그라디언트 보존 클리핑을 통한 RLVR 엔트로피 유연 제어
안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
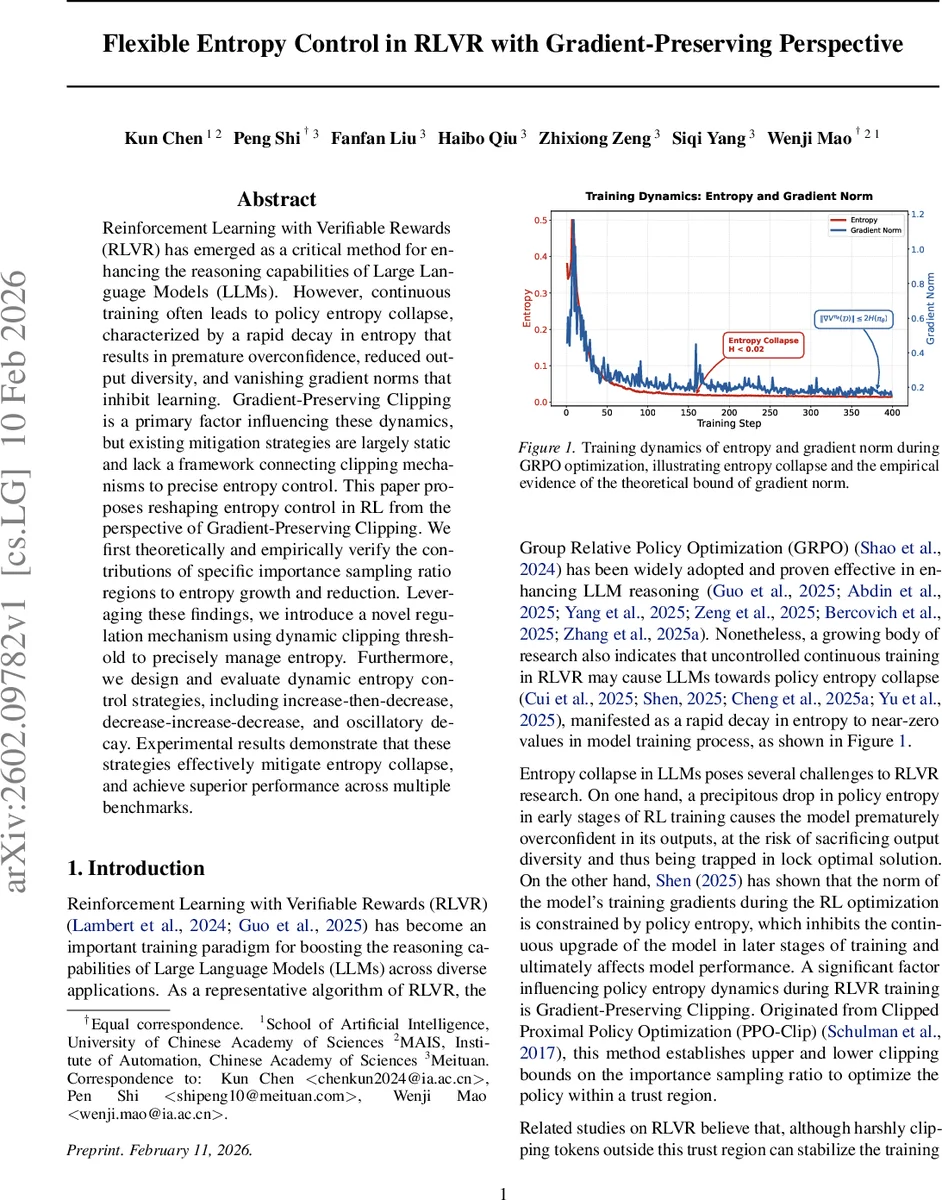
본 논문은 RLVR 학습 시 발생하는 정책 엔트로피 붕괴 현상을 그라디언트 보존 클리핑(GPC) 관점에서 분석하고, 중요도 샘플링 비율 영역별 엔트로피 기여를 정량화한다. 이를 기반으로 동적 클리핑 상한·하한을 설계해 엔트로피를 정밀히 조절하고, 증가‑감소, 감소‑증가‑감소, 진동형 감쇠 등 세 가지 전략을 제안한다. 실험 결과, 제안 방법이 엔트로피 붕괴를 완화하고 다양한 벤치마크에서 성능을 크게 향상시킴을 입증한다.
상세 분석
본 연구는 RLVR(Verification‑Reward Reinforcement Learning)에서 정책 엔트로피가 급격히 감소하는 ‘엔트로피 붕괴’ 문제를 근본적으로 해결하고자 한다. 핵심 아이디어는 PPO‑Clip에서 사용되는 중요도 샘플링 비율 rₜ = πθ/πold이 클리핑 구간에 따라 엔트로피 변화에 서로 다른 영향을 미친다는 점을 이론적으로 증명하는 것이다. 저자들은 로그 확률 −ln πθ(a|s)와 현재 엔트로피 H 의 관계를 이용해, 이득 Â>0 인 경우 고확률 토큰(E1)에서는 엔트로피가 감소하고 저확률 토큰(E2)에서는 증가함을, 손실 Â<0 인 경우는 그 반대(E3, E4)임을 도출한다. 이는 식 (6)에서 sgn⟨∇L,∇H⟩≈−sgn(·
댓글 및 학술 토론
Loading comments...
의견 남기기