그룹 디퓨전 정책 최적화를 통한 확산 언어 모델 추론 향상
안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
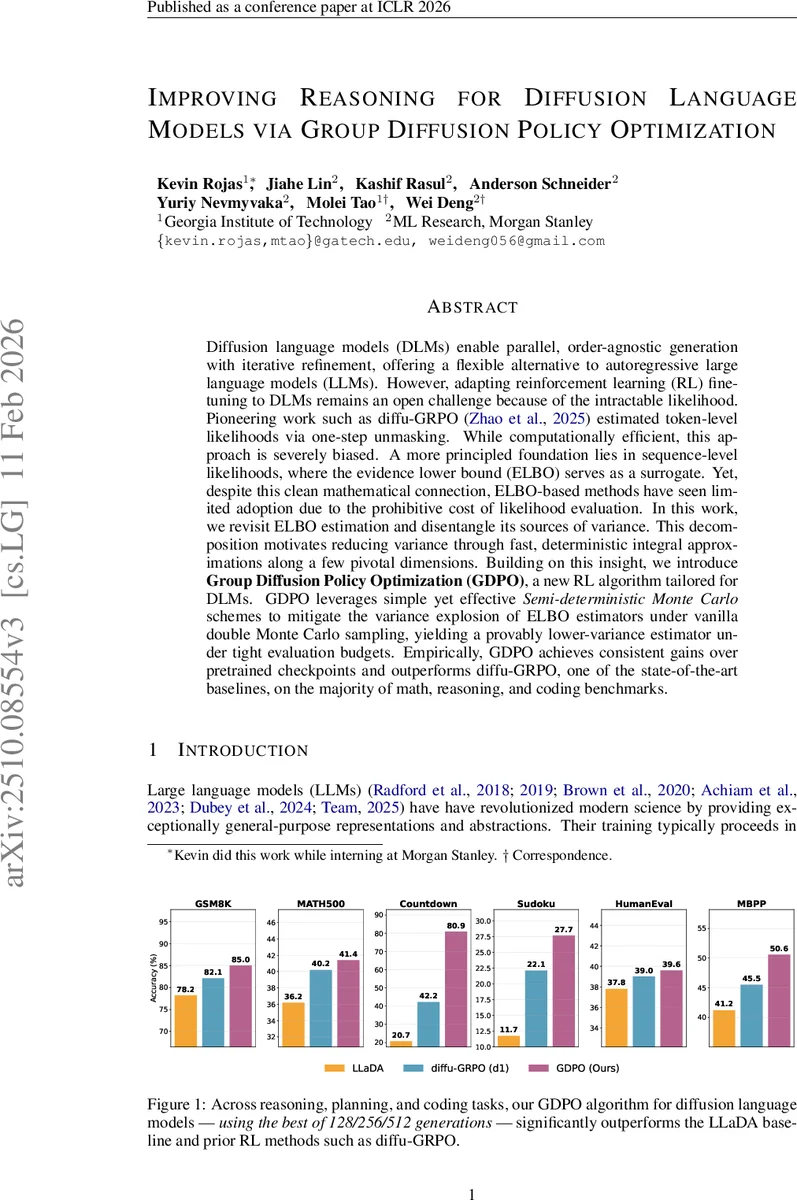
본 논문은 확산 언어 모델(DLM)의 순차적 로그우도 계산이 어려운 문제를 ELBO 기반 추정으로 해결하고, 시간 차원을 결정론적으로 처리한 반결정적 몬테카를로(SDMC) 기법을 도입한다. 이를 바탕으로 제안된 그룹 디퓨전 정책 최적화(GDPO) 알고리즘은 기존 diffu‑GRPO 대비 편향을 크게 줄이며, 수학·추론·코딩 벤치마크에서 일관된 성능 향상을 보인다.
상세 분석
확산 언어 모델(DLM)은 마스크 기반의 순차적 복원 과정을 통해 토큰을 동시에 생성하거나 반복적으로 수정할 수 있어, 전통적인 자동회귀 LLM이 갖는 순차적 제약을 극복한다. 그러나 RL 기반 파인튜닝을 적용하려면 정책의 로그우도 πθ(y|q)를 정확히 평가해야 하는데, DLM에서는 마스크 단계가 시간(t)에 따라 변하고 토큰 순서가 고정되지 않아 직접적인 시퀀스‑레벨 우도 계산이 불가능하다. 기존 연구인 diffu‑GRPO는 “one‑step unmasking”을 이용해 토큰‑레벨 우도를 근사했지만, 이는 마스크된 토큰 간의 상관관계를 무시해 심각한 편향을 초래한다.
논문은 이러한 문제를 근본적으로 해결하기 위해 ELBO를 로그우도의 하한으로 활용한다. ELBO는
\
댓글 및 학술 토론
Loading comments...
의견 남기기