테스트‑타임 스케일링을 위한 블록 디퓨전 언어 모델의 적응형 디코딩과 블록 크기 전략
초록
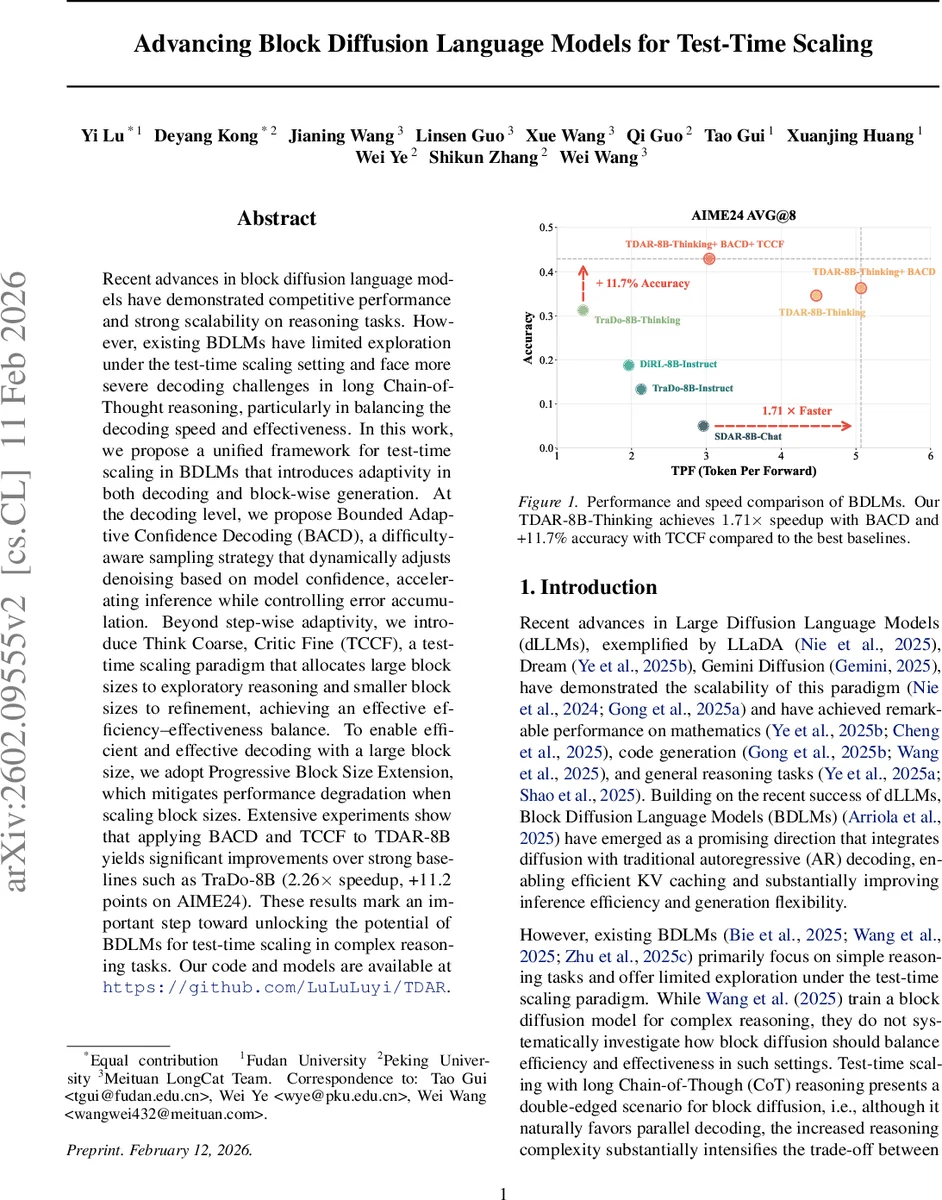
본 논문은 블록 디퓨전 언어 모델(BDLM)의 테스트‑타임 스케일링에서 발생하는 속도‑성능 트레이드오프를 해결하기 위해 두 가지 기법을 제안한다. 첫째, 모델 신뢰도에 기반해 동적으로 디노이징 강도를 조절하는 Bounded Adaptive Confidence Decoding(BACD)를 도입해 추론 속도를 높이면서 오류 축적을 억제한다. 둘째, 추론 과정의 단계별 역할에 따라 큰 블록으로 탐색(Think Coarse)하고 작은 블록으로 정교화(Critic Fine)하는 Think Coarse, Critic Fine(TCCF) 패러다임을 제시한다. 또한 대형 블록 사용 시 성능 저하를 완화하는 Progressive Block Size Extension 기법을 적용한다. 실험 결과, TDAR‑8B에 BACD와 TCCF를 적용했을 때 기존 최강 모델인 TraDo‑8B 대비 2.26배 빠른 추론 속도와 AIME24에서 11.2점 향상을 달성하였다.
