고차원에서 k 평균 알고리즘의 붕괴와 Hartigan 알고리즘의 회피 메커니즘
초록
본 논문은 고차원·고노이즈 환경에서 Lloyd의 k-평균이 거의 모든 파티션을 고정점으로 만들어 초기화 이후 진전이 없음을 이론적으로 증명한다. 반면 Hartigan의 k-평균은 이러한 병목 현상이 없으며, 올바른 군집을 높은 확률로 복구한다는 차이를 제시한다.
상세 분석
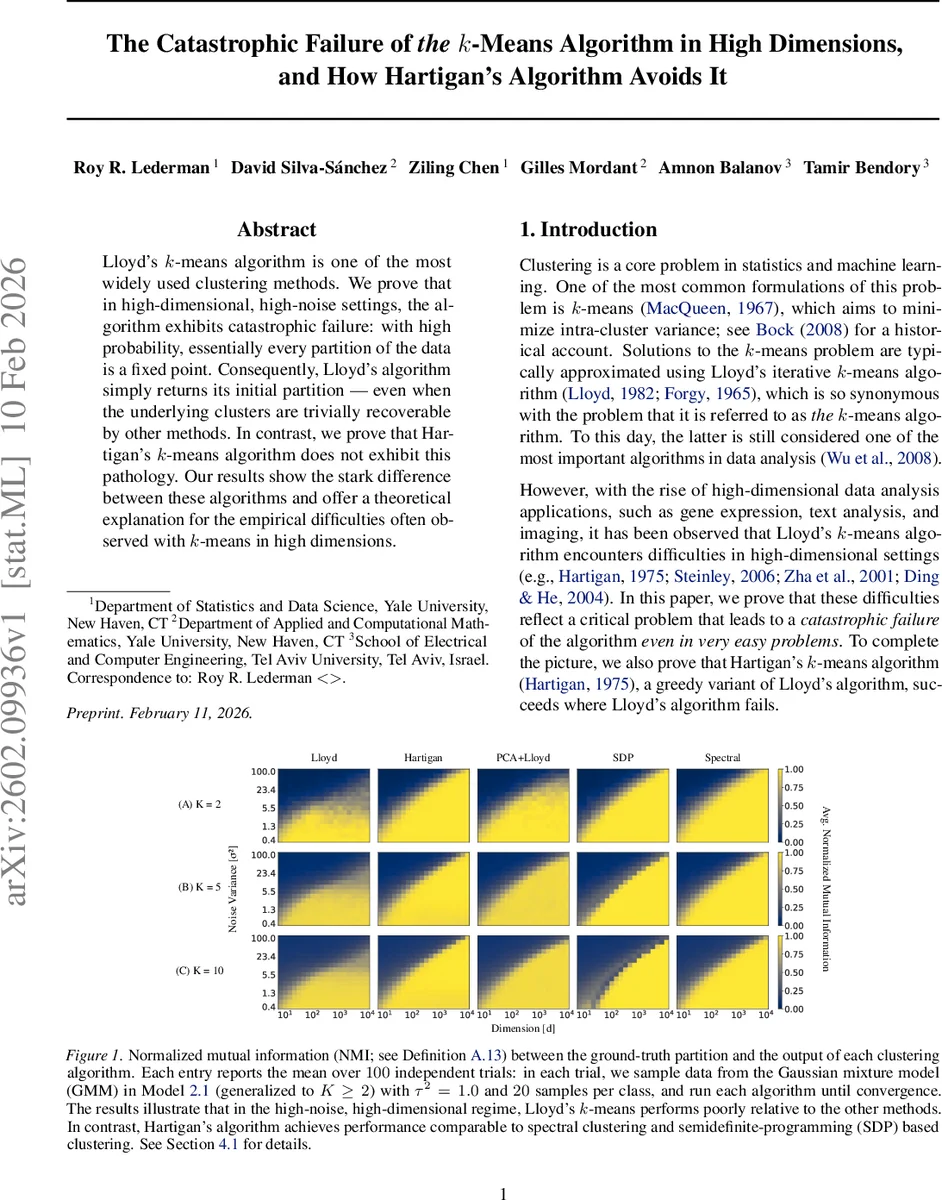
논문은 두 개의 가우시안 군집을 갖는 고차원 데이터 모델을 설정하고, Lloyd 알고리즘과 Hartigan 알고리즘의 업데이트 규칙을 정밀히 분석한다. 핵심은 각 샘플이 현재 클러스터 중심과 다른 클러스터 중심 사이의 거리 차이가 차원 d에 따라 χ² 분포로 스케일링된다는 점이다. Lemma 3.1·3.2에서 제시된 α_cur와 α_alt 스케일링 파라미터는 클러스터 순도와 샘플 수에 의존한다. 이를 바탕으로 Chernoff 경계(Lemma 3.3)를 적용해 거리 차이가 음수가 될 확률을 exp(−c·d^{1/4}) 형태로 상한한다. Theorem 3.4는 단일 샘플이 잘못된 클러스터에 머무를 확률이 차원에 대해 급격히 증가함을 보이며, σ² > n 조건 하에서 거의 모든 파티션이 Lloyd의 고정점이 된다. 이어서 Theorem 3.8은 q‑approximately balanced 파티션 전체에 대해 union bound를 적용해 전체 파티션 집합이 고정점이 될 확률을 1−o(1)로 만든다. 반면 Hartigan 알고리즘은 단일 샘플 이동에 대한 조건이 α_alt보다 더 큰 스케일을 요구하므로, 동일한 고노이즈·고차원 조건에서도 잘못된 고정점이 존재할 확률이 exp(−c·d^{1/4}) 수준으로 억제된다 (Theorem 3.12). 실험에서는 NMI 지표를 통해 Lloyd이 차원·노이즈가 커질수록 성능이 급격히 하락하는 반면, Hartigan은 스펙트럴 클러스터링·SDP와 비슷한 수준을 유지함을 확인한다. 이 결과는 Lloyd이 “거리 동등성” 현상에 취약해 모든 파티션을 고정점으로 만들지만, Hartigan은 한 샘플씩 개선하는 greedy 전략으로 이러한 현상을 회피한다는 중요한 통찰을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기