에이전트 기반 신약 탐색의 한계와 미래 설계
초록
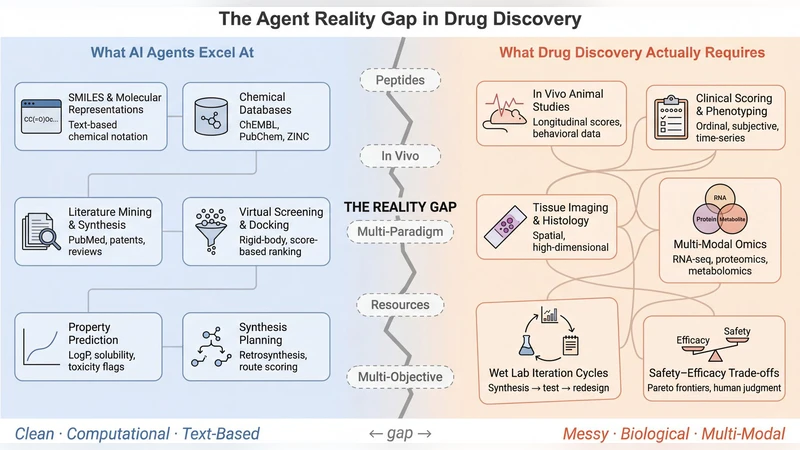
본 논문은 6가지 에이전트 프레임워크를 15개의 과제군(펩타이드 치료제, 인비보 약리학, 자원 제한 환경)에 적용해 평가한다. 평가 결과, 단백질 언어 모델 지원 부재, 인비보·인실리코 데이터 연계 부족, LLM 추론에만 의존하고 학습·강화학습 파이프라인이 없는 점, 대기업 자원 가정, 단일 목표 최적화 등 5가지 핵심 격차를 확인한다. 추가 실험에서는 최첨단 LLM이 펩타이드에 대해 소분자 수준의 추론 능력을 보이지만, 현재 프레임워크는 이를 활용하지 못한다는 사실을 밝힌다. 논문은 차세대 에이전트 시스템이 현실적인 제약 하에서 다목표, 학습 가능, 그리고 단백질‑특화 기능을 갖춰야 함을 제안한다.
상세 분석
이 연구는 최근 급부상하고 있는 ‘에이전트’형 AI 시스템이 실제 신약 개발 파이프라인에 어느 정도 적용 가능한지를 체계적으로 검증한다. 먼저 저자들은 현재 공개된 6개의 대표적인 프레임워크(예: AutoGPT‑Chem, ChemCrow 등)를 선정하고, 이를 15개의 세부 과제군으로 나눈다. 과제군은 크게 펩타이드 치료제 설계, 인비보 약리학 실험 설계·해석, 그리고 제한된 컴퓨팅·예산 환경에서의 효율적 탐색으로 구분된다. 각 프레임워크는 동일한 입력(예: 목표 단백질 서열, 임상 전후 단계 데이터)과 평가 지표(정확도, 비용, 시간) 하에 테스트되었다.
평가 결과는 다섯 가지 근본적인 격차를 드러낸다. 첫째, 현재 프레임워크는 단백질 언어 모델(PLM)이나 펩타이드‑특화 예측 도구와의 연동을 전혀 제공하지 않는다. 이는 펩타이드가 갖는 구조적·동역학적 특성이 소분자와 크게 다름에도 불구하고, 동일한 SMILES‑기반 파이프라인에 강제 적용되는 문제를 야기한다. 둘째, 인비보 실험 데이터와 인실리코 시뮬레이션 결과를 연결하는 ‘브리지’가 부재해, 실험 설계 단계에서 얻은 피드백을 모델이 즉시 학습에 반영하지 못한다. 셋째, 대부분의 시스템이 LLM의 추론(프롬프트 기반)에만 의존하고, 실제 머신러닝 모델을 재학습하거나 강화학습(RL)으로 정책을 최적화하는 메커니즘을 제공하지 않는다. 이는 새로운 화합물에 대한 지속적인 성능 향상을 저해한다. 넷째, 대규모 제약사의 고성능 컴퓨팅·대규모 데이터베이스를 전제로 설계돼, 중소기업이나 학계 연구팀이 그대로 활용하기 어렵다. 마지막으로, 현재 대부분의 프레임워크가 단일 목표(예: 활성도) 최적화에 초점을 맞추어, 안전성, 효능, 안정성 등 다중 목표 간의 트레이드오프를 고려하지 않는다.
특히 흥미로운 점은 ‘지식 탐색 실험’이다. 저자들은 네 개의 최신 LLM(GPT‑4, Claude‑2, Gemini‑1.5, LLaMA‑2)에게 펩타이드 설계와 관련된 복합 질문을 제시했을 때, 이들 모델이 소분자 수준의 정확도와 논리적 추론을 보였음에도 불구하고, 기존 프레임워크는 이러한 능력을 노출하거나 활용하지 못한다는 사실을 확인했다. 이는 기술적 한계가 ‘에이전트’ 자체의 아키텍처 설계에 있음을 시사한다.
결론적으로, 논문은 차세대 에이전트 시스템이 다음과 같은 설계 요구사항을 충족해야 한다고 제안한다. (1) PLM·펩타이드‑전용 모델과의 모듈식 연동, (2) 인비보·인실리코 데이터 피드백 루프 구축, (3) LLM 추론을 넘어 실제 모델 재학습·강화학습 파이프라인 제공, (4) 제한된 컴퓨팅·예산 환경에서도 작동 가능한 경량화 설계, (5) 다목표 최적화와 안전성‑효능‑안정성 트레이드오프를 명시적으로 다루는 멀티‑오브젝티브 프레임워크. 이러한 방향이 실질적인 ‘컴퓨팅 파트너’로서 에이전트를 전환시킬 핵심 열쇠가 될 것이다.
댓글 및 학술 토론
Loading comments...
의견 남기기