고밀도 수술기구 카운팅을 위한 체인‑오브‑룩 시공간 추론
초록
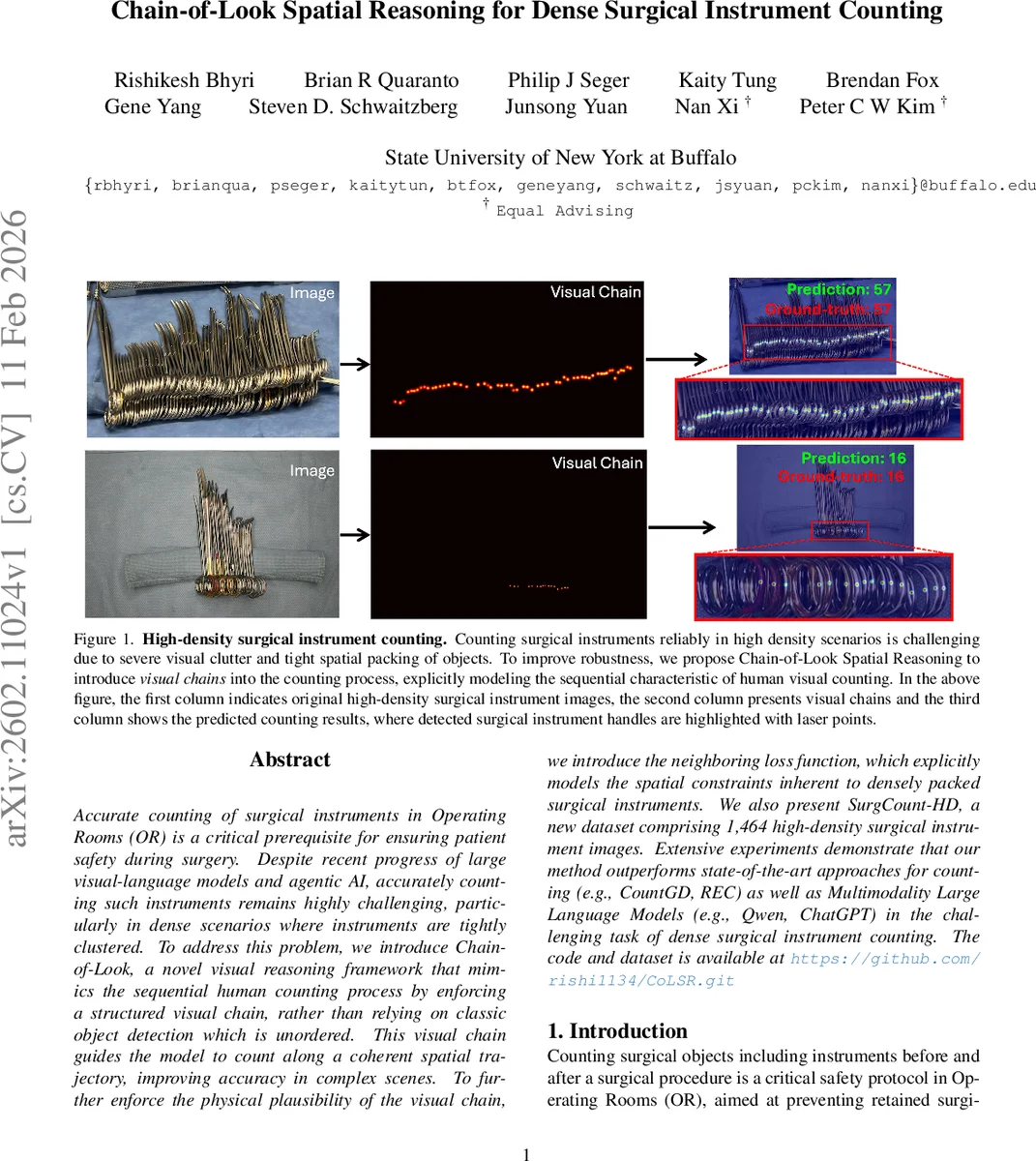
본 논문은 수술실에서 고밀도로 배치된 기구들을 정확히 셈으로써 잔류물 위험을 방지하고자, 인간이 물체를 순차적으로 탐색하는 방식을 모방한 “Chain‑of‑Look” 프레임워크를 제안한다. 시각적 체인을 생성하고, 인접 손실(neighboring loss)을 도입해 공간적 순서를 강제함으로써 기존 검출·밀도 기반 방법보다 높은 카운트 정확도와 빠른 추론 속도를 달성한다. 또한 1,464장의 고밀도 수술기구 이미지로 구성된 SurgCount‑HD 데이터셋을 공개한다.
