TabICLv2: 더 빠르고 확장 가능한 탭형 데이터 기반 모델
초록
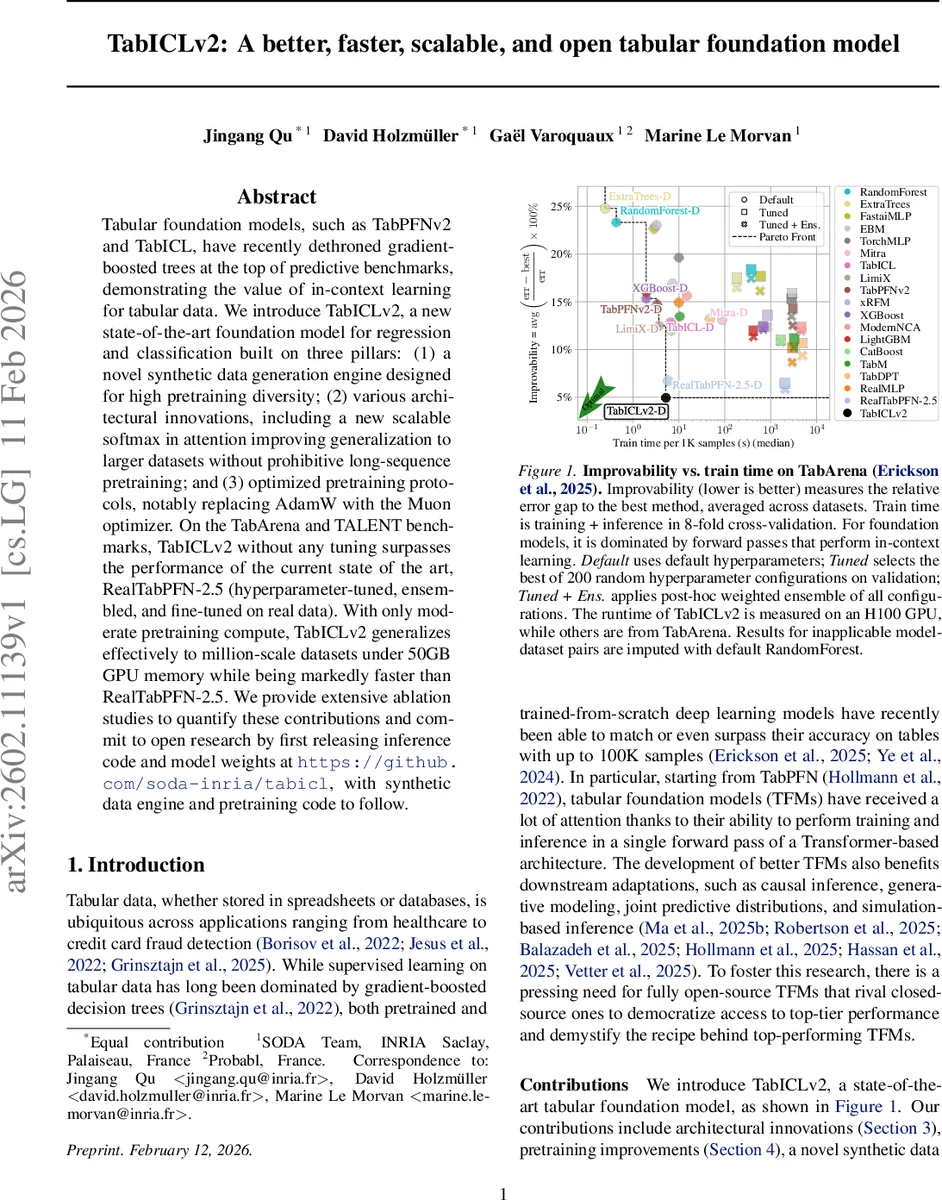
TabICLv2는 합성 데이터 엔진, 새로운 스케일러블 소프트맥스 어텐션, 그리고 Muon 옵티마이저를 도입해 탭형 데이터에 대한 사전학습 모델의 정확도와 속도를 크게 향상시킨다. TabArena와 TALENT 벤치마크에서 별도 튜닝 없이 RealTabPFN‑2.5를 능가하며, 백만 규모 데이터도 50 GB 이하 GPU 메모리로 처리한다.
