스트리밍 비디오 LLM을 위한 계층형 토큰 압축 가속기
초록
본 논문은 실시간 스트리밍 비디오 이해에서 가장 큰 병목인 Vision Transformer(ViT) 인코딩과 LLM 프리필 단계의 비용을 동시에 낮추는 플러그인‑형 프레임워크 STC를 제안한다. STC는 시간적으로 중복된 프레임을 캐시해 재사용하는 STC‑Cacher와, 시공간적 중요도에 따라 시각 토큰을 압축하는 STC‑Pruner 두 모듈로 구성된다. 네 가지 베이스라인 VideoLLM에 적용한 실험에서 ReKV 기준 99% 정확도를 유지하면서 ViT 인코딩 지연을 24.5%, LLM 프리필 지연을 45.3% 감소시켰다.
상세 분석
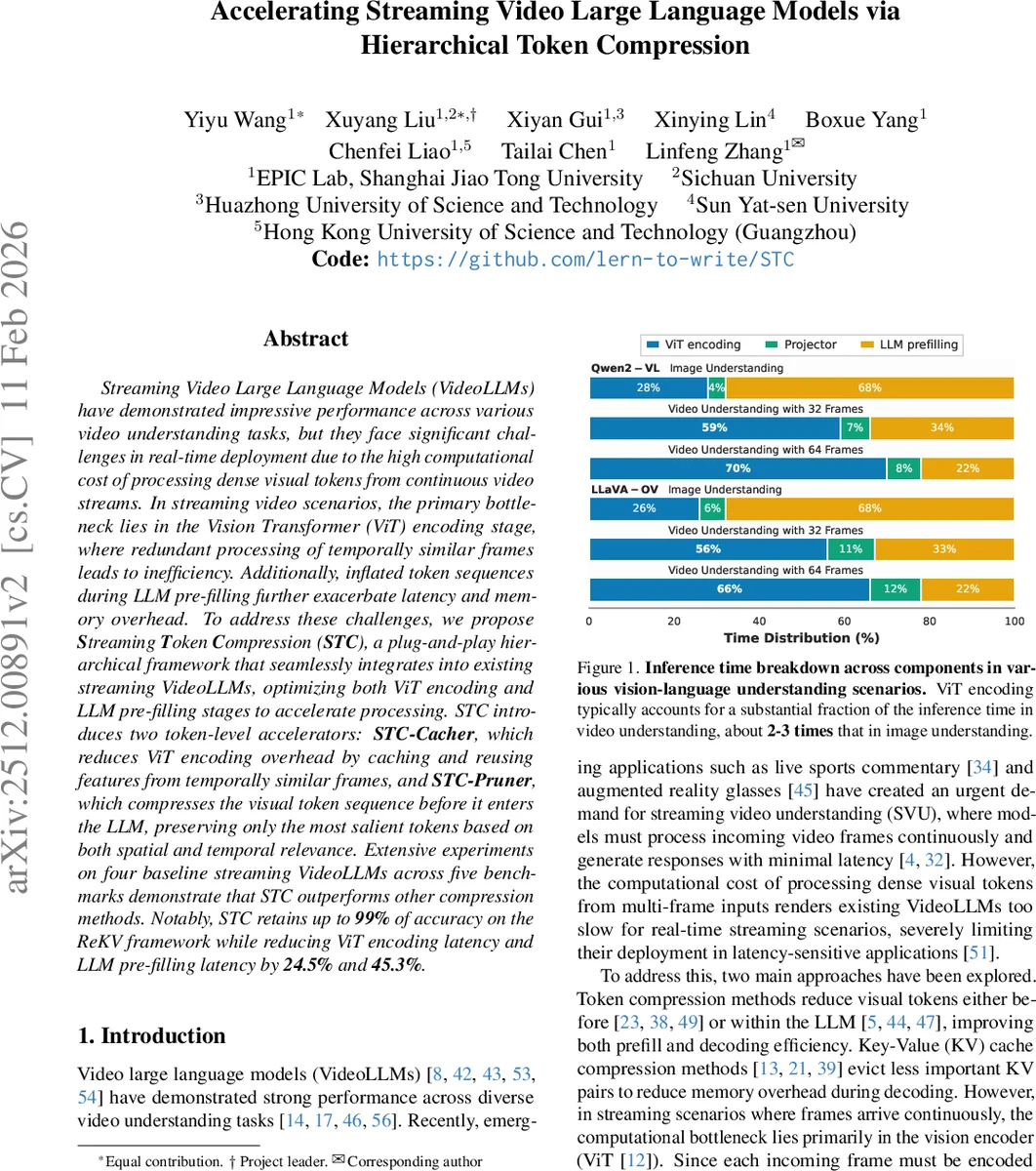
STC는 스트리밍 비디오 상황에서 “시간적 중복”과 “긴 컨텍스트 중복”이라는 두 가지 핵심 병목을 정확히 짚어낸다. 첫 번째 병목은 연속 프레임이 거의 동일한 시각 정보를 담고 있음에도 매 프레임마다 전체 ViT를 수행해야 하는 점이다. 저자는 프레임을 ‘레퍼런스 프레임’과 ‘비레퍼런스 프레임’으로 구분하고, 레퍼런스 프레임에서 얻은 키·밸류(K,V)와 어텐션 매트릭스를 캐시한다. 비레퍼런스 프레임이 들어오면 현재 프레임의 키 벡터와 캐시된 레퍼런스 키 벡터 사이의 코사인 유사도를 계산해 정적 토큰을 식별하고, 이 토큰에 대해서는 재계산을 건너뛴다. 동적 토큰만을 대상으로 Query와 Value만 새로 계산하고, 기존 캐시된 Key와 Value와 결합해 저차원 어텐션 업데이트를 수행한다. 이렇게 하면 전체 연산량이 크게 감소하면서도 시각적 변화를 놓치지 않는다.
두 번째 병목은 LLM 프리필 단계에서 발생한다. 스트리밍 비디오가 길어질수록 시각 토큰 수가 기하급수적으로 늘어나고, 이는 self‑attention의 O(N²) 복잡도와 KV 캐시 메모리 사용량을 급격히 증가시킨다. STC‑Pruner는 ViT 인코딩 직후 토큰들을 시공간적 중요도 점수에 따라 정렬하고, 정적 배경이나 저정보 영역을 제거한다. 