크(상식, 과학, NLI, 의미 이해)에서 정확도·신뢰도를 측정한다. 주요 결과는(1) 모델 규모가 클수록 정확도 상관은 높아지지만 신뢰도 상관은 낮아지는 역스케일링, (2) 벤치마크마다 전이 신뢰도가 크게 다르고, 특히 NLI·의미 이해는 불안정, (3) 작은 모델에서는 같은 카테고리 내 경쟁이 존재하지만 큰 모델에서는 시너지 효과가 나타남, (4) 캘리브레이션 정렬(정확도‑신뢰도 상관)은 도메인별로 차이가 나며 과학 분야는 잘 정렬되지만 상식·의미 이해는 과대신뢰가 지속, (5) 교육용 필터링 데이터는 과학 정확도는 유지·향상시키지만 캘리브레이션은 악화시킨다. 이러한 인사이트는 벤치마크 선택, 데이터 커리케이션, 효율적 모델 개발에 실용적인 가이드를 제공한다.
상세 분석
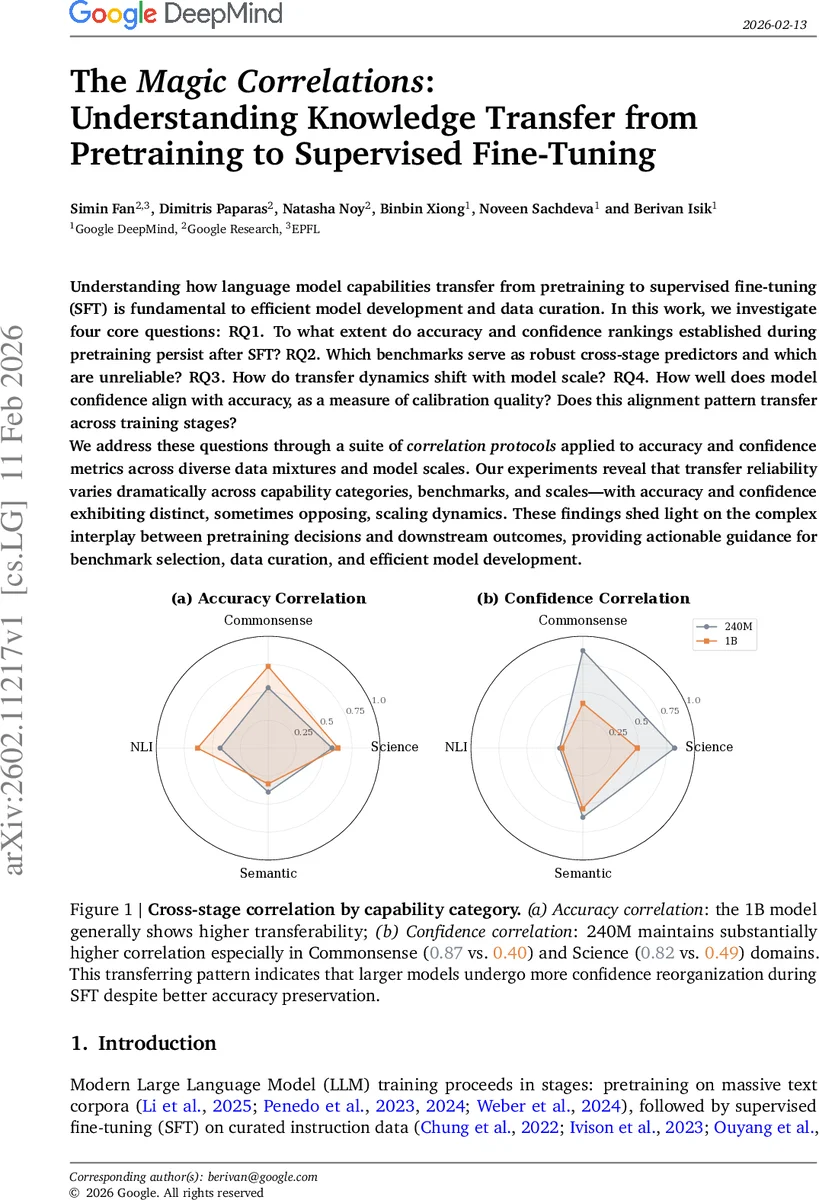
본 연구는 사전학습(Pre‑Training, PT) 단계에서 획득한 모델의 능력이 지도학습 파인튜닝(Supervised Fine‑Tuning, SFT) 후에도 얼마나 일관성을 유지하는지를 정량적으로 파악하기 위해 다섯 가지 상관관계 프로토콜을 설계하였다. 첫 번째 프로토콜인 ‘Cross‑Stage Accuracy Correlation(𝑟_stage_acc)’은 동일 데이터 혼합에 대해 PT와 SFT 정확도 간의 피어슨 상관을 계산한다. 결과는 1B 모델에서 평균 𝑟≈0.59, 240M 모델에서 평균 𝑟≈0.49로, 규모가 클수록 정확도 전이가 더 강함을 보여준다. 반면 ‘Cross‑Stage Confidence Correlation(𝑟_stage_conf)’은 신뢰도 점수의 전이를 측정했을 때, 작은 모델이 평균 𝑟≈0.66으로 큰 모델(𝑟≈0.41)보다 더 높은 일관성을 보였다. 이는 정확도와 신뢰도가 서로 다른 전이 메커니즘을 갖고 있음을 시사한다; 대형 모델은 파인튜닝 과정에서 신뢰도 ‘재조정’이 활발히 일어나지만 정확도는 기존 지식을 그대로 유지한다는 역스케일링 현상이 관찰된다.
