낙관적 세계 모델로 탐색 효율 극대화
초록
본 논문은 희소 보상 환경에서의 탐색 문제를 해결하기 위해 고전적인 보상 편향 최대우도 추정(RBMLE)을 딥 모델 기반 강화학습에 도입한 ‘Optimistic World Models(OWM)’ 프레임워크를 제안한다. 기존 UCB 기반 방법이 요구하는 불확실성 추정과 비선형 제약을 없애고, 모델 학습 단계에 낙관적 역학 손실을 추가함으로써 상상(imagination) 트랜지션을 보상 높은 방향으로 편향시킨다. OWM을 DreamerV3와 STORM에 적용한 ‘Optimistic DreamerV3’와 ‘Optimistic STORM’은 희소 보상 Atari와 DMC 벤치마크에서 샘플 효율과 누적 보상이 크게 향상됨을 실험적으로 입증한다.
상세 분석
OWM은 모델 기반 강화학습(MBRL)에서 ‘확신 등가 원리(certainty equivalence)’가 초래하는 폐쇄‑루프 식별 문제를 근본적으로 완화한다. 전통적인 MLE는 실제 데이터에만 맞추어 모델을 학습하고, 그 모델을 기반으로 정책을 최적화하지만, 식별 조건이 만족되지 않을 경우 최적이 아닌 서브‑옵티멀 정책에 수렴한다. 이를 극복하기 위해 고전 제어 이론에서 제시된 RBMLE는 로그우도에 보상 기대값을 가중치 α(t)와 함께 더해 모델 파라미터를 보상 높은 방향으로 편향한다. 논문은 이 원리를 딥 뉴럴 네트워크에 적용하기 위해 두 단계의 그래디언트 추정을 제시한다. 첫째, 실제 리플레이 버퍼 D_t에 대한 로그우도 손실을 그대로 유지한다. 둘째, 현재 정책 π_θ를 모델 p_ϕ 위에서 시뮬레이션해 생성한 상상 트랜지션 τ_i에 대해 보상 R(τ_i)을 가중치로 하는 ‘낙관적 역학 손실’ L_opt을 정의한다. L_opt은 −α(t)·(1/L)∑ℓ A_ℓ·log p_ϕ(s{ℓ+1}|s_ℓ,a_ℓ)−η·(1/L)∑_ℓ H(p_ϕ(·|s_ℓ,a_ℓ)) 형태이며, 여기서 A_ℓ는 가치 네트워크로부터 계산된 어드밴티지, H는 엔트로피 정규화이다. 이 손실은 정책 그래디언트의 구조와 동일하게 설계돼 기존 Dreamer·STORM 파이프라인에 최소한의 코드 수정만으로 삽입 가능하다.
α(t)의 설계는 두 가지 수렴 조건 lim_{t→∞} t·α(t)=∞와 lim_{t→∞} α(t)=0를 만족하도록 스케줄링한다. 초기 학습 단계에서는 큰 α가 모델을 적극적으로 낙관적으로 만들며, 학습이 진행될수록 α가 감소해 실제 데이터에 대한 정확도와 균형을 맞춘다. 이렇게 하면 초기 탐색 효율이 크게 향상되고, 장기적으로는 정확한 모델 수렴을 보장한다.
