n‑머스키트: 강화학습으로 이끄는 언어 모델 협업 메커니즘
초록
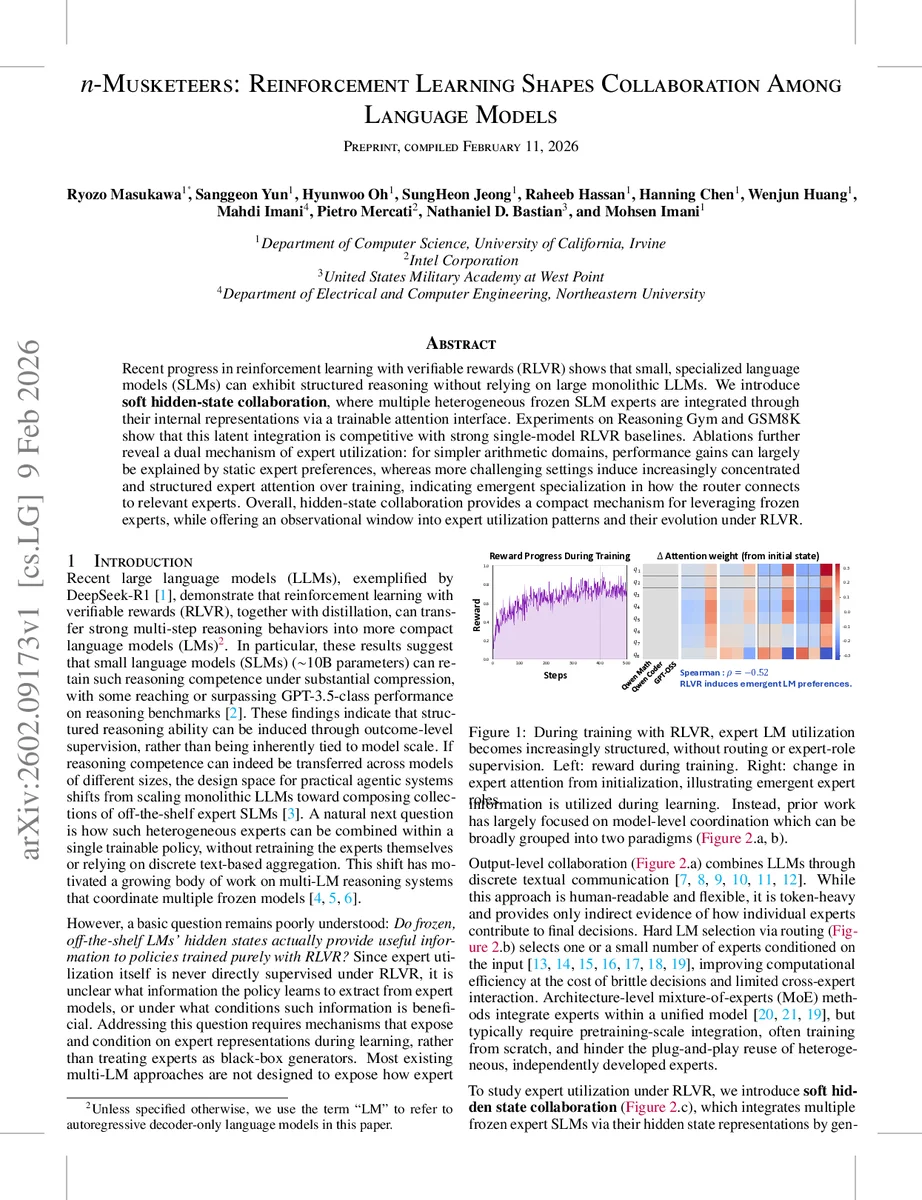
본 논문은 강화학습(RLVR) 환경에서 여러 동결된 소형 언어 모델(SLM)들의 은닉 상태를 교차‑주의(Perceiver) 인터페이스로 연결해 ‘소프트 히든‑스테이트 협업’을 구현한다. 실험 결과는 Reasoning Gym·GSM8K에서 단일 모델 대비 22.9%까지 정확도 향상을 보이며, 학습 과정에서 전문가별 주의 패턴이 자동으로 구조화되고 전문화된 역할을 형성함을 보여준다.
상세 분석
이 연구는 기존의 텍스트‑레벨 협업(전문가 간 대화)과 하드 라우팅(전문가 선택) 방식의 한계를 지적하고, 전문가의 내부 표현을 직접 활용하는 새로운 파이프라인을 제안한다. 구체적으로, 각 동결된 SLM은 입력 프롬프트에 대해 최종 레이어 은닉 벡터를 추출하고, 이를 전문가‑별 선형 프로젝션으로 차원을 맞춘 뒤, 고정된 수량의 라틴 쿼리 벡터와 교차‑주의(Scaled Dot‑Product) 연산을 수행한다. 이 과정에서 라틴 쿼리는 ‘잠재적 프롬프트’ 역할을 하며, 학습 가능한 파라미터(Perceiver‑style 어댑터)로서 RLVR 신호에 의해 최적화된다.
RLVR은 정책 πθ와 어댑터 파라미터 ϕ를 동시에 업데이트함으로써, 전문가 은닉 상태가 실제 과제 성공에 얼마나 기여하는지를 직접적인 보상 신호로 학습한다. 실험에서는 두 가지 현상이 관찰된다. 첫째, 단순 산술 문제에서는 정적 전문가 선호도가 성능 향상의 주요 원인으로 작용한다; 즉, 특정 전문가가 일관되게 높은 가중치를 받는다. 둘째, 복잡한 수학·논리 문제에서는 학습 진행에 따라 주의 분포가 점점 집중되고 구조화되어, 특정 라틴 쿼리가 특정 전문가에 강하게 연결되는 ‘전문가 역할 분화’가 나타난다.
Ablation 연구는 (1) 라틴 쿼리 수와 차원, (2) 풀링 방식(마지막 토큰 vs 평균), (3) 어댑터 초기화(제로 근처) 등을 변형했을 때 성능 변동을 정량화한다. 결과는 라틴 쿼리 기반의 잠재적 프롬프트가 핵심적인 역할을 하며, 전문가 은닉 상태 자체가 직접적인 추론 정보를 제공하기보다는 정책이 활용할 수 있는 보조 신호를 제공한다는 점을 시사한다. 또한, 라우팅이나 텍스트‑레벨 통합 없이도 RLVR이 자동으로 전문가 활용 패턴을 형성한다는 점은, 향후 플러그‑앤‑플레이 형태의 전문가 집합을 효율적으로 관리할 수 있는 가능성을 열어준다.
댓글 및 학술 토론
Loading comments...
의견 남기기