두 번째 그룹인 ‘Intra‑Category Correlation’은 동일 능력 카테고리(상식, 과학, NLI, 의미) 내 벤치마크 간의 상관을 세 단계(PT, SFT, Cross‑Stage)로 분석한다. PT 단계에서는 작은 모델이 데이터 혼합에 따라 벤치마크 간 경쟁(음의 상관) 현상이 두드러졌으며, 특히 상식·과학 카테고리에서 서로 다른 태스크가 서로를 억제하는 경향이 있었다. 그러나 1B 모델에서는 SFT 후에 이러한 경쟁이 사라지고, 대부분의 벤치마크 쌍이 양의 상관을 보이며 시너지 효과가 나타났다. 이는 모델 규모가 커질수록 내부 표현이 보다 일반화되어, 하나의 데이터 혼합이 여러 태스크에 동시에 이득을 주는 ‘공통 지식’ 형태로 전이된다는 중요한 통찰을 제공한다.
세 번째 핵심은 ‘Performance‑Confidence Alignment(𝑟_align)’이다. 각 모델‑구성에 대해 정확도와 신뢰도 벡터 간 피어슨 상관을 구해 캘리브레이션 품질을 정량화하였다. 과학 카테고리에서는 𝑟_align≈0.78로 높은 정렬을 보였지만, 상식·의미 이해에서는 𝑟_align≈0.42 수준에 머물며 과대신뢰(over‑confidence)와 언더컨피던스가 지속되었다. 특히 파인튜닝 후에도 이러한 캘리브레이션 불일치는 변하지 않아, SFT 단계에서 별도의 캘리브레이션 절차(예: 온도 스케일링)가 필요함을 암시한다.
데이터 믹스 측면에서는 9가지 조합을 통해 웹·코드·큐레이션 데이터 비율을 변형하였다. ‘FineWeb‑Edu’와 같이 교육용 필터링을 강화한 데이터는 과학 태스크의 정확도를 유지·향상시키는 반면, 신뢰도 정렬은 악화(𝑟_align 감소)되는 패턴을 보였다. 이는 특정 도메인에 특화된 데이터가 해당 도메인 성능을 높이지만, 전반적인 불확실성 추정에는 부정적 영향을 미칠 수 있음을 의미한다.
전체적으로 이 논문은 (1) 정확도와 신뢰도는 서로 다른 스케일링 법칙을 따른다, (2) 벤치마크마다 전이 신뢰도가 크게 다르며, 특히 NLI·의미 이해는 불안정, (3) 모델 규모가 커질수록 intra‑category 경쟁이 사라지고 시너지 효과가 나타난다, (4) 캘리브레이션 정렬은 도메인별 차이가 크며 파인튜닝만으로는 해결되지 않는다, (5) 데이터 커리케이션 전략은 정확도와 캘리브레이션 사이에 트레이드오프가 존재한다는 점을 실증한다. 이러한 발견은 사전학습 단계에서의 벤치마크 선택, 데이터 믹스 설계, 파인튜닝 후 캘리브레이션 절차 등에 실질적인 가이드라인을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기