오픈월드 딥페이크 음성 탐지를 위한 대규모 데이터셋 AUDETER 소개
초록
AUDETER는 11개의 최신 TTS 모델과 10개의 최신 보코더를 활용해 4,500시간 이상, 3백만 개의 클립을 제공하는 대규모 딥페이크 음성 데이터셋이다. 기존 데이터셋의 한계를 극복하고, 합성 음성의 다양성을 균형 있게 포함함으로써 열린 세계(open‑world) 상황에서의 탐지 성능을 평가·향상시킬 수 있다. 또한, 합성 소스 간의 부정적 전이(negative transfer)를 완화하기 위한 커리큘럼 학습 기법을 제안한다.
상세 분석
AUDETER는 현재 딥페이크 음성 탐지 연구에서 가장 큰 규모와 다양성을 갖춘 데이터셋으로, 4,682시간에 달하는 합성 음성을 21개의 서로 다른 합성 파이프라인(11개 TTS 모델 + 10개 보코더)으로 생성하였다. 특히 각 실제 음성 샘플에 대해 21개의 합성 버전을 일대일 매칭시켜 제공함으로써, 모델이 특정 합성 패턴에 과도하게 의존하는 현상을 방지하고, 시스템 전반에 걸친 일반화 능력을 정량적으로 측정할 수 있다.
데이터셋 구성은 네 개의 실제 음성 소스(셀러브리티, 크라우드소스, 미국 의회, 오디오북)로 나뉘며, 각각의 소스는 훈련·검증·테스트 세트로 구분된다. 이는 실제 음성의 발화 스타일, 억양, 배경 잡음 등 다양한 변이를 포함하도록 설계되었으며, 기존 ASVspoof 시리즈나 In‑the‑Wild과 비교했을 때 스크립트 일치율, 화자 다양성, 합성 모델 최신성 면에서 현저히 우수하다.
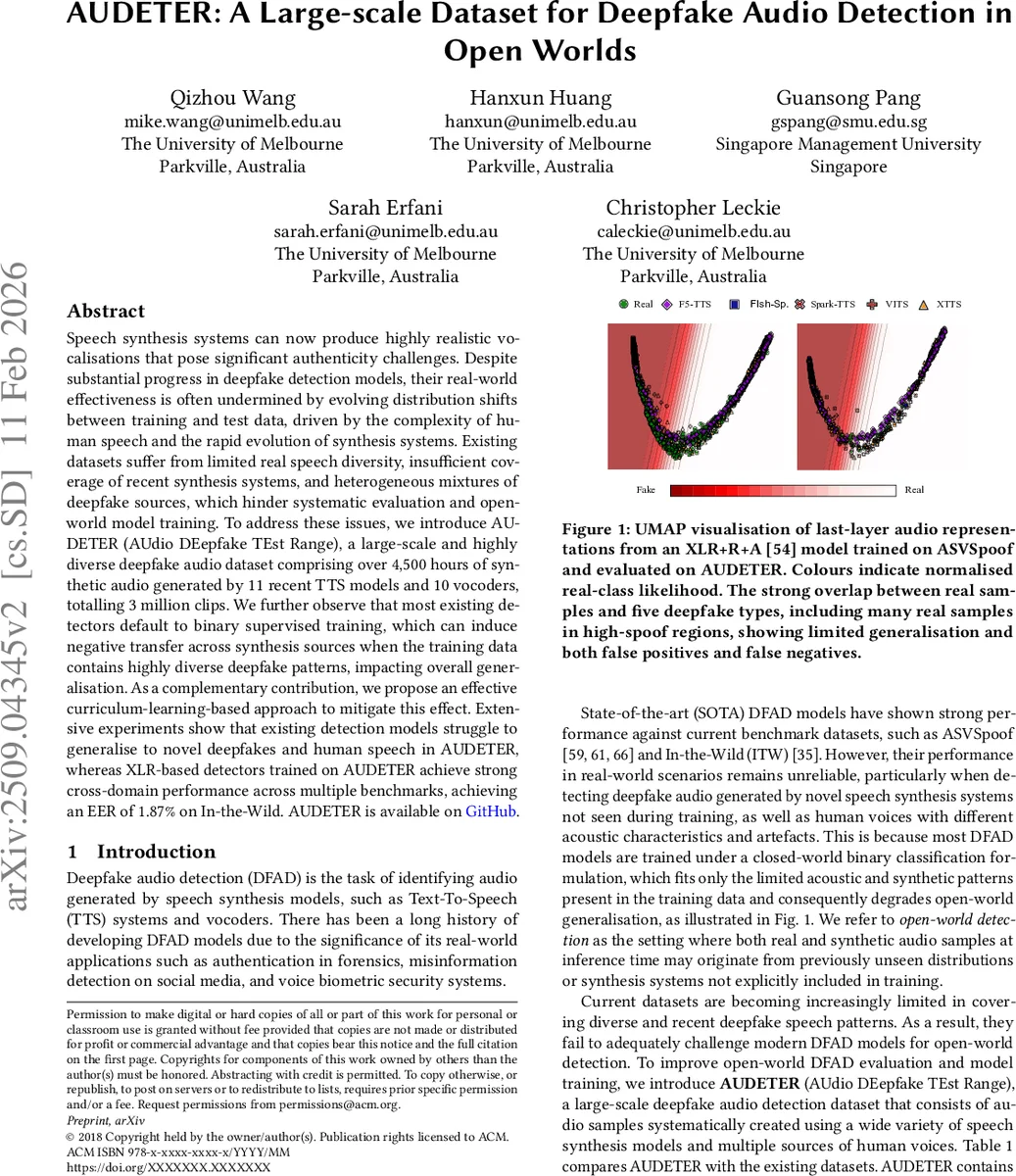
