다우로 강 플룸 장기 매핑을 위한 다중 에이전트 강화학습
초록
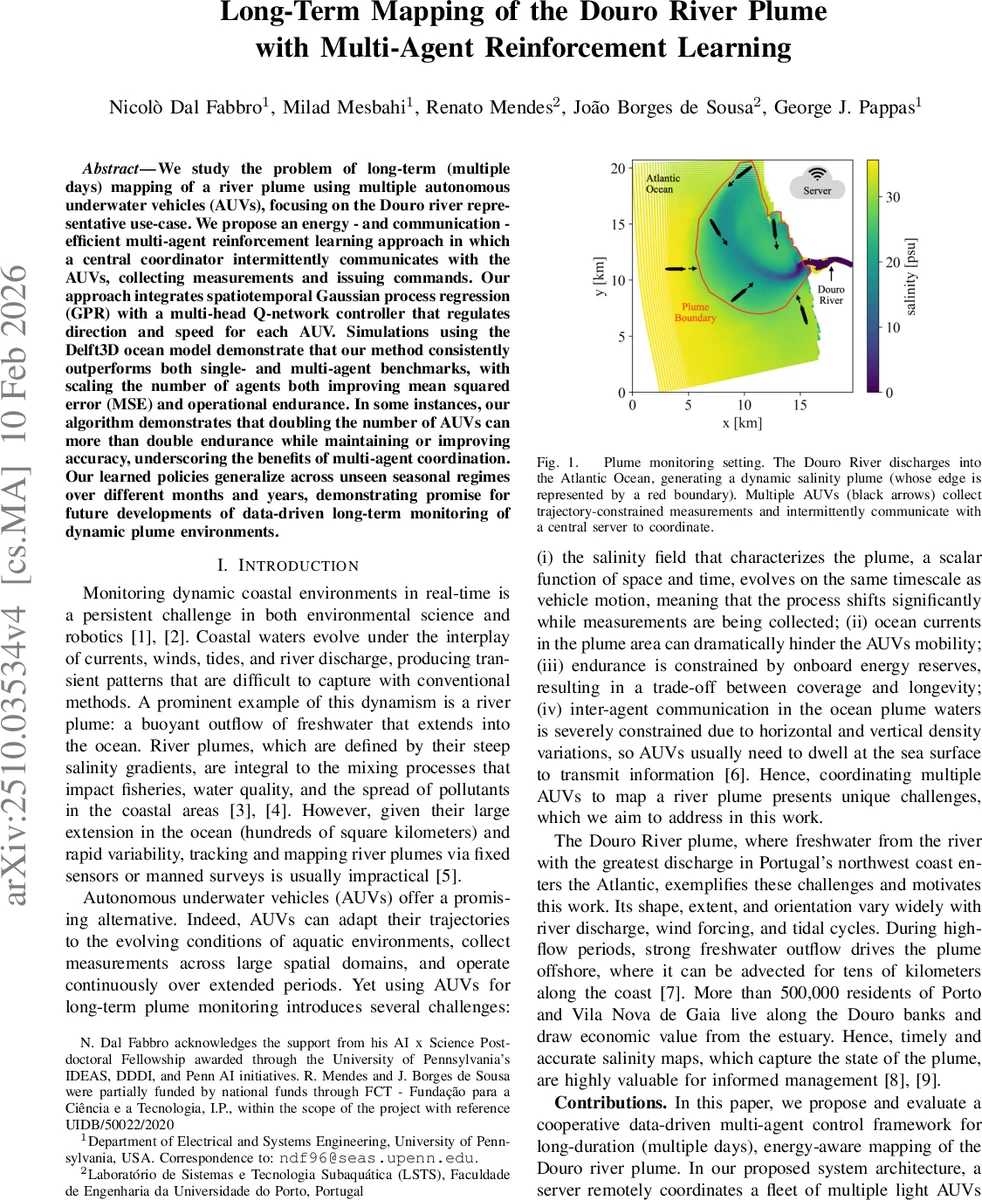
본 논문은 다우로 강 플룸을 다중 자율 수중 차량(AUV)으로 장기간(수일) 매핑하기 위해, 중앙 코디네이터와 간헐적 통신을 이용하는 에너지·통신 효율적인 다중 에이전트 강화학습 프레임워크를 제안한다. 시공간 가우시안 프로세스 회귀(GPR)와 다중 헤드 딥 Q‑네트워크를 결합해 각 AUV의 방향·속도를 제어하고, Delft3D 기반 시뮬레이션에서 평균 제곱 오차(MSE)와 임무 지속시간 모두에서 기존 단일·다중 에이전트 기준을 능가함을 보였다.
