안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
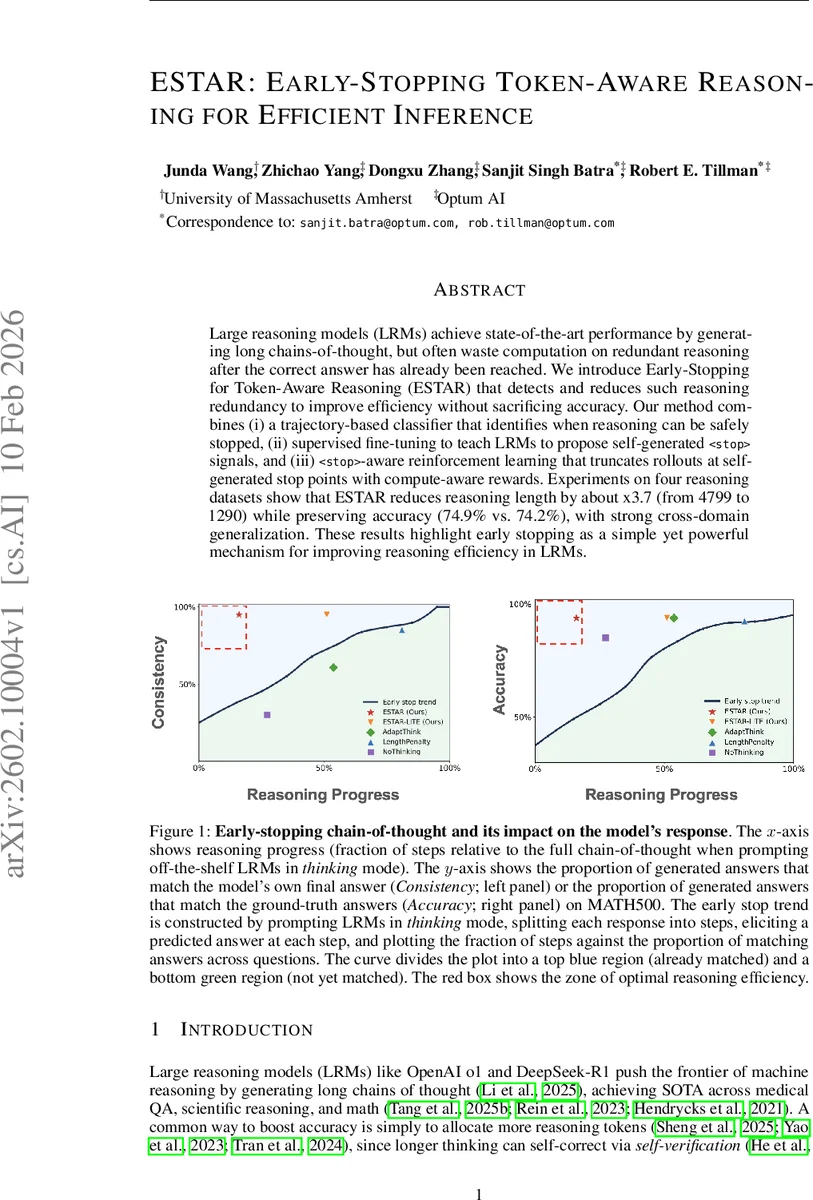
ESTAR는 대형 추론 모델(LRM)이 정답에 도달한 뒤에도 불필요하게 길어지는 체인‑오브‑생각(Chain‑of‑Thought)을 자동으로 감지·중단한다. 경량 LightGBM 분류기, 토큰을 학습시키는 지도 미세조정, 그리고 계산 비용을 보상에 포함한 강화학습을 결합해 평균 토큰 수를 3.7배 줄이면서 정확도는 0.7% 포인트만 감소시킨다.
상세 분석
본 논문은 LRM이 “생각” 단계에서 정답을 이미 도출했음에도 불구하고 추가적인 토큰을 생성하는 현상을 ‘중복 추론’이라고 정의하고, 이를 최소화하는 새로운 프레임워크 ESTAR를 제안한다. ESTAR는 세 가지 핵심 모듈로 구성된다. 첫 번째는 토큰‑레벨 로그 확률, 기울기, 곡률, 안정성 지표 등을 특징으로 하는 경량 LightGBM 분류기로, 현재 디코딩 단계에서 더 이상 추론을 진행해도 정답이 변하지 않을 확률을 예측한다. 두 번째는 SFT(지도 미세조정) 단계에서 모델에게 토큰을 스스로 발화하도록 학습시키는 과정이다. 여기서는 고정 길이 체크포인트에서 정답이 일치하면 해당 위치를 ‘양성’으로 라벨링해 데이터셋을 구성한다. 세 번째는 토큰 발화를 보상에 포함한 강화학습(RL) 단계이다. 보상 함수는 (1) 정답 일치 여부, (2) 토큰까지 사용된 토큰 수(짧을수록 보상 증가), (3) ESTAR‑LITE 분류기의 신뢰도 점수를 결합해 계산 효율성을 직접 최적화한다. 이때 롤아웃은 이 발생하면 즉시 종료되며, 이후 ESTAR‑LITE는 새로운 트래젝터리에 맞게 재학습된다. 실험은 USMLE, JAMA, Math500, AIME2025 등 네 개의 도메인에서 수행됐으며, 평균 토큰 수를 4799→1290으로 감소시켰음에도 정확도는 74.9%→74.2%로 98.9% 수준을 유지한다. 또한, GPQA와 같은 완전한 out‑of‑domain 데이터에서도 2‑3배 토큰 절감과 95% 이상 정확도 유지라는 강력한 일반화 능력을 보인다. 기존 방법인 LengthPenalty(1.4배 감소, 97.0% 정확도)이나 AdaptThink(2.2배 감소, 97.4% 정확도)보다 토큰 절감 비율과 정확도 보존 측면에서 모두 우수하다. 논문은 또한 ‘Tail Variation’이라는 이론적 정당성을 제시해, 답변 사후분포의 변동이 일정 임계값 이하일 때 안전하게 중단할 수 있음을 증명한다. 전체적으로 ESTAR는 “언제 멈출 것인가”라는 질문을 정량적·학습적 방법으로 해결함으로써, 추론 효율성을 크게 향상시키는 동시에 모델의 신뢰성을 유지한다.
댓글 및 학술 토론
Loading comments...
의견 남기기