생생한 음·영상 생성, ALIVE가 만든 새로운 애니메이션 파라다임
초록
ALIVE는 기존 텍스트‑투‑비디오 모델에 오디오 생성 및 레퍼런스 기반 애니메이션 기능을 추가한 통합 음·영상 생성 프레임워크이다. MMDiT 기반의 듀얼 스트림 구조에 TA‑CrossAttn과 UniTemp‑RoPE를 도입해 시간 정렬을 정밀하게 맞추고, 1백만 수준의 고품질 음·영상 데이터 파이프라인으로 사전학습·미세조정을 수행한다. 1080p 고해상도 영상과 자연스러운 음성·배경음 동기화를 동시에 제공하며, Alive‑Bench 1.0 벤치마크에서 상용 솔루션을 능가한다.
상세 분석
ALIVE는 “Dual Stream + Single Stream”이라는 새로운 아키텍처 패러다임을 제시한다. 기본이 되는 Waver 1.0 비디오 디프usion Transformer와 별도로 설계된 Audio‑DiT가 각각 비디오와 오디오 라틴트를 처리한다. 두 스트림 간의 상호작용은 TA‑CrossAttn(Temporally‑Aligned Cross‑Attention)으로 구현되는데, 이는 기존 Cross‑Attention이 시간 정보를 무시하고 단순히 토큰 인덱스에 의존하는 한계를 극복한다. TA‑CrossAttn은 UniTemp‑RoPE(Unified Temporal Rotary Positional Embedding)와 결합돼, 오디오와 비디오 라틴트가 서로 다른 샘플링 레이트와 시계열 해상도를 가질 때도 물리적 시간 좌표를 공유하도록 설계되었다. 구체적으로, 비디오 라틴트의 위치는 오디오 라틴트의 연속적인 시간 좌표 Φ(i)로 매핑되어, “0.33초”와 같은 비정수 시간값을 RoPE에 적용한다. 이 방식은 입·출력 시퀀스 간의 미세한 시간 차이를 정밀히 보정해, 다중 화자 상황에서도 입술 움직임과 음성 파형이 정확히 일치하도록 만든다.
Audio‑DiT는 32개의 Transformer 블록으로 구성되며, Wave‑VAE를 이용해 원시 파형을 저차원 라틴트 공간으로 압축한다. 텍스트 조건은 두 가지로 분리된다. 첫째,
고해상도 출력을 위해 ALIVE는 480p 베이스 모델 위에 Cascaded Audio‑Video Refiner를 추가한다. Refiner는 비디오 디테일을 업스케일링하면서 오디오 라틴트를 그대로 전달해, 기존 베이스 모델에서 학습된 음·영상 동기화를 보존한다. 실험적으로 Audio‑DiT를 고정하고 비디오 라틴트에만 노이즈를 주입한 변형이 가장 안정적인 결과를 보였으며, 오디오에 노이즈를 가하면 배경음이 왜곡되는 문제가 확인되었다.
데이터 측면에서는 “Audio‑Video Captioning + Quality Control” 파이프라인을 구축해, 영상·오디오 각각에 대한 품질 필터링과 ‘시각‑오디오 키워드 라벨링’ 시스템을 도입했다. 특히 다중 인물 대화 데이터에서 ‘Subject‑Speech Correspondence’를 교정해 화자 정체성을 일관되게 유지하도록 했다. 이러한 과정을 거쳐 1백만 개 이상의 고품질 샘플을 확보했으며, 계층적 필터링과 라벨링을 통해 데이터 편향을 최소화했다.