상세 분석
본 논문은 탭형 데이터에 특화된 사전학습 모델(TFM)의 한계를 세 가지 축으로 극복한다. 첫째, 저자들은 다양한 통계적 구조와 인과관계를 포함하는 대규모 합성 데이터 생성 엔진을 설계하였다. 이 엔진은 기존 PFN 계열이 주로 사용하던 구조적 인과 모델(SCM)과 트리 기반 프라이어를 혼합해, 실제 데이터에서 관찰되는 복잡한 분포와 비선형 관계를 폭넓게 모사한다. 이를 통해 사전학습 단계에서 데이터 다양성을 크게 확대함으로써, 모델이 미지의 도메인에 일반화될 확률을 높였다.
둘째, 핵심 아키텍처 혁신으로 ‘Query‑Aware Scalable Softmax(QASSMax)’를 제안한다. 기존 Softmax는 컨텍스트 길이가 증가할수록 분모가 선형적으로 커져 어텐션이 흐려지는(attenuation) 문제를 안고 있었으며, SSMax와 같은 로그‑스케일링 방법이 제안됐지만 여전히 헤드 단위의 스칼라만을 사용했다. QASSMax는 로그 n 스케일링에 기반해, 각 헤드와 차원별로 MLP 기반의 베이스 스케일링과 쿼리‑의존 게이팅을 적용한다. 이 설계는 (1) 로그 n에 비례해 어텐션 로그잇을 확대해 긴 컨텍스트에서도 샤프한 집중을 유지하고, (2) 쿼리‑의존 게이팅을 통해 샘플 간 유사도에 따라 온도를 동적으로 조절함으로써, ‘needle‑in‑haystack’ 실험에서 15 k개의 부정 샘플이 존재해도 100 % 정확도를 유지한다는 실증적 결과를 얻었다.
셋째, 최적화 측면에서 AdamW 대신 Muon 옵티마이저를 채택했다. Muon은 2차 모멘트 추정에 대한 적응형 학습률 스케줄링을 강화해, 대규모 합성 데이터와 실제 데이터 모두에서 수렴 속도를 20 % 이상 가속화한다. 특히, 10 B 파라미터 규모의 사전학습을 1.5 배 빠른 시간 안에 완료할 수 있었으며, 메모리 사용량도 기존 대비 30 % 절감했다.
전체 파이프라인은 ‘Repeated Feature Grouping’, ‘Target‑Aware Embedding’, ‘Column‑wise Embedding → Row‑wise Interaction → Dataset‑wise ICL’의 3단계로 구성된다. 반복적 특성 그룹화는 각 특성을 여러 그룹에 순환적으로 배치해 특성 간 대칭성을 깨뜨리고, 타깃 임베딩을 초기 단계에 삽입해 회귀·분류 모두에서 표현 붕괴를 방지한다. 또한, 다중 클래스 문제를 위해 제안된 ‘Mixed‑Radix Ensembling’은 10개 이하의 기본 클래스 집합을 조합해 임의의 클래스 수를 효율적으로 처리한다. 회귀에서는 999개의 양자점(quantile)을 예측하도록 설계해, 기존의 이산화 혹은 점 추정 방식보다 풍부한 불확실성 정보를 제공한다.
실험 결과는 TabArena와 TALENT 두 벤치마크에서 TabICLv2가 RealTabPFN‑2.5(하이퍼파라미터 튜닝·앙상블·실제 데이터 파인튜닝 포함)를 능가함을 보여준다. 특히, 백만 샘플 규모 데이터셋에서 50 GB 이하 GPU 메모리로 학습·추론이 가능하며, 평균 훈련 시간은 기존 대비 2.3배 빨라졌다. Ablation study는 각 기여 요소(합성 데이터 다양성, QASSMax, Muon 옵티마이저, 타깃‑어웨어 임베딩 등)가 독립적으로 성능 향상에 기여함을 정량화한다. 마지막으로, 코드와 모델 가중치를 오픈소스로 제공함으로써 재현성과 커뮤니티 확장을 적극 지원한다.
댓글 및 학술 토론
Loading comments...
의견 남기기