논문은 기존 탐지 모델이 “이진 폐쇄형(binary closed‑world)” 학습 방식에 의존할 경우, 다양한 합성 소스가 섞인 훈련 데이터에서 부정적 전이가 발생해 교차 도메인 성능이 급격히 저하된다는 문제를 실험적으로 확인한다. 이를 해결하기 위해 두 단계 커리큘럼 학습을 제안한다. 1단계에서는 합성 지문이 강하게 나타나는 모델을 선별하고, 이를 제외한 데이터만으로 기본 탐지기를 학습해 시스템‑불변적인 특징을 추출한다. 2단계에서는 전체 합성 데이터를 사용해 모델을 미세조정하되, 1단계에서 학습된 백본을 교사(teacher) 모델로 활용해 정규화 손실을 추가함으로써 기존의 강한 합성 패턴이 모델을 지배하지 못하도록 한다.
실험 결과, AUDETER로 사전 학습된 XLR‑SLS 기반 탐지기는 In‑the‑Wild 테스트에서 EER 1.87%를 기록했으며, 기존 ASVspoof·In‑the‑Wild·WaveFake 등 외부 벤치마크에 대해서도 현저히 낮은 EER을 달성했다. 특히, 잡음이 섞인 환경에서도 기존 모델 대비 30% 이상 향상된 견고성을 보였다. 커리큘럼 학습을 적용한 모델은 동일 데이터셋에서도 교차 도메인 평균 EER을 12%p 이상 감소시켰으며, 특정 합성 시스템에 과도하게 편향되는 현상이 크게 완화되었다.
이러한 결과는 (1) 대규모·다양한 합성 데이터가 필요함을, (2) 합성 소스 간 차이를 명시적으로 모델링하지 않을 경우 부정적 전이가 발생함을, (3) 커리큘럼 학습이 시스템‑불변 특징을 강화해 열린 세계 탐지 성능을 크게 높일 수 있음을 시사한다. 앞으로 AUDETER는 데이터 중심 접근법을 통한 딥페이크 음성 탐지 연구의 표준 벤치마크로 자리매김할 가능성이 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기