아동 수준 입력으로 학습한 트랜스포머, 빈곤한 자극 가설을 넘어설 수 있을까
초록
본 논문은 10‑50 M 단어 규모의 아동 발달에 적합한 텍스트로 훈련한 트랜스포머 모델을 대상으로, 질문 형성, 섬(island) 제약, 결합 원리, “wanna” 축약 등 전통적인 빈곤한 자극 가설(PoSH) 현상을 평가하는 POSH‑Bench를 제시한다. 실험 결과, 직접적인 긍정 증거가 없어도 모델은 모든 현상에서 우연 수준을 넘는 일반화를 보였지만, 데이터 효율성에서는 아이들보다 크게 뒤처졌다. 추가로 제안된 세 가지 인지적 편향(두 개의 언어‑특화 편향, 하나의 도메인‑일반 편향)은 전반적인 구문 능력을 향상시켰지만 POSH‑Bench 성능에는 큰 영향을 주지 않았다. 이는 인간과 같은 데이터 효율성을 위해서는 현재 탐색된 편향 외에 다른 메커니즘이 필요함을 시사한다.
상세 분석
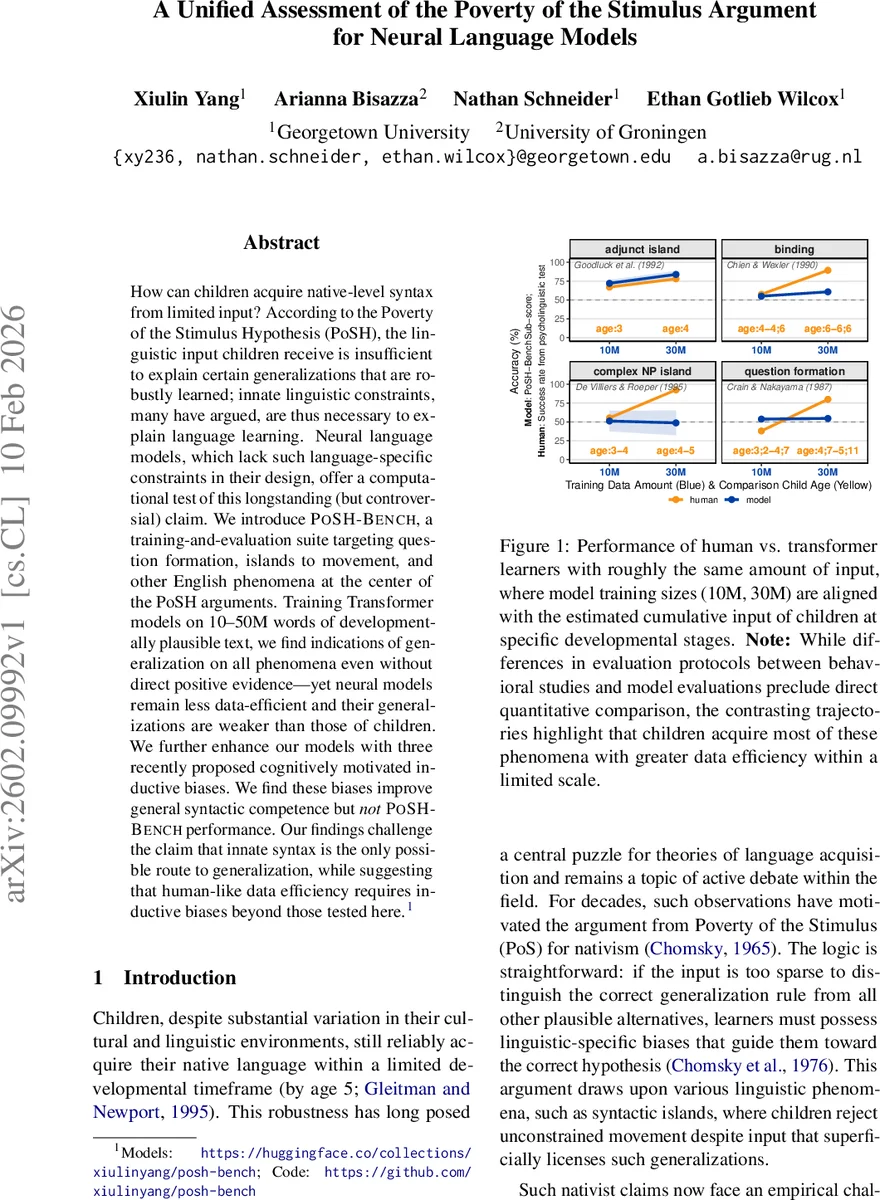
본 연구는 빈곤한 자극 가설(PoSH)이 주장하는 “입력이 너무 부족해 특정 문법 규칙을 학습할 수 없다”는 전제를, 현대 트랜스포머 언어 모델을 통해 실험적으로 검증한다. 먼저 10 M, 30 M, 50 M 단어 규모의 아동 발달에 맞는 텍스트 코퍼스를 구축하고, 직접적인 긍정 증거(direct positive evidence)를 의도적으로 제거한 변형 데이터셋을 만든다. 이렇게 만든 코퍼스로 훈련한 모델은 질문 형성(주보조동사 이동), 복합 명사구·보조절·부가절 섬 제약, 결합 원리(A‑Principle), “wanna” 축약 네 가지 현상을 각각 10개의 세부 테스트 항목으로 평가한다. 결과는 모델이 모든 현상에서 우연보다 높은 정확도를 보였으며, 특히 10 M 단어만으로도 일정 수준의 일반화가 가능함을 보여준다. 그러나 인간 아동이 동일한 입력량에서 달성하는 성공률과 비교하면, 모델은 여전히 데이터 효율성에서 큰 격차를 보인다(예: 질문 형성에서 아이들은 90 % 이상 정확하지만 모델은 60 % 수준).
다음으로 연구팀은 세 가지 인지적 편향을 도입한다. 첫 번째는 트리 구조를 명시적으로 학습하도록 하는 구조적 어텐션, 두 번째는 계층적 문법 라벨을 사전 학습에 활용하는 멀티태스크 학습, 세 번째는 도메인 일반적인 메타‑학습 프레임워크이다. 이들 편향은 전반적인 구문 판단(BLiMP, Zorro 등)에서 성능을 상승시켰지만, POSH‑Bench의 세부 현상에서는 기존 모델과 유의미한 차이를 만들지 못했다. 이는 현재 제안된 편향이 “일반적인 구문 규칙”을 강화하는 데는 효과적이지만, “희소한 직접 증거 없이도 특정 제한을 학습하는” 능력에는 한계가 있음을 의미한다.
또한 논문은 기존 베이비LM·BabyBERTa와 같은 대규모 인간‑규모 데이터 학습 모델과 비교하여, 입력 규모와 평가 타깃을 명확히 일치시킨 점을 강조한다. 한계점으로는 텍스트만을 사용했으며, 시각·청각 등 다중모달 입력이 아동 학습에 미치는 영향을 반영하지 못했다는 점, 그리고 영어에 국한된 현상만을 다루어 다른 언어에 대한 일반화 가능성을 검증하지 못했다는 점을 언급한다.
결론적으로, 트랜스포머는 빈곤한 자극 가설이 제시하는 “학습 불가능” 상황을 어느 정도 극복할 수 있지만, 인간 수준의 데이터 효율성과 정확도를 달성하려면 현재 탐색된 구조적·도메인 일반적 편향 외에 보다 강력하고 언어‑특화된 선천적 메커니즘이 필요함을 시사한다.
댓글 및 학술 토론
Loading comments...
의견 남기기