에이전트스킬러 의미 통합을 통한 범용 에이전트 지능 확장
초록
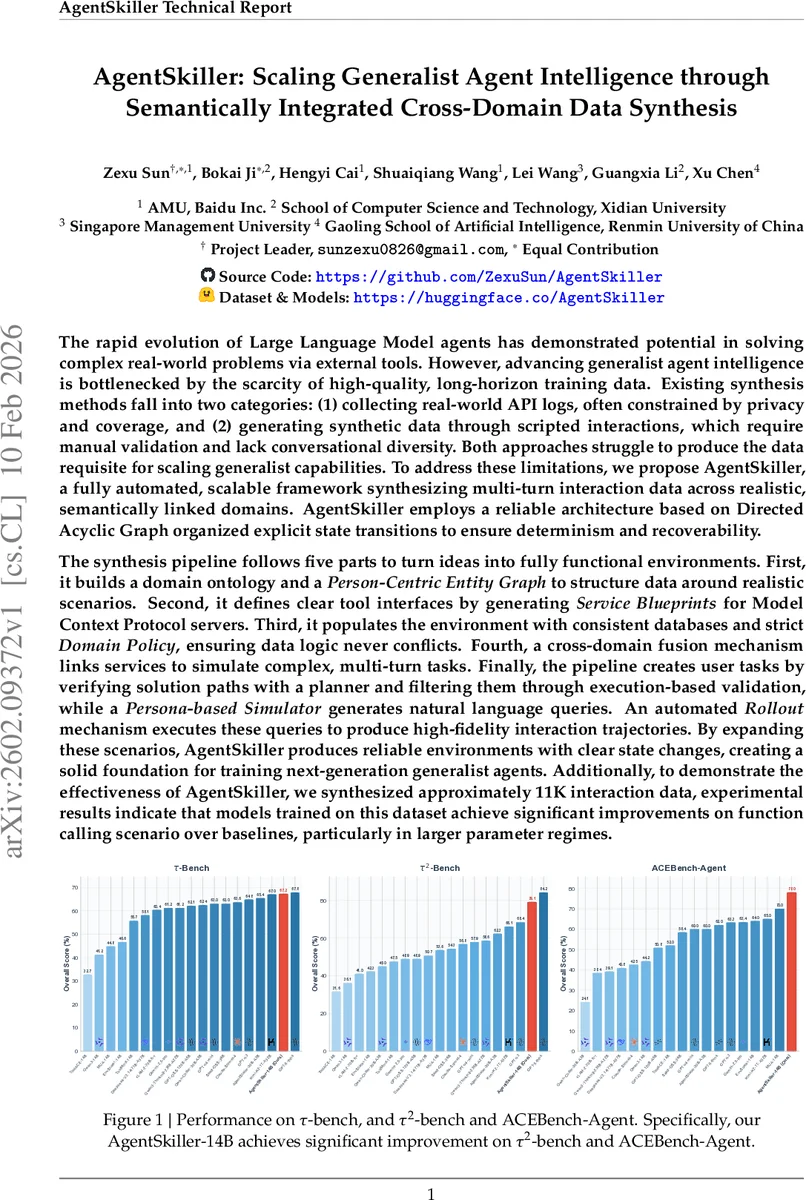
AgentSkiller는 DAG 기반 상태 머신과 도메인 온톨로지를 활용해 자동으로 다중 턴, 다중 도메인 툴 호출 데이터를 11 천 건 생성한다. 생성된 데이터로 학습한 14 B 모델은 τ‑bench·τ2‑bench·ACEBench 등 함수 호출 벤치마크에서 기존 오픈소스와 비교해 큰 성능 향상을 보이며, 특히 파라미터 규모가 클수록 그 격차가 확대된다.