상세 분석
본 연구는 블록 디퓨전 언어 모델(BDLM)이 기존 자동회귀(AR) 모델 대비 KV 캐시 효율성과 병렬 디코딩 가능성으로 추론 효율성을 크게 개선할 수 있다는 점을 출발점으로 삼는다. 그러나 긴 Chain‑of‑Thought(CoT) 추론에서는 블록 크기와 디코딩 단계가 성능에 미치는 영향이 복합적으로 작용한다. 큰 블록은 토큰을 한 번에 많이 복원해 속도 이점을 제공하지만, 디노이징 과정에서 오류가 누적될 위험이 있다. 반대로 작은 블록은 정밀한 복원을 가능하게 하지만 단계 수가 늘어나 전체 지연이 증가한다. 이러한 딜레마를 해결하기 위해 저자는 두 차원의 적응성을 설계하였다.
첫 번째 차원은 디코딩 레벨이다. 기존 BDLM은 고정된 신뢰도 임계값(τ) 혹은 정해진 토큰 수(N)만큼을 매 단계 해제하는 정적·동적 전략을 사용한다. 그러나 블록이 커질수록 신뢰도 분포가 넓어져 고정 임계값이 과도하게 보수적이거나 공격적으로 작동한다. BACD는 이전 단계에서 복원된 토큰들의 평균 신뢰도(¯c)를 실시간으로 추적하고, 이를 사전 정의된 상한(τ_h)과 하한(τ_l) 사이에서 클리핑하여 현재 단계의 임계값(τ_t)으로 사용한다. 평균 신뢰도가 높으면 τ_t가 상승해 더 많은 토큰을 한 번에 해제하고, 신뢰도가 낮아지면 τ_t가 하향 조정돼 보수적인 복원을 유지한다. 또한 D_t가 비어 있을 경우 최고 신뢰도 토큰을 강제로 해제해 수렴을 보장한다. 이러한 Bounded Adaptive 메커니즘은 “과도한 보수성”과 “과도한 공격성” 사이의 균형을 자동으로 맞추어, 블록 크기가 커져도 안정적인 품질을 유지하면서 추론 속도를 크게 단축한다.
두 번째 차원은 생성 레벨이다. 저자는 긴 CoT 추론을 “탐색‑정제” 두 단계로 구분한다. 초기 탐색 단계에서는 아이디어를 빠르게 전개하고, 후반 정제 단계에서는 논리적 일관성과 정확성을 검증한다. 이를 반영해 TCCF는 Think Coarse 단계에서 큰 블록(B_think)을 사용해 빠른 탐색을 수행하고, Critic Fine 단계에서는 작은 블록(B_critic < B_think)으로 세밀한 검증·수정을 진행한다. 이때 두 단계는 동일한 모델 파라미터를 공유하지만, 블록 크기만 달라지므로 추가 파라미터 비용이 거의 없다.
큰 블록을 효과적으로 활용하기 위해 Progressive Block Size Extension을 도입한다. 초기 학습은 작은 블록(B=4)으로 시작해, 점진적으로 블록 크기를 16, 32, 64까지 확대한다. 각 단계마다 동일한 SFT 손실을 적용해 모델이 점차 더 큰 컨텍스트를 다루는 능력을 습득하도록 한다. 이렇게 하면 대형 블록에서 발생할 수 있는 “블록 경계 손실”이나 “노이즈 축적” 문제를 완화하고, Think Coarse 단계에서 높은 품질을 유지한다.
실험에서는 8B 규모의 TDAR‑8B 모델을 기반으로, BACD만 적용했을 때 평균 1.88배(3.37배) 속도 향상과 15% 정확도 상승을 기록했다. TCCF를 추가하면 속도는 약간 감소하지만(1.753.04배) 정확도는 AIME24에서 85.6%까지 끌어올렸다. 특히 복합적인 수학·코드·STEM 벤치마크 전반에 걸쳐 기존 BDLM(예: TraDo‑8B‑Thinking) 대비 25% 절대 정확도 향상과 1.3~2.2배 추론 가속을 달성했다.
요약하면, 본 논문은 신뢰도 기반 동적 임계값과 단계별 블록 크기 조절이라는 두 축을 통해 BDLM의 테스트‑타임 스케일링을 실용적인 수준으로 끌어올렸다. 이는 향후 대형 언어 모델이 제한된 연산 자원 하에서도 복잡한 논리 추론을 수행할 수 있는 새로운 설계 패러다임을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기