도시 탐색의 새로운 도전 웹 규모 지식으로 구현한 MLLM 기반 길찾기
초록
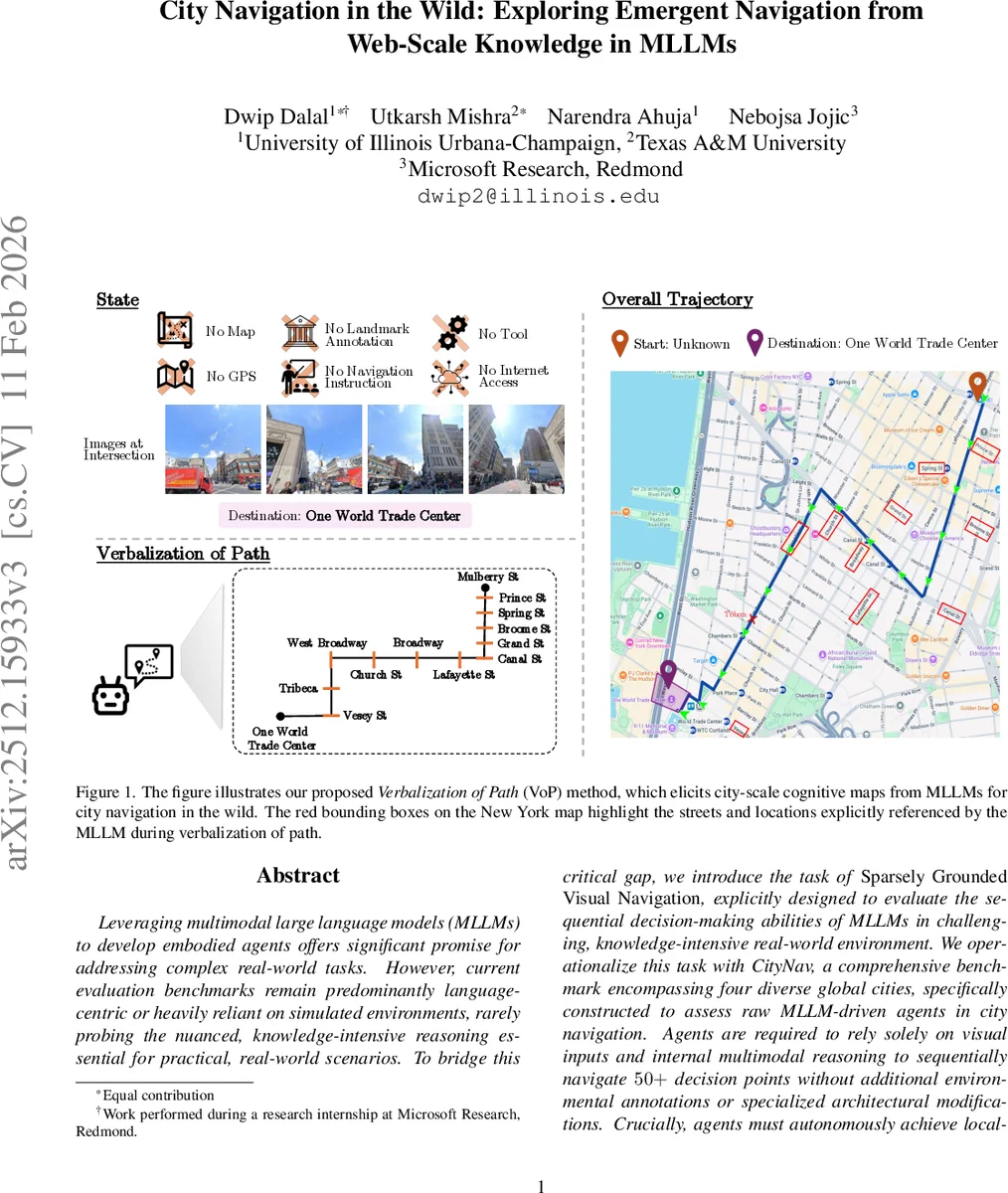
본 논문은 웹‑스케일 멀티모달 대형 언어 모델(MLLM)의 내재된 세계 지식을 활용해, 지도·랜드마크 주석 없이 순수 이미지 입력만으로 실제 도시 거리망을 탐색하도록 설계한 ‘Sparsely Grounded Visual Navigation’ 과제와 CityNav 벤치마크를 제안한다. 기존 실내·시뮬레이션 기반 평가와 달리 2km 이상, 50개 이상의 교차로를 포함하는 4개 글로벌 도시 경로에서 MLLM의 순차적 의사결정 능력을 측정한다. 실험 결과 최신 MLLM과 체인‑오브‑생각·반사 등 정적 추론 기법은 성능이 저조했으며, 저자들은 ‘Verbalization of Path(VoP)’ 라는 프롬프트 기법을 도입해 모델이 도시 규모 인지 지도(주요 랜드마크·방향)를 언어화하도록 유도함으로써 탐색 성공률을 크게 향상시켰다.