상세 분석
본 논문은 범용 에이전트 지능을 고도화하기 위한 핵심 자원인 장기·다중 턴·다중 도메인 상호작용 데이터를 자동으로 합성하는 프레임워크 AgentSkiller를 제안한다. 설계상의 핵심은 세 가지 원칙이다. 첫째, Dual‑Model Architecture를 도입해 의미적 추론을 담당하는 텍스트 LLM과 구문·코드 생성을 담당하는 코딩 LLM을 분리함으로써 비용 효율성과 오류 감소를 동시에 달성한다. 둘째, State‑Machine Orchestration을 DAG(Directed Acyclic Graph) 형태의 18개 원자 단계로 구현하고, LangGraph 기반 자동 체크포인트를 삽입해 장시간 생성 파이프라인의 복구 가능성을 보장한다. 셋째, Test‑Driven Self‑Correction 메커니즘을 통해 생성된 SQL·Python·MCP 서버 코드가 실행 테스트에서 실패하면 오류 로그를 분석해 자동 패치를 수행한다.
데이터 합성 파이프라인은 크게 다섯 단계로 나뉜다.
- 도메인 온톨로지 및 Person‑Centric Entity Graph 구축 단계에서는 seed 토픽(예: 의료, 금융)에서 시작해 의미 확장을 수행하고, 인물 중심 엔티티 그래프를 생성해 현실적인 시나리오 기반 데이터를 구조화한다.
- Service Blueprint 생성 단계에서는 각 도메인에 대응하는 Model Context Protocol(MCP) 서버 인터페이스를 정의하고, API 스키마와 호출 규칙을 명세한다.
- 데이터베이스·정책 구현 단계에서는 온톨로지와 엔티티 그래프를 기반으로 제약 만족 데이터베이스와 도메인 정책을 자동 생성한다. 여기서 정책은 데이터 논리 일관성을 강제하고, 툴 호출 시 허용 범위를 명확히 한다.
- 크로스‑도메인 Fusion 단계에서는 서로 다른 서비스 블루프린트를 연결해 복합 작업을 시뮬레이션한다. 예를 들어, 의료 기록 조회 → 보험 청구 → 결제 처리와 같은 다단계 시나리오가 자동으로 구성된다.
- 태스크 인스턴스 생성·검증 단계에서는 플래너가 해결 가능한 목표 경로를 탐색하고, 실행 기반 검증을 통해 실제로 성공하는 시나리오만을 필터링한다. 이후 Persona‑Based Simulator가 자연어 사용자 질의를 생성하고, Rollout 엔진이 이를 실행해 최종 멀티턴 대화 트랙을 만든다.
실험에서는 약 11 K개의 고품질 인터랙션 샘플을 합성했으며, 이를 기존 공개 데이터와 결합해 14 B 규모의 AgentSkiller‑14B 모델을 학습시켰다. τ‑bench, τ2‑bench, ACEBench‑Agent 등 세 가지 함수 호출 벤치마크에서 AgentSkiller‑14B는 전체 점수 63 % 이상을 기록, 동일 파라미터 규모의 ToolACE‑14B·Qwen3‑14B 등 대비 5~10 %p 상승을 보였다. 특히 파라미터가 30 B 이상인 모델에서는 성능 격차가 더욱 확대돼, 대형 모델이 복합 도메인 작업에서 데이터 스케일링의 효과를 크게 누릴 수 있음을 입증한다.
이러한 결과는 (1) 데이터 다양성—다중 도메인·다중 턴·다양한 툴 조합, (2) 상태 전이의 결정성—DAG 기반 재현 가능성, (3) 자동 검증·수정 루프—코드 오류와 논리 불일치를 사전에 차단—이라는 세 요소가 범용 에이전트 학습에 필수적임을 시사한다. 또한, 온톨로지와 엔티티 그래프를 활용한 의미적 확장은 기존 스크립트 기반 합성 방식보다 인간‑유사한 시나리오를 자동으로 생성할 수 있게 해, 라벨링 비용을 크게 절감한다.
한계점으로는 현재 온톨로지 확장이 사전 정의된 seed 토픽에 의존한다는 점, 그리고 크로스‑도메인 Fusion 과정에서 서비스 간 의존 관계가 복잡해질 경우 자동 검증 비용이 급증할 수 있다는 점을 들 수 있다. 향후 연구에서는 (i) 대규모 웹 크롤링·지식 그래프를 활용한 온톨로지 자동 확장, (ii) 강화학습 기반 플래너를 도입해 목표 경로 탐색 효율성 향상, (iii) 인간‑인증 루프를 최소화하는 메타‑검증 기법 도입 등을 통해 프레임워크의 범용성과 확장성을 더욱 강화할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기