GenDR 생성적 디테일 복원 경량화
초록
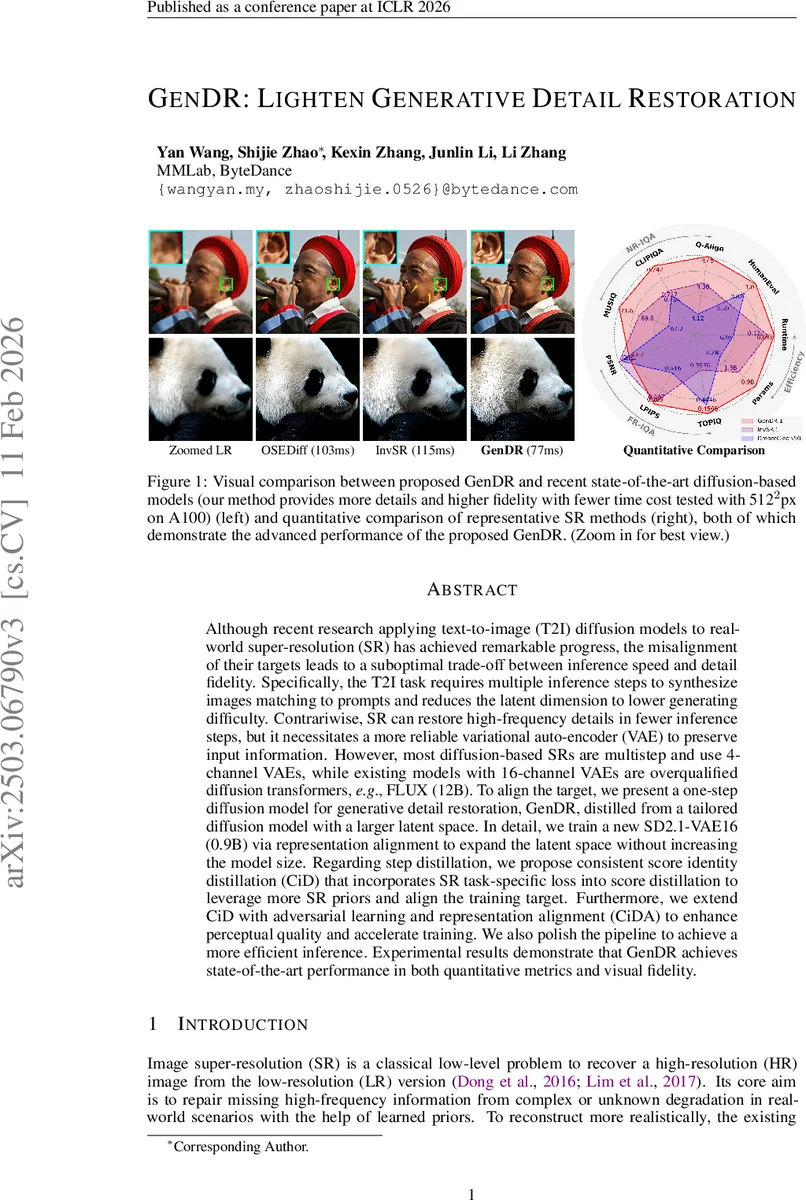
GenDR은 16채널 VAE와 일단계 확산 모델을 결합해 실시간 초고해상도 복원을 구현한다. 기존 다단계 확산 기반 SR이 속도와 디테일 사이에서 겪던 트레이드오프를 일관성 점수 정체(distillation)와 adversarial 학습을 통해 해소하고, 77 ms 안에 512×512 이미지 복원을 달성한다.
상세 분석
본 논문은 텍스트‑투‑이미지(T2I) 확산 모델이 고해상도 이미지 생성에 강점을 보이지만, SR(슈퍼레졸루션) 과제와는 목표가 다르다는 점을 정확히 짚어낸다. T2I는 텍스트와 이미지 의미를 동시에 학습하기 위해 다수의 디퓨전 스텝과 저차원(latent) 압축을 필요로 하는 반면, SR은 저해상도(LR) 이미지의 구조적 정보를 그대로 보존하면서 고주파 디테일만을 보강하면 된다. 따라서 SR에 4채널 VAE를 그대로 적용하면 latent 압축률이 높아 세밀한 디테일이 손실되고, 다단계 디퓨전은 추론 시간을 크게 늘린다.
이 문제를 해결하기 위해 저자들은 두 가지 핵심 설계를 제안한다. 첫째, SD2.1 기반의 16채널 VAE(SD2.1‑VAE16)를 새롭게 학습시켜 latent 차원을 확대하면서도 모델 파라미터 수는 0.9 B로 기존과 동등하게 유지한다. Representation Alignment(RepA) 손실을 이용해 사전학습된 이미지 인코더(DINOv2)와의 특징 정렬을 강제함으로써 고차원 latent에서도 정보 손실을 최소화한다. 둘째, 일단계 디퓨전으로 압축하기 위한 Consistent Score Identity Distillation(CiD)와 그 확장형 CiDA를 도입한다. 기존 Score Distillation(SDS)이나 Variational Score Distillation(VSD)은 T2I 전용으로 설계돼 SR에 적용하면 가짜 점수(fake score)와 실제 점수(real score) 사이의 불일치가 학습 불안정을 초래한다. CiD는 SR 전용 손실(L1, MSE)과 결합해 가짜 점수의 목표를 “z_h”(HR latent)와 일치하도록 강제하고, 시간 가중치 ω(t)와 classifier‑free guidance(CFG)를 통해 고품질 프라이어를 제공한다.
CiDA는 여기서 adversarial loss와 RepA를 추가해 두 가지 효과를 얻는다. adversarial loss는 생성된 latent이 사전학습된 UNet 디스크리미네이터를 속이도록 유도해 시각적 다양성과 사실성을 높이며, RepA는 학습 과정에서 이미지 수준의 의미 일관성을 지속적으로 보강한다. 또한 LoRA(Low‑Rank Adaptation)를 활용해 가짜·실제 점수 네트워크와 디스크리미네이터의 파라미터를 효율적으로 공유·축소함으로써 GPU 메모리 사용량을 크게 낮춘다.
파이프라인 측면에서는 텍스트 프롬프트와 스케줄러를 완전히 제거하고 고정된 임베딩만을 사용해 UNet과 VAE만으로 구성한다. 이로써 추론 시 추가적인 컨트롤넷이나 전처리 모듈이 필요 없으며, A100 GPU에서 512×512 입력을 77 ms에 처리한다. 실험 결과는 PSNR/SSIM, LPIPS, FID 등 정량 지표에서 기존 최첨단 모델(OSEDiff, DreamClear 등)을 모두 앞서며, 인간 평가에서도 시각적 선호도가 가장 높았다.
요약하면, GenDR은 (1) 고차원 16채널 VAE를 통한 풍부한 latent 표현, (2) SR 특화 일관성 점수 정체(CiD/CiDA)와 adversarial 정규화, (3) LoRA 기반 파라미터 효율화, (4) 불필요한 조건부 모듈 제거라는 네 가지 설계 축을 결합해 속도와 디테일 사이의 전통적 트레이드오프를 깨뜨렸다. 이는 실시간 고품질 이미지 복원, 특히 모바일·임베디드 환경에서의 적용 가능성을 크게 확대한다.
댓글 및 학술 토론
Loading comments...
의견 남기기