재귀 변환기로 효율적인 대규모 멀티모달 모델 구현
초록
본 논문은 대규모 멀티모달 모델(VLM)의 파라미터를 재사용하는 재귀 구조를 제안한다. 핵심은 (1) 서로 다른 모달리티의 특성을 고려한 “Recursive Connector”로 단계별 특징을 정규화·정렬하고, (2) 모든 재귀 단계에서 성능이 감소하지 않도록 강제하는 “Monotonic Recursion Loss”이다. 실험 결과, 동일 파라미터 수에서 기존 Transformer 대비 3%~7%의 정확도 향상을 달성했으며, 재귀 깊이에 따라 점진적으로 성능이 개선되는 특성 덕분에 저사양 디바이스와 고성능 클라우드 환경 모두에 적합한 적응형 추론이 가능함을 보였다.
상세 분석
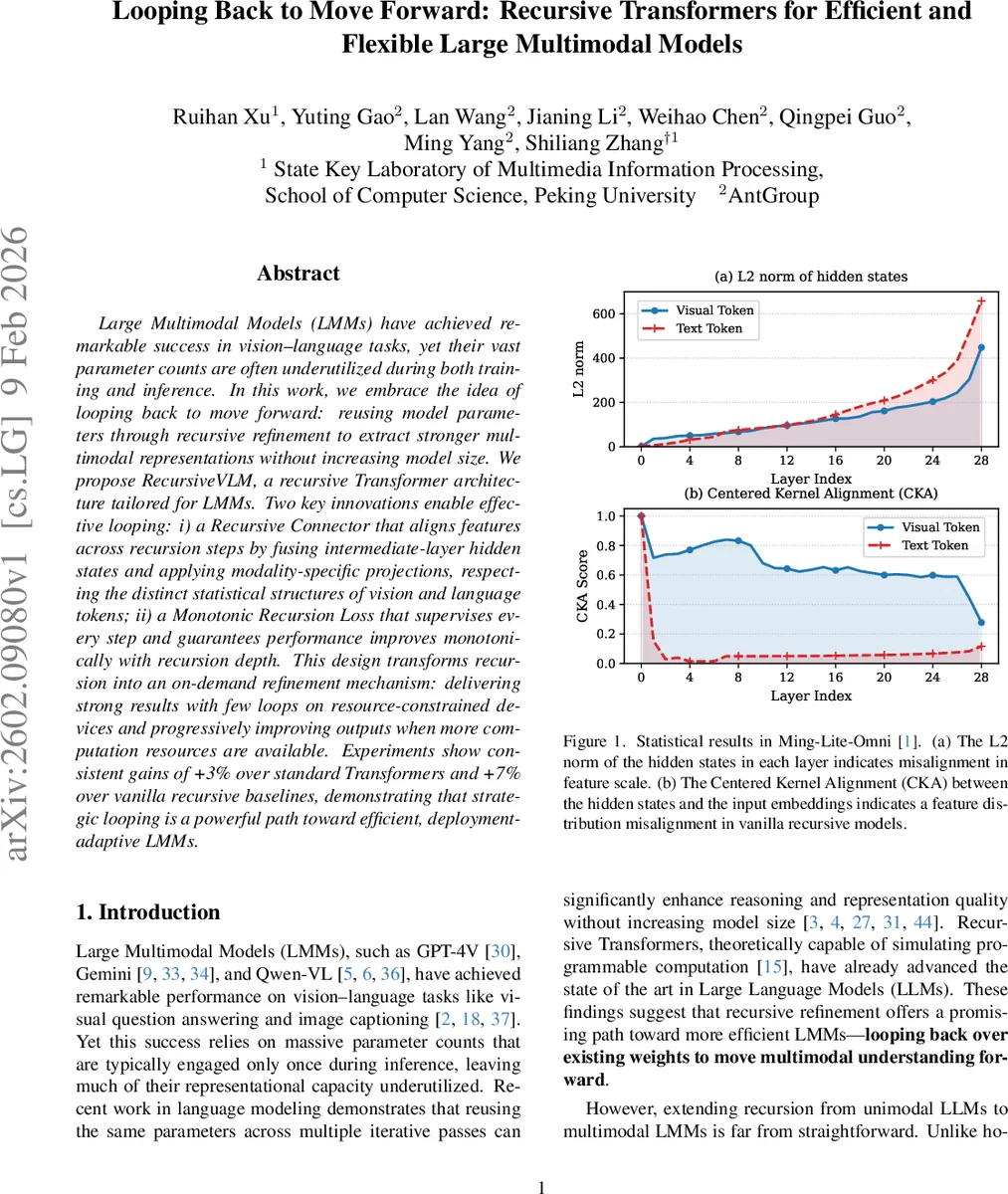
논문은 먼저 대규모 멀티모달 모델이 단일 순전파만 사용해 파라미터 활용도가 낮다는 점을 지적한다. 기존 재귀 Transformer는 텍스트 전용으로 설계돼, 깊은 레이어의 출력과 얕은 레이어 입력 사이에 발생하는 스케일 및 분포 불일치를 그대로 전달한다. 멀티모달 환경에서는 시각 토큰과 언어 토큰이 각각 다른 통계적 특성을 가지므로, 이러한 불일치는 더욱 심각해진다. 이를 해결하기 위해 저자는 “Recursive Connector”를 도입한다. Connector는 선택된 중간 레이어(L/4, 2L/4, 3L/4, L)에서 시각·언어 토큰을 분리한 뒤, 각각 RMSNorm으로 스케일을 정규화하고, 잔차 스케일링 벡터와 두 단계 MLP(up‑projection, down‑projection)를 통해 입력 임베딩 공간으로 매핑한다. 이렇게 하면 깊은 레이어의 풍부한 의미 정보를 유지하면서도 초기 임베딩과 동일한 스케일·분포로 되돌릴 수 있다. 또한, 다중 레이어의 출력을 합산해 원본 입력에 더함으로써 “feature fusion” 효과를 제공한다.