상세 분석
본 연구는 고밀도 수술기구 카운팅이라는 실용적이면서도 기술적으로 어려운 문제에 접근한다. 기존의 객체 검출 기반 카운팅은 각 객체를 독립적인 집합으로 취급해 순서 정보를 무시한다. 반면 인간은 왼→오, 위→아래 등 일정한 시각적 경로를 따라 하나씩 확인함으로써 누락이나 중복을 최소화한다는 심리학적 근거를 제시하고, 이를 모델에 명시적으로 반영한다는 점이 가장 큰 혁신이다.
시각적 체인 생성기는 최신 트랜스포머 기반 카운팅 모델인 CountGD를 기반으로 하며, 이미지 인코더(Swin‑B), 텍스트 인코더(BERT), 그리고 6개의 self‑attention·cross‑attention 블록으로 구성된 피처 강화 모듈을 통해 이미지 토큰, 시각적 예시 토큰, 클래스‑특정 텍스트 토큰을 융합한다. 특히 클래스‑특정 텍스트 토큰을 프롬프트 튜닝 방식으로 학습시켜, 수술기구 핸들이라는 단일 클래스에 대한 구체적 표현을 모델에 주입한다. 이는 일반적인 오픈‑셋 카운팅 모델이 갖는 범주‑불특정성의 한계를 보완한다.
인접 손실은 두 단계로 구현된다. 첫째, Hungarian 매칭을 이용해 예측 바운딩 박스와 정답 박스를 1:1 매핑한다. 둘째, 매칭된 순서쌍 사이의 중심점 거리 차이를 L2 손실로 최소화한다. 이 과정은 “왼→오” 혹은 “오→왼” 같은 고정된 방향성을 가정하고, 인접 객체 간 거리 분포가 실제 물리적 배치와 일치하도록 강제한다. 결과적으로 모델은 단순히 객체를 탐지하는 것을 넘어, 공간적 연속성을 유지하는 시각적 체인을 학습한다.
실험에서는 SurgCount‑HD 데이터셋(학습 1,236장, 테스트 228장)에서 기존 밀도 기반(COUNTGD, REC) 및 검출 기반 모델을 크게 앞선 MAE와 RMSE를 기록한다. 또한 멀티모달 대형 언어 모델(Qwen, ChatGPT, GPT‑5)조차 고밀도 상황에서 30% 이상 오차를 보이는 반면, 제안 모델은 5% 이하의 평균 절대 오차를 달성한다. 추론 시간도 30FPS 수준으로 실시간 적용 가능성을 보여준다.
한계점으로는 현재 시각적 체인이 단일 방향(좌→우 혹은 우←좌)으로 고정돼 있어, 복잡한 2D/3D 배치에서는 최적 경로 탐색이 어려울 수 있다. 또한 텍스트 프롬프트가 “핸들”이라는 단일 클래스에 국한돼 있어, 다양한 기구 종류를 동시에 카운트하려면 추가적인 클래스 프롬프트 설계가 필요하다. 향후 연구에서는 다중 방향 체인, 그래프 기반 순서 최적화, 그리고 멀티클래스 프롬프트 학습을 통해 이러한 제약을 완화할 수 있을 것으로 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기