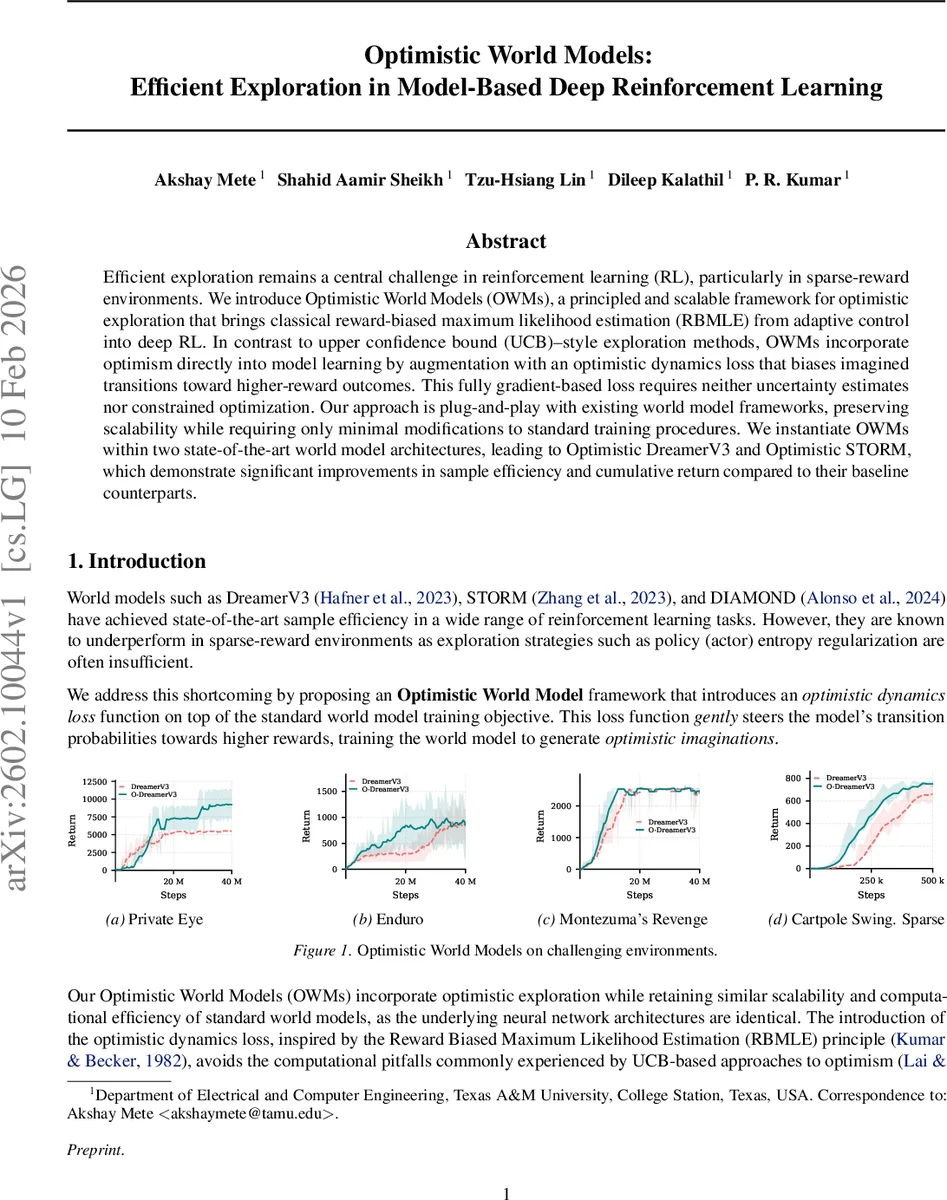
실험에서는 Optimistic DreamerV3와 Optimistic STORM을 각각 DreamerV3와 STORM에 그대로 적용한 뒤, Atari100K, DMC(DeepMind Control Suite) 및 다양한 희소 보상 환경(Private Eye, Cartpole Swing‑up Sparse 등)에서 비교하였다. 결과는 평균 인간 정규화 점수(HNS)가 152.68%에 달해 기존 DreamerV3(97.45%) 대비 55% 이상 상승했으며, 특히 보상이 거의 없는 초기 단계에서의 탐색 성공률이 크게 개선되었다. 또한 계산 비용은 기존 모델과 거의 동일했으며, 추가적인 불확실성 추정 모듈이나 복잡한 제약 최적화가 필요 없다는 점에서 실용성이 강조된다.
이 논문은 (1) RBMLE를 딥 MBRL에 그래디언트 기반으로 구현한 최초 사례, (2) 낙관적 역학 손실을 통해 탐색‑활용 트레이드오프를 자연스럽게 해결한 점, (3) 기존 세계 모델 아키텍처와의 높은 호환성을 입증한 점에서 의미가 크다. 향후 연구는 α(t) 스케줄링을 메타‑러닝으로 자동화하거나, 다중 목표 환경에서 보상 구조를 동적으로 조정하는 방법을 탐색할 여지를 남긴다.
댓글 및 학술 토론
Loading comments...
의견 남기기