상세 분석
이 논문은 멀티모달 대형 언어 모델이 실제 세계에서 ‘자율적인 공간 인지’를 수행할 수 있는지를 검증하기 위해, 기존 연구가 주로 실내 시뮬레이션이나 풍부한 지도·텍스트 지시가 제공되는 환경에 국한된 한계를 명확히 지적한다. 저자들은 ‘Sparsely Grounded Visual Navigation’이라는 새로운 과제를 정의하고, 이를 구현하기 위한 CityNav 데이터셋을 구축한다. CityNav은 뉴욕, 상파울루, 도쿄, 빈 네 개 도시의 실제 스트리트뷰 파노라마를 기반으로 하며, 각 경로는 평균 2km, 50~80개의 교차점, 다국어 표지판 등을 포함한다. 중요한 점은 에이전트가 받는 입력이 교차점에서 촬영된 이미지 집합뿐이며, 지도, GPS, 랜드마크 라벨 등 외부 보조 정보는 전혀 제공되지 않는다. 이는 모델이 내부에 저장된 ‘도시 규모 인지 지도’를 스스로 끌어내어 위치 추정·경로 계획을 해야 함을 의미한다.
기술적으로는 도시 탐색을 부분 관측 마코프 결정 과정(POMDP)으로 공식화한다. 상태는 현재 교차점, 행동은 인접한 거리 세그먼트 선택, 관측은 해당 세그먼트에 대한 이미지이다. 이때 관측은 교차점에 도달했을 때만 제공되므로, 에이전트는 이전 선택과 이미지 기반 추론을 통해 현재 위치를 추정하고 다음 행동을 결정해야 한다.
베이스라인으로는 최신 MLLM(GPT‑4V, LLaVA 등)과 기존 추론 강화 기법(Chain‑of‑Thought, GEPA, Reflection) 그리고 PReP이라는 멀티모달 경로 예측 모델을 적용했지만, 성공률은 10% 이하에 머물렀다. 이는 정적 텍스트 추론이 연속적인 행동 선택과 시각적 피드백을 결합하는 ‘임베디드’ 상황에서는 충분히 작동하지 않음을 보여준다.
이를 극복하기 위해 제안된 Verbalization of Path(VoP)는 두 단계 프롬프트 전략이다. 첫 단계에서 모델에게 현재 목표까지의 ‘주요 랜드마크와 방향’을 언어화하도록 요구하고, 두 번째 단계에서는 이 언어화된 경로 정보를 기반으로 다음 행동을 선택한다. 즉, 모델 내부에 존재하는 도시 규모 인지 지도를 명시적으로 꺼내어 ‘경로 메모리’로 활용한다. 실험 결과, VoP를 적용한 에이전트는 성공률이 3배 이상 상승했으며, 특히 복잡한 교차로와 언어적 장벽(예: 일본어 표지판)에서 눈에 띄는 개선을 보였다.
또한, 저자들은 그래프 전처리 단계에서 죽은 끝(dead‑end)과 비대칭 연결을 정리하고, 탐색 시 온도 파라미터와 재방문 페널티를 조절해 루프를 방지하는 등 실용적인 엔지니어링 기법도 상세히 제시한다. 한계점으로는 현재 모델이 여전히 시각적 노이즈와 급격한 시점 전환에 취약하며, 장거리 경로에서 누적 오류가 발생한다는 점을 인정한다. 향후 연구에서는 더 정교한 메모리 구조와 외부 도구(지도 API 등)와의 연동, 그리고 실제 로봇 플랫폼에의 적용을 제안한다.
전반적으로 이 논문은 ‘멀티모달 언어 모델이 내재한 세계 지식을 어떻게 실제 행동으로 전환할 수 있는가’라는 근본적인 질문에 대한 실증적 답을 제공하며, 도시 수준의 복합 환경에서 MLLM 기반 에이전트를 평가·향상시키는 새로운 패러다임을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기