중요도 평가는 (1) 토큰 자체의 활성도, (2) 인접 프레임과의 유사도, (3) 현재 프롬프트와의 연관성을 고려한 가중합으로 이루어진다. Pruner는 사전‑학습된 경량 네트워크를 사용해 실시간으로 토큰을 스코어링하고, 사전에 정의된 압축 비율(예: 30%~50%)에 따라 상위 토큰만 LLM에 전달한다.
STC의 설계는 완전한 플러그인 방식이다. 기존 ViT‑LLM 파이프라인에 최소한의 인터페이스만 추가하면 되며, 레퍼런스 프레임 선택 주기(N)와 재사용 비율(R_Cacher), Pruner의 압축 비율 등은 하이퍼파라미터로 쉽게 조정 가능하다. 실험에서는 N=4, R_Cacher=75% 등 다양한 설정을 시험했으며, 특히 ReKV와 같은 KV‑cache 기반 스트리밍 모델에 적용했을 때 정확도 손실이 거의 없었다. 이는 STC가 “시간적 인과성”을 유지하면서도 중복을 효과적으로 제거한다는 증거다.
또한 저자는 기존 토큰 압축 기법과 비교했을 때 STC가 두 단계(ViT와 LLM) 모두에서 이득을 얻는 점을 강조한다. 예를 들어, ToMe와 같은 ViT 내부 토큰 병합 기법은 인코딩 단계는 가속하지만 LLM 입력 길이를 줄이지 못한다. 반대로 KV‑cache 압축은 메모리 사용량만 감소시킬 뿐 인코딩 비용을 해결하지 못한다. STC는 이러한 한계를 극복하고, 전체 파이프라인의 지연을 30% 이상 절감한다.
마지막으로, 저자는 STC가 “인스트럭션‑불가지” 상황에서도 작동한다는 점을 강조한다. 스트리밍에서는 사용자 질의가 프레임 이후에 도착하기 때문에 사전‑질의 기반 토큰 선택이 불가능하다. STC‑Cacher와 STC‑Pruner는 모두 현재 프레임과 과거 캐시만을 이용해 결정하므로, 미래 정보를 전혀 사용하지 않는다. 이는 실시간 AR 안경, 라이브 스포츠 해설 등 지연이 중요한 응용 분야에 바로 적용할 수 있음을 의미한다.
댓글 및 학술 토론
Loading comments...
의견 남기기