상세 분석
이 연구는 해양 플룸 모니터링이라는 고유의 물리적 제약을 정확히 짚어낸다. 첫째, 플룸의 염도 경계가 차량 이동 속도와 동등한 시간 스케일로 변동한다는 점은 ‘동시성 부족(synopticity)’ 문제를 야기한다. 기존의 사전 계획된 라운드 로버(Lawn‑mower) 방식이나 정적 정보획득(IPP) 기법은 이러한 빠른 변화를 따라가지 못한다. 둘째, 해류가 AUV의 명목 속도(1 m/s)와 동등하거나 그 이상일 경우 추진 효율이 급격히 저하될 수 있다. 논문은 이를 해결하기 위해 두 단계 속도(1 m/s와 0.4 m/s)를 도입하고, 속도 선택을 강화학습 정책에 포함시켜 에너지 소비와 탐사 효율 사이의 트레이드오프를 학습한다.
핵심 알고리즘은 시공간 GPR을 이용해 현재 시점의 염도 장면을 추정하고, 이를 상태 입력으로 하는 다중 헤드 DQN을 통해 ‘방향(head‑dir)’과 ‘속도(head‑spd)’를 별도로 출력한다. 다중 헤드 설계는 각 에이전트가 독립적인 행동 공간을 갖게 함으로써 스케일링 시 계산 복잡도를 크게 증가시키지 않는다. 보상 함수는 MSE 감소와 에너지 사용(속도에 비례하는 추진 비용)을 동시에 고려하도록 설계돼, 에이전트가 고속 탐사와 저속 장기 체류 사이를 상황에 맞게 전환한다.
통신 구조는 ‘간헐적·저용량’ 모델을 가정한다. 매 30분마다 모든 AUV가 수면에 떠올라 최신 측정값(공간‑시간 좌표와 염도)과 현재 상태를 서버에 업로드하고, 서버는 전체 데이터셋을 GPR로 업데이트한 뒤, 각 에이전트에 새로운 행동 명령을 전송한다. 전송 데이터량은 평균 5~10개의 측정점(≈160 bytes)으로, 실제 해양 환경에서의 대역폭 제한을 충분히 만족한다.
실험은 Delft3D 기반의 고해상도 시뮬레이션(다양한 풍·조·유량 조건)에서 수행됐으며, 3대에서 6대로 에이전트 수를 늘릴 경우 평균 MSE가 30 % 이상 감소하고, 임무 지속시간이 2배 이상 연장되는 결과가 보고되었다. 특히 학습된 정책은 훈련에 사용되지 않은 계절(다른 월·연도)의 흐름 패턴에도 일반화되어, 플룸 형태가 크게 변해도 안정적인 매핑을 유지한다. 이는 GPR이 제공하는 불확실성 추정과 DQN이 학습한 탐사‑에너지 정책이 상호 보완적으로 작용한 결과라 할 수 있다.
이 논문은 (1) 물리‑환경 제약을 강화학습에 직접 통합한 설계, (2) 에너지 효율을 위한 다중 속도 제어, (3) 제한된 통신을 활용한 중앙‑분산 하이브리드 아키텍처, (4) 실제 해양 모델을 통한 광범위한 검증이라는 네 가지 주요 기여를 제공한다. 향후 실제 AUV 실험 및 실시간 해류 예측 모델과의 연계가 진행된다면, 해양 플룸뿐 아니라 유사한 동적 환경(예: 유출 물질 확산, 적조 모니터링)에도 적용 가능한 범용 프레임워크가 될 전망이다.
댓글 및 학술 토론
Loading comments...
의견 남기기