두 번째 핵심은 “Monotonic Recursion Loss”이다. 각 재귀 단계 r에서 언어 모델 헤드의 출력에 대해 교차 엔트로피 손실 L⁽ʳ⁾_CE를 계산하고, 인접 단계 간 토큰별 손실을 비교한다. 현재 단계의 손실이 이전 단계보다 크면 β 배의 패널티를 부여해 손실을 상승시키지 않도록 강제한다. 이 설계는 (1) 모든 단계에서 의미 있는 예측을 가능하게 하고, (2) 재귀 깊이가 증가할수록 성능이 비감소(단조 증가)하도록 보장한다.
학습 초기에는 모든 Connector 파라미터를 0으로 초기화해 첫 번째 재귀 단계가 원본 비재귀 모델과 동일하게 동작하도록 설계하였다. 이는 기존 사전학습된 가중치를 그대로 활용하면서 점진적인 적응을 가능하게 한다. 실험에서는 8개의 대표적인 비전‑언어 벤치마크(VQA, 이미지 캡션 등)에서 표준 Transformer 대비 1‑2%의 개선을 단일 재귀 단계만 사용해 얻었으며, 두 번째 재귀 단계에서는 추가로 +3%의 향상을 기록했다. 또한, 재귀 깊이를 3~4 단계까지 늘려도 성능이 꾸준히 상승했으며, 파라미터 수는 변하지 않아 메모리·연산 효율성 측면에서도 장점을 보였다.
이 논문은 멀티모달 모델에 재귀 구조를 적용할 때 발생하는 “모달리티 간 특징 불일치”와 “단계별 성능 예측 불안정”이라는 두 가지 핵심 문제를 명확히 정의하고, 각각을 해결하는 구체적인 모듈과 손실 함수를 제시함으로써 재귀 기반 적응형 추론의 실용성을 크게 확장한다는 점에서 의의가 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기