반사형 자동 형식화와 미래 제한 시퀀스 최적화
초록
ReForm은 자동 형식화 과정을 인간 전문가가 수행하는 ‘생각하고 고쳐쓰기’ 절차와 유사하게 설계한 모델이다. PBSO라는 새로운 강화학습 알고리즘으로 최종 형식화와 중간 단계의 의미 검증 두 가지 보상을 동시에 최적화해, 기존 일회성 생성 방식보다 평균 22.6%p 높은 정확도를 달성한다. 또한 859개 전문가 라벨을 가진 ConsistencyCheck 벤치마크를 제시해 평가 신뢰성을 검증한다.
상세 분석
본 논문은 자동 형식화(autoformalization) 분야의 핵심 문제인 ‘의미 일관성’ 결여를 해결하기 위해 두 가지 혁신을 제시한다. 첫 번째는 반사형(Reflective) 자동 형식화 패러다임이다. 기존 LLM 기반 모델은 질문을 입력받아 한 번에 형식화된 명제를 출력하는 일패스(one‑pass) 방식을 사용한다. 이는 인간이 문제를 읽고, 초안을 만들고, 스스로 검증·수정하는 과정을 무시하기 때문에, 양화자 범위 오해, 암시적 제약 누락 등 미묘한 의미 오류가 빈번히 발생한다. ReForm은 질문 Q와 이전 시도들의 히스토리 Hₜ를 유지하면서, 매 반복마다 (1) 새로운 형식화 Sₜ를 생성하고 (2) Sₜ에 대한 의미 검증 비평 Cₜ를 스스로 작성한다. 이 두 단계가 순차적으로 이어지면서 하나의 연속적인 토큰 스트림 안에서 자동 형식화와 자기 검증이 교차한다. 즉, 모델은 “생성 → 검증 → 재생성” 루프를 내부적으로 수행하므로, 별도의 외부 피드백 없이도 의미 오류를 점진적으로 교정할 수 있다.
두 번째 혁신은 **Prospective Bounded Sequence Optimization (PBSO)**이다. 반사형 패러다임은 최종 형식화 성공 여부와 중간 비평의 정확성이라는 이질적인 보상을 필요로 한다. 기존 강화학습(RL) 방법은 보통 마지막 단계에만 보상을 주어, 중간 비평이 형식화에 미치는 영향을 학습하기 어렵다. PBSO는 각 토큰 위치마다 서로 다른 보상 rₜ^aux(비평 품질)와 r_task(최종 정답 정확도)를 정의하고, ‘전망 제한 반환(prospective bounded return)’을 통해 미래 보상의 할인합을 현재 단계에 안전하게 할당한다. 반환값을 보상 함수의 범위 내에서 클리핑함으로써 무한히 누적되는 보상으로 인한 학습 불안정을 방지한다. 결과적으로 모델은 비평이 실제로 오류를 잡아내고, 그 비평이 다음 생성 단계에 유용하게 활용되도록 학습된다.
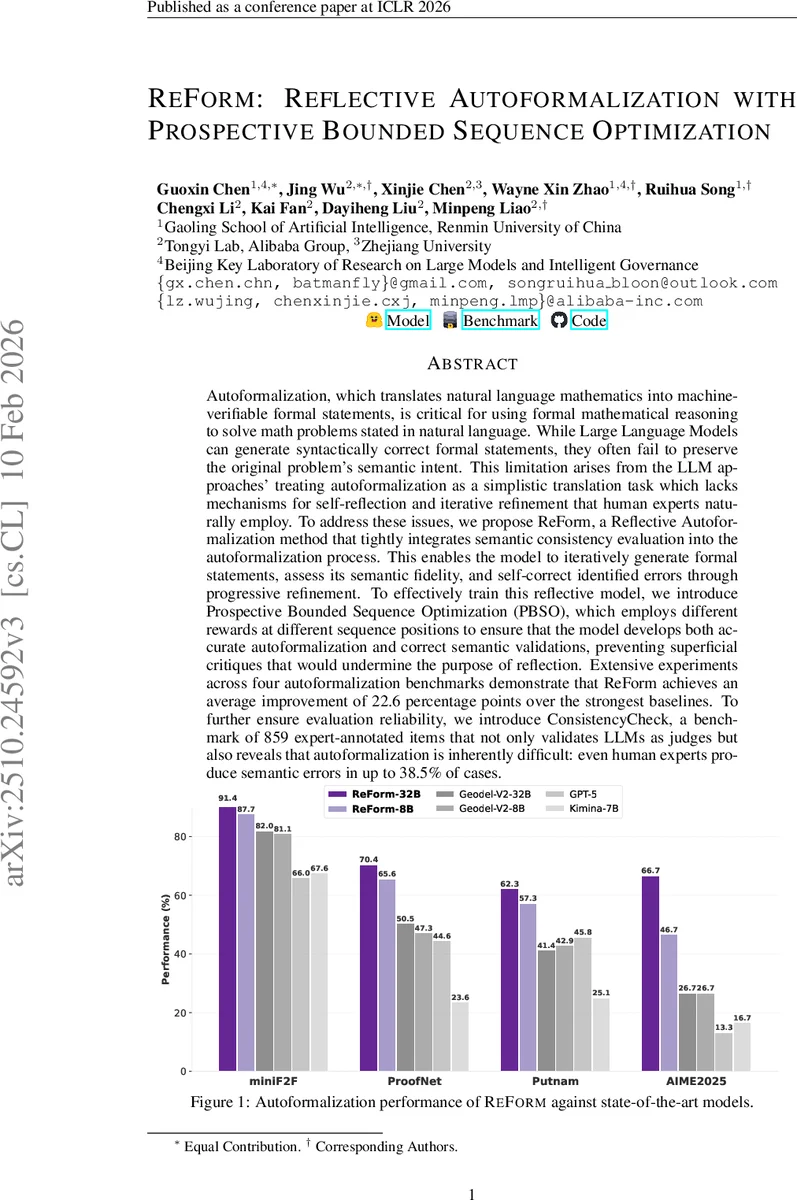
실험에서는 miniF2F, ProofNet, Putnam, AIME2025 네 개의 대표적인 자동 형식화 벤치마크를 사용하였다. ReForm‑32B와 ReForm‑8B는 각각 최신 Geodel‑V2와 GPT‑5 등 강력한 베이스라인을 크게 앞서며, 특히 의미 일관성 측면에서 평균 22.6%p(percentage points)의 향상을 보였다. 또한 저자들은 ConsistencyCheck라는 859개 인간 전문가가 라벨링한 검증 데이터셋을 구축해, LLM 기반 평가자의 신뢰성을 정량화하였다. 결과는 인간 전문가조차 16.4%~38.5%의 의미 오류를 범함을 보여 자동 형식화가 근본적으로 어려운 작업임을 강조한다. LLM 판단자는 85.8% 정확도로 충분히 신뢰할 수 있음을 입증했으며, 이는 ReForm의 성능 향상이 평가 잡음보다 월등히 크다는 것을 의미한다.
전체적으로 본 연구는 (1) 자동 형식화에 ‘반사적 자기 검증’ 메커니즘을 도입해 인간 전문가의 작업 흐름을 모방하고, (2) 다중 보상을 안정적으로 학습시키는 PBSO 알고리즘을 제시함으로써, 기존 일회성 번역 접근법의 한계를 뛰어넘는 새로운 패러다임을 제공한다는 점에서 의의가 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기