과학 추론을 위한 데이터·보상 설계 혁신: Dr. SCI 파이프라인
초록
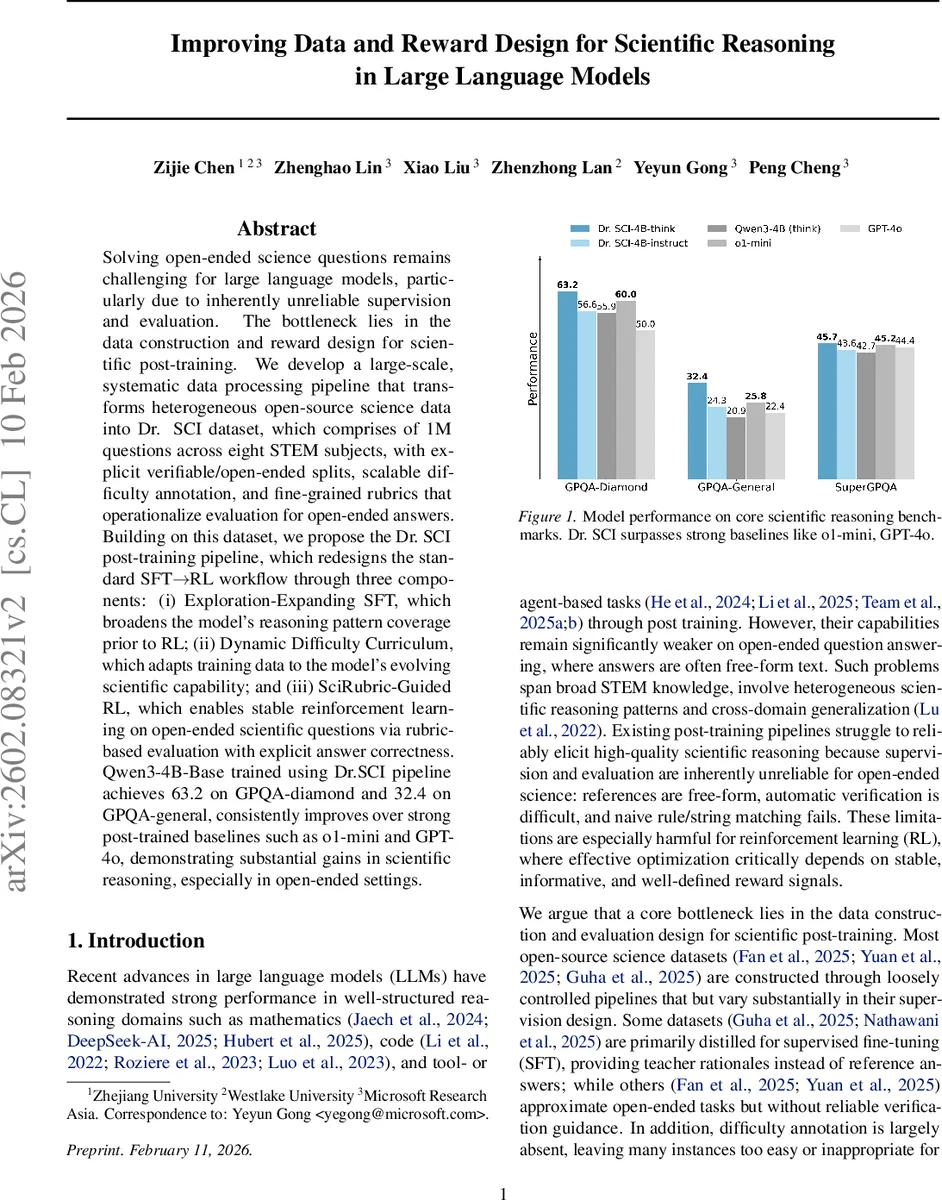
본 논문은 과학 분야의 개방형 질문에 대한 LLM 성능 한계를 데이터와 보상 설계에서 찾고, 1백만 개의 STEM 질문을 포함한 Dr. SCI 데이터셋을 구축한다. 이후 탐색‑확장 SFT, 동적 난이도 커리큘럼, Rubric‑기반 RL이라는 세 단계로 구성된 Dr. SCI 포스트‑트레이닝 파이프라인을 제안한다. 4B 규모 모델에 적용한 결과, 기존 o1‑mini·GPT‑4o 등보다 크게 앞서 GPQA‑diamond 63.2, GPQA‑general 32.4 점수를 기록한다.
상세 분석
이 연구는 과학적 추론, 특히 정답이 자유형식으로 제시되는 개방형 질문에서 LLM이 겪는 “감독·평가 불안정성”을 핵심 병목으로 규정한다. 기존 오픈소스 과학 데이터는 감독 설계이 일관되지 않으며, 난이도 라벨링이 부족해 커리큘럼 학습에 부적합했다. 저자들은 이러한 문제를 해결하기 위해 크게 세 가지 혁신을 도입한다. 첫째, Exploration‑Expanding SFT는 4‑gram 다양성을 기준으로 데이터 샘플을 선택한다. 이는 모델이 학습 초기에 다양한 추론 패턴(공식 전개, 실험 설계, 개념 설명 등)에 노출되도록 보장한다. 기존 SFT가 단순히 대규모 데이터에 무작위로 fine‑tune 하는 것과 달리, 선택적 샘플링을 통해 “탐색 상한”을 인위적으로 높인다. 둘째, Dynamic Difficulty Curriculum은 사전 추정된 난이도 점수를 활용해 학습 데이터를 지속적으로 재구성한다. 너무 쉬운 샘플은 discard, 현재 모델이 마스터한 샘플은 train set에서 제외하고, 난이도가 낮은 pending 샘플을 단계적으로 투입한다. 이렇게 하면 모델이 현재 능력에 맞는 난이도 구간에서 최적의 신호를 받으며, 학습 효율이 크게 향상된다. 셋째, SciRubric‑Guided RL은 개방형 질문에 대한 평가를 “루브릭 아이템” 단위로 세분화한다. 각 아이템은 Essential, Important, Optional, Pitfall으로 구분되며, 경량 검증 모델이 해당 아이템의 충족 여부를 0/1로 판단한다. 또한 최종 답안(예: \boxed{} 형태)과 정답을 별도 검증해 “정답성”을 명시적으로 보상에 포함한다. 이중 보상 구조는 기존의 단일 정답 매칭보다 훨씬 안정적인 신호를 제공해 RL 단계에서 급격한 보상 변동을 방지한다. 실험에서는 4B 베이스 모델(Qwen‑3‑4B‑Base)을 Dr. SCI 파이프라인에 적용했을 때, GPQA‑diamond 63.2점, GPQA‑general 32.4점을 달성했으며, 이는 파라미터 규모가 10배 이상 큰 o1‑mini와 GPT‑4o를 능가한다. 특히 개방형 과학 질문에서 Rubric‑기반 RL이 기존 rule‑based RL보다 크게 우수함을 입증한다. 전체적으로 데이터 품질(중복 제거, 난이도 조정, 루브릭 생성)과 보상 설계가 서로 보완되어, 작은 모델이라도 고난이도 과학 추론 능력을 획득할 수 있음을 보여준다.
댓글 및 학술 토론
Loading comments...
의견 남기기