행렬 최적화의 새로운 시각: 적응형 회전 최적화(ARO)
초록
ARO는 기울기 회전을 핵심 설계 원칙으로 삼아, 회전된 좌표계에서 정규화된 최급강하를 수행하는 매트릭스 기반 옵티마이저이다. 기존의 직교화·화이트닝 방식과 차별화된 회전 정책을 통해 LLM 사전학습에서 AdamW 대비 1.3배, 기존 행렬 옵티마이저 대비 1.1~1.15배의 샘플 효율성을 달성한다. 또한 전 모델 파라미터에 일관된 업데이트를 적용하고, 교차 레이어·모듈 기하학적 결합을 경제적으로 활용할 수 있도록 설계되었다. 논문은 편향을 최소화한 벤치마크 프로토콜을 제시하고, 회전 대칭 가설을 통해 회전이 왜 효과적인지 이론적 근거를 제공한다.
상세 분석
본 논문은 최근 LLM 훈련에서 주목받는 행렬 기반 옵티마이저들의 핵심 메커니즘을 ‘기울기 회전’으로 재해석하고, 이를 설계 원칙으로 승격시킨다. 기존 방법들(SO‑AP, Muon, SPlus 등)은 모두 특정 행렬(주로 G Gᵀ 또는 G 의 특이값 분해)의 고유벡터를 회전 행렬 R 으로 사용해, Adam과 같은 기본 옵티마이저를 회전된 좌표계에 적용한다. 이때 회전은 고정된 선형 변환에 불과해, 실제 최적화 효율은 f (기본 옵티마이저)의 선택에 크게 의존한다. 논문은 ‘회전 자체가 효율성의 주요 원천’이라는 가설을 실험적으로 검증한다.
ARO는 두 가지 핵심 혁신을 제시한다. 첫째, 회전 행렬 Rₜ 를 고유벡터가 아닌, 현재 fₜ (예: Adam, SignGD, Row‑Normalized GD 등)의 손실 감소율을 직접 최적화하는 정책으로 생성한다. 구체적으로, 논문은 ‘norm‑informed policy’를 도입해 ‖Rₜᵀ Gₜ‖를 최소화하면서도 ‖fₜ(Rₜᵀ Gₜ)‖를 최대한 크게 만든다. 이를 위해 QR 분해 기반의 ‘Shifted Cholesky QR’를 사용해 빠르고 수치적으로 안정적인 정규 직교화를 구현한다. 둘째, 회전 정책을 기본 옵티마이저와 연동시켜 ‘SinkGD’라는 새로운 베이스 옵티마이저를 설계한다. SinkGD는 기존 Adam의 모멘텀·스케일링을 유지하면서, 회전된 공간에서의 스텝 크기를 자동 조정한다.
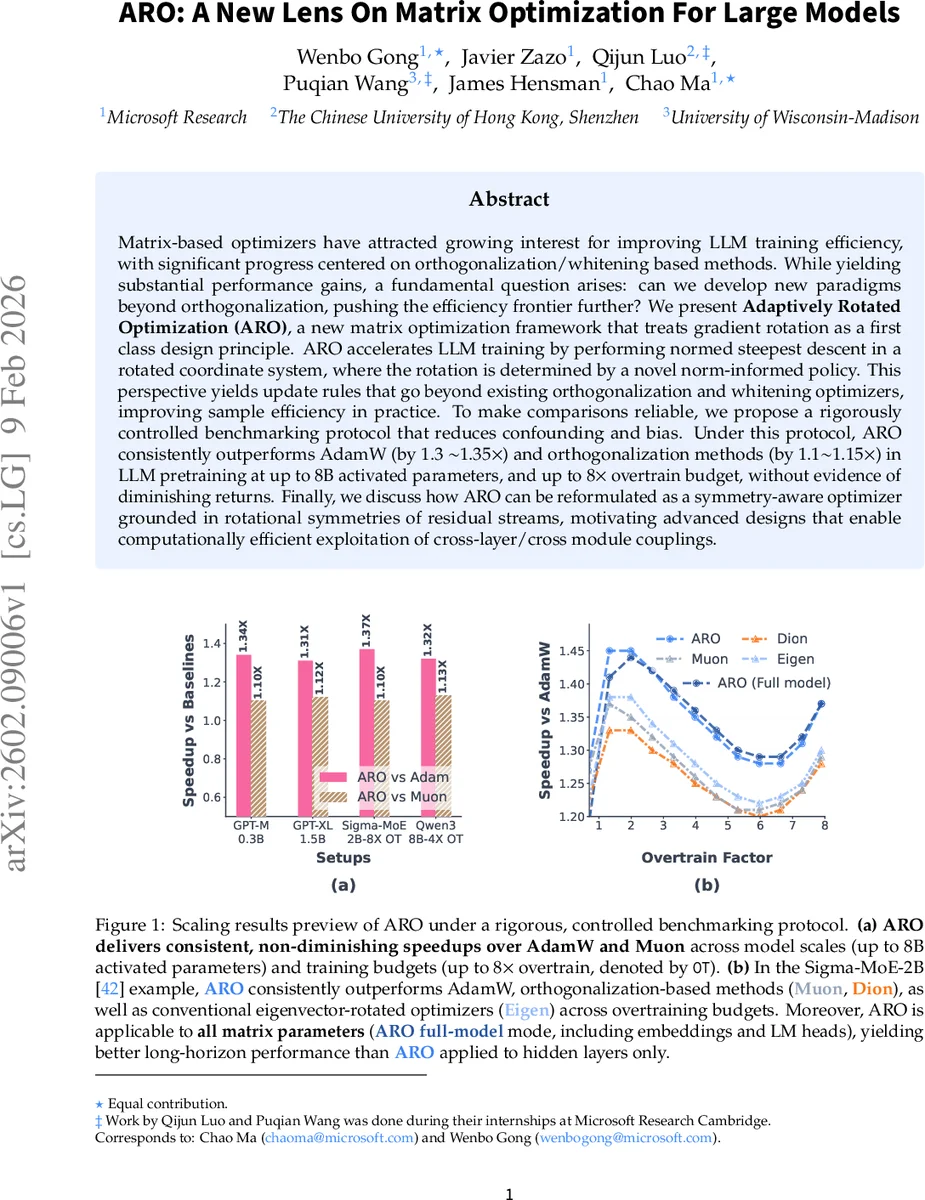
