개인화와 객관성 균형을 위한 적응형 추론 PersonaDual
안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
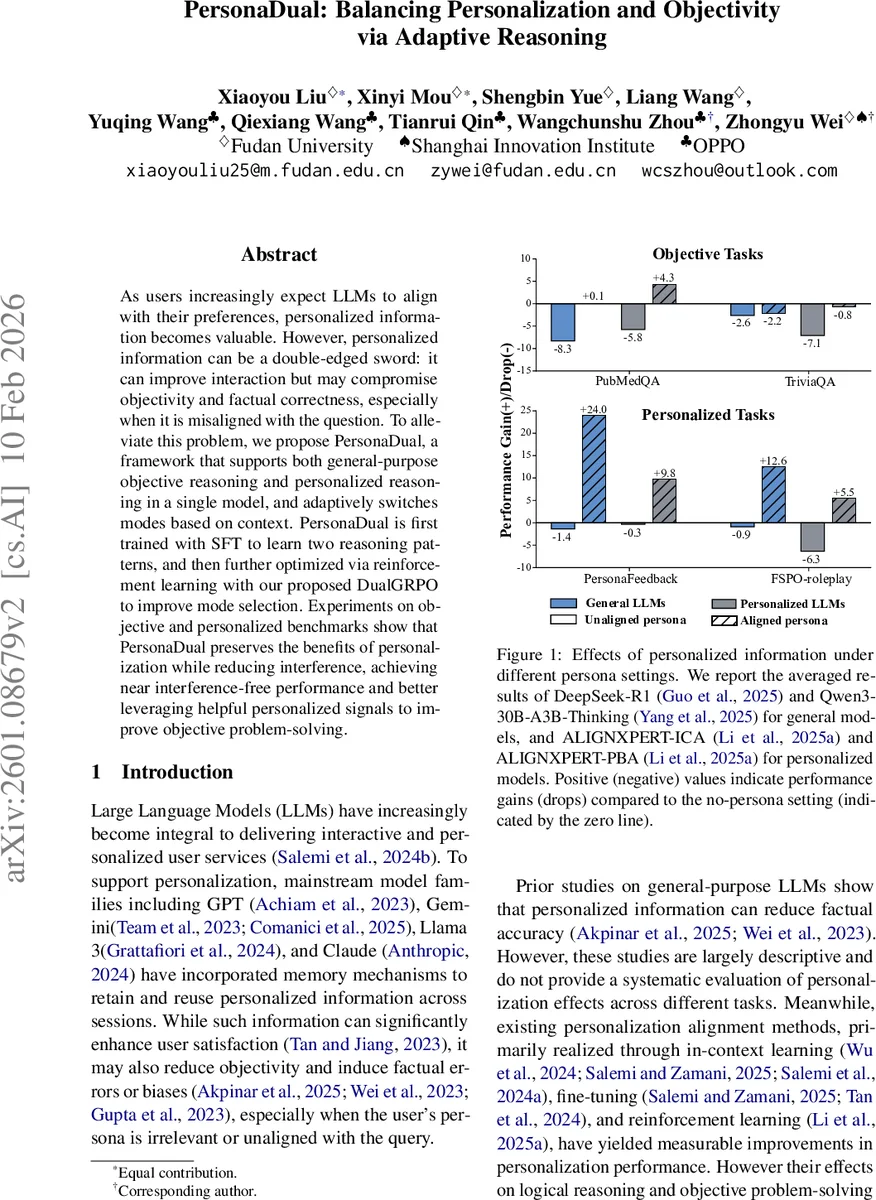
PersonaDual는 하나의 LLM 안에 객관적 추론 모드와 개인화 추론 모드를 통합하고, 질문과 사용자 페르소나 정보를 기반해 두 모드 중 최적을 자동 선택하도록 설계된 프레임워크이다. SFT 단계에서 두 모드의 사고 흐름을 학습하고, DualGRPO라는 강화학습 알고리즘으로 모드 전환 정책을 최적화한다. 실험 결과, 비정렬 페르소나가 객관적 QA 성능을 저해하는 현상을 크게 완화하면서, 정렬된 페르소나를 활용해 객관적 정확도를 평균 3% 정도 향상시켰다.
상세 분석
본 논문은 대형 언어 모델(LLM)이 사용자 맞춤형 정보를 활용하면서도 객관성을 유지해야 하는 딜레마를 해결하고자 한다. 기존 연구들은 개인화된 프롬프트나 파라미터 튜닝을 통해 사용자 선호를 반영하지만, 이는 종종 “정렬 세금”이라 불리는 사실성 저하와 편향을 초래한다. 저자들은 이러한 문제를 인지·느린 사고 이론(dual‑process theory)과 연결시켜, 두 개의 독립적인 추론 체계를 하나의 모델에 내재화하고 상황에 따라 전환하도록 설계하였다.
-
데이터 구성: PersonaDualData‑SFT는 객관적 모드와 개인화 모드 각각에 대한 고품질 체인‑오브‑씽크(Chain‑of‑Thought) 데이터를 포함한다. 객관적 모드에서는 질문만 제공하고, 개인화 모드에서는 질문과 페르소나(p)를 모두 제공해 페르소나 속성을 적극적으로 활용하도록 유도한다.
-
모델 구조: 두 모드를 구분하기 위해 각각 `
댓글 및 학술 토론
Loading comments...
의견 남기기