다작업 학습으로 완성하는 진정한 비전 백본, VersaViT
초록
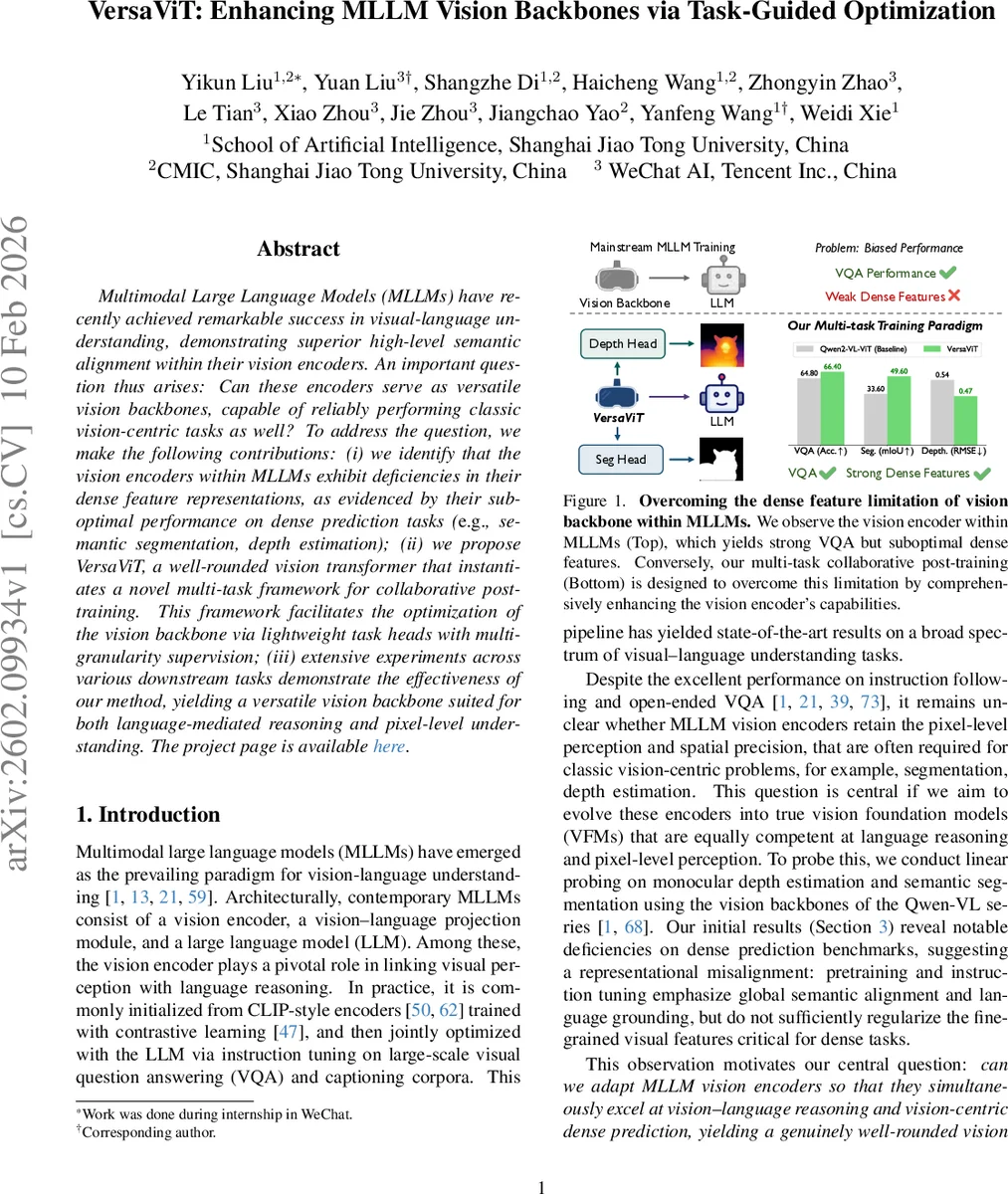
MLLM의 비전 인코더는 언어 이해는 뛰어나지만, 세그멘테이션, 깊이 추정 같은 픽셀 수준의 정밀한 비전 작업에는 취약합니다. 이 연구는 이러한 ‘밀집 표현’의 결함을 지적하고, VQA, 깊이 추정, 참조 세그멘테이션이라는 세 가지 수준의 작업으로 비전 백본을 협력적으로 사후 훈련하는 ‘VersaViT’ 프레임워크를 제안합니다. 이를 통해 언어 기반 추론과 픽셀 수준 이해 모두에서 뛰어난 다목적 비전 백본을 만들어냅니다.
상세 분석
본 논문의 핵심 기술적 통찰은 MLLM 비전 인코더의 표현력이 훈련 방식에 의해 편향되었다는 점입니다. 대조 학습과 텍스트 중심의 지시 튜닝은 전역적 의미 정렬에는 효과적이지만, 중간 수준의 공간 구조나 픽셀 수준의 미세한 특징을 규제하기에는 부족합니다. 이로 인해 Qwen-VL 시리즈와 같은 강력한 MLLM의 비전 인코더도 선형 탐사 시 밀집 예측 작업에서 CLIP이나 DINOv2 같은 일반 비전 모델에 비해 현저히 낮은 성능을 보였습니다.
VersaViT는 이러한 문제를 ‘다중 작업 협력 사후 훈련’이라는 우아한 해법으로 접근합니다. 기존 MLLM의 비전 인코더(예: Qwen2-VL-ViT)를 고정된 백본으로 사용하지 않고, 세 가지 유형의 경량 작업 헤드를 부착하여 함께 최적화합니다. 각 작업은 서로 다른 수준의 감독을 제공합니다: 1) VQA/이미지 캡셔닝(고수준 의미론), 2) 단안 깊이 추정(중간 수준 3D 공간 구조), 3) 참조 이미지 세그멘테이션(저수준 픽셀 정밀도 및 언어 조건화). 이때 깊이 추정을 위한 정답 레이블은 Depth Anything V2 모델을 이용한 의사 레이블링으로 생성하여 확장성을 높였습니다.
이 프레임워크의 핵심 설계 철학은 작업 간 간섭을 헤드에서 흡수하고, 백본은 모든 작업에 공통적으로 유용한 균형 잡힌 표현을 학습하도록 유도하는 것입니다. 결과는 매우 고무적입니다. VersaViT는 원래 MLLM의 VQA 성능을 유지하거나 향상시키면서도, 세그멘테이션과 깊이 추정에서의 성능을 극적으로 끌어올렸습니다. 이는 서로 다른 수준의 감독 신호가 경량 헤드의 매개 하에 상호 시너지를 낼 수 있음을 입증하며, ‘전문가’ 모델들을 만드는 대신 ‘다재다능한’ 단일 비전 백본을 구축하는 새로운 패러다임을 제시합니다. 이 접근법은 기존 MLLM 파이프라인과의 호환성이 높아 실용적이라는 점도 중요한 장점입니다.
댓글 및 학술 토론
Loading comments...
의견 남기기