실험 설계는 특히 주목할 만하다. 저자들은 ‘Controlled Benchmarking Protocol’을 정의해, 하이퍼파라미터 튜닝, 학습 스케줄, 데이터 파이프라인 등 모든 변수를 동일하게 맞춘 뒤 비교한다. 이는 최근 보고된 2–3배 속도 향상이 과도한 튜닝에 기인한다는 비판에 대한 직접적인 대응이다. 결과적으로 GPT‑2‑XL(1.5B), Sigma‑MoE‑2B, Qwen‑3‑8B 등 다양한 모델·아키텍처에서 ARO는 AdamW 대비 3035% 학습 시간 절감, 기존 행렬 옵티마이저 대비 1015% 추가 이득을 보였다. 특히 ‘Full‑model’ 모드(임베딩·LM 헤드 포함)에서의 성능 향상이 두드러져, 파라미터 그룹별 다른 옵티마이저를 혼용하던 기존 관행을 탈피한다는 점이 의미 있다.
이론적 논의에서는 회전 대칭 가설을 제시한다. LLM의 잔차 스트림(residual stream)은 층 간 선형 변환에 대해 회전 대칭을 갖는다. 이러한 대칭을 ‘Symmetry Teleportation’이라는 개념으로 형식화하고, ARO의 회전 정책이 이 대칭을 활용해 손실 지형의 등고선을 효과적으로 ‘텔레포트’한다는 설명을 제공한다. 이는 기존 2차 정보(예: Shampoo, K-FAC)의 비용을 회피하면서도, 교차 레이어·모듈 상호작용을 간접적으로 이용한다는 점에서 혁신적이다.
하지만 몇 가지 한계도 존재한다. 회전 행렬을 매 스텝마다 QR 분해로 계산하는 비용은 여전히 O(m²n) 수준이며, 특히 초대형 모델(수십억 파라미터)에서는 메모리·연산 오버헤드가 무시할 수 없다. 논문은 FSDP2·Megatron‑LM과의 분산 구현을 제시하지만, 실제 클라우드 환경에서의 스케일링 효율성에 대한 정량적 분석이 부족하다. 또한 회전 정책이 ‘norm‑informed’라는 점은 특정 정규화(ℓ₂, ℓ∞ 등)에 민감할 수 있어, 비정규화된 데이터나 비정형 손실(예: RLHF)에서는 성능이 어떻게 변할지 추가 연구가 필요하다.
종합하면, ARO는 행렬 기반 최적화의 설계 패러다임을 ‘회전’으로 전환함으로써, 기존 직교화·화이트닝 접근법의 한계를 뛰어넘는 실용적·이론적 프레임워크를 제공한다. 향후 연구는 회전 정책의 경량화, 다양한 베이스 옵티마이저와의 결합, 그리고 대규모 분산 훈련에서의 효율성 검증에 초점을 맞추면 좋을 것이다.
댓글 및 학술 토론
Loading comments...
의견 남기기