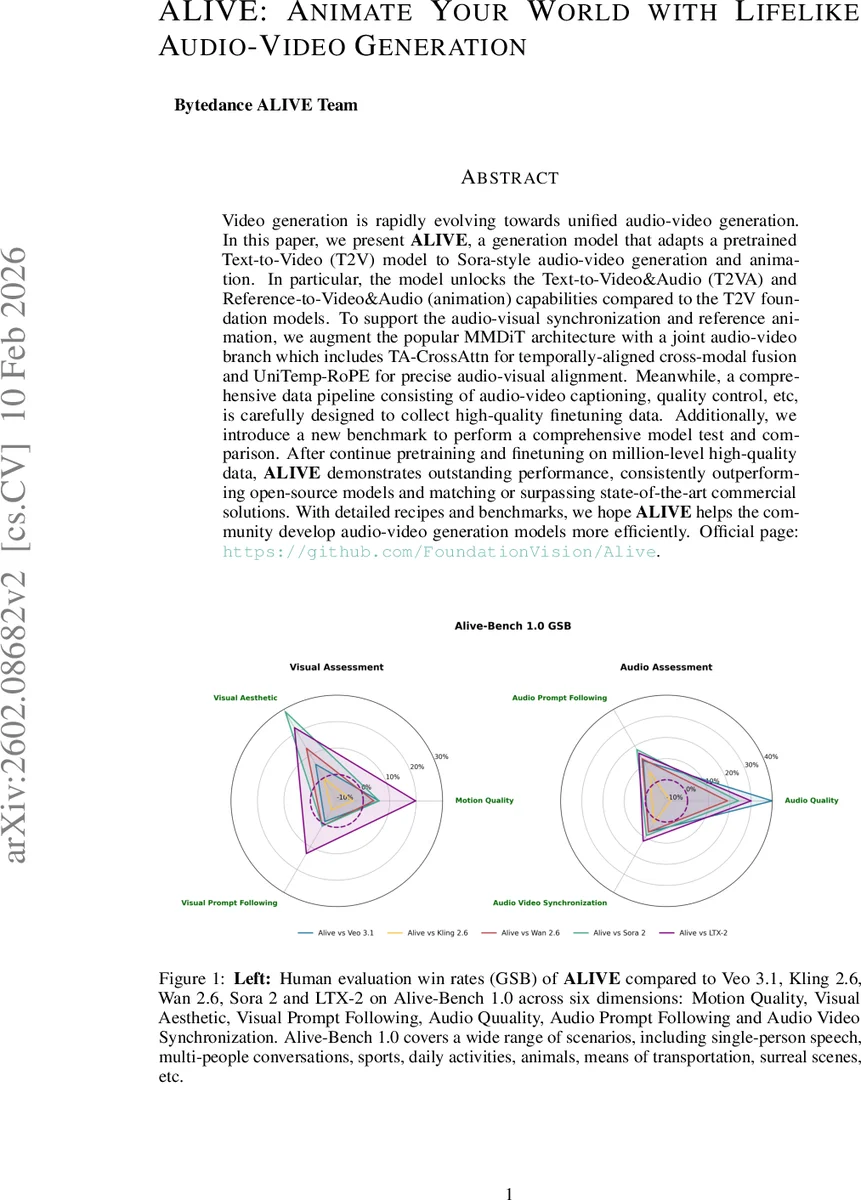
벤치마크 Alive‑Bench 1.0은 22개의 세부 메트릭을 포함해 Motion Quality, Visual Aesthetic, Prompt Following, Audio Quality, Audio Prompt Following, Audio‑Video Synchronization 등 6대 축을 평가한다. 인간 평가(GSB) 결과 ALIVE는 VEO 3.1, Kling 2.6, WAN 2.6 등 최신 공개 모델을 모두 앞서며, 상용 Sora 2와도 경쟁 수준을 보였다.
마지막으로 ‘Role‑Playing Animate’ 모듈은 다중 레퍼런스 이미지와 시간 오프셋을 활용해 정체성을 고정된 앵커로 사용한다. 이를 통해 복제‑붙여넣기(bias) 문제를 완화하고, 인물의 움직임과 표정 변화를 자연스럽게 생성한다.
전체적으로 ALIVE는 (1) 정밀한 시간 정렬을 위한 UniTemp‑RoPE와 TA‑CrossAttn, (2) 고품질 데이터 파이프라인, (3) 단계적 고해상도 Refiner, (4) 레퍼런스 기반 애니메이션 메커니즘이라는 네 가지 핵심 기술을 결합해, 텍스트‑투‑음·영상 생성 분야에서 새로운 기준을 제시한다. 다만, 현재 5‑10초 길이의 클립에 최적화돼 있어 장시간 콘텐츠 생성 시 메모리·연산 비용이 급증할 가능성이 있으며, 다중 언어·다중 화자 상황에서의 음성 자연스러움은 아직 상용 솔루션에 비해 약간 뒤처진다.
댓글 및 학술 토론
Loading comments...
의견 남기기