다음 개념 예측으로 강화된 언어 모델
초록
Next Concept Prediction(NCP)은 토큰 수준 예측을 넘어 여러 토큰을 아우르는 이산 개념을 예측하도록 설계된 사전학습 목표이다. 저자들은 벡터 양자화(VQ)를 이용해 연속 은닉 상태를 이산 개념 어휘로 변환하고, NCP와 기존 토큰 예측(NTP)을 동시에 학습한다. 70M~1.5B 규모의 모델을 300B 토큰까지 학습한 결과, 13개 벤치마크에서 일관된 성능 향상을 보였으며, 8B Llama 모델에 지속적 사전학습을 적용했을 때도 추가적인 이득을 확인했다. NCP는 더 어려운 학습 과제를 제공함으로써 장기 의존성 학습과 모델 스케일링 효율을 개선한다는 결론을 제시한다.
상세 분석
본 논문은 기존의 토큰‑레벨 사전학습(NTP)이 모델 용량이 커질수록 학습 효율이 포화되는 한계를 지적하고, 이를 극복하기 위한 새로운 목표인 Next Concept Prediction(NCP)을 제안한다. NCP는 “개념”이라는 중간 표현을 도입한다. 개념은 연속 은닉 상태를 평균 풀링으로 압축한 뒤, 여러 개의 독립적인 세그먼트로 분할하고 각각을 별도의 코드북에 양자화함으로써 이산 어휘를 만든다. 이렇게 구성된 개념 어휘는 토큰보다 훨씬 높은 수준의 의미 정보를 담고 있어, 다음 개념을 예측하는 작업은 단일 토큰을 맞추는 것보다 훨씬 더 복잡하고 정보량이 크다.
구조적으로 ConceptLM은 토큰‑레벨 인코더 → 개념‑레벨 모듈 → 토큰‑레벨 디코더 로 이루어진다. 인코더는 토큰 시퀀스를 연속 은닉 표현 h 로 변환하고, 이를 평균 풀링해 길이 T/k 로 압축된 개념 은닉 c 를 만든다. VQ 모듈은 c 를 S개의 세그먼트로 나누어 각각 N개의 코드북 엔트리와 매핑한다. 각 세그먼트마다 독립적인 예측 헤드를 두어 다음 개념의 코드 인덱스 확률분포를 출력하고, 소프트맥스 가중합을 통해 연속적인 예측 개념 \hat{c} 를 재구성한다.
학습 목표는 세 가지 손실의 합이다. (1) L_VQ는 양자화 과정에서 코드북이 은닉 공간을 잘 대표하도록 하는 재구성 손실이며, stop‑gradient 기법을 사용해 양자화 자체가 은닉 표현에 역전파되지 않게 설계했다. (2) L_NCP는 예측된 개념 \hat{c} 와 실제 연속 개념 c 사이의 MSE 손실로, 개념 레벨에서의 예측 정확도를 직접적으로 최적화한다. (3) L_NTP는 기존의 토큰 예측 손실로, \tilde{h} (개념을 토큰 수준에 브로드캐스트하고 0‑패딩을 삽입해 정보 누수를 방지한 후) 를 이용해 다음 토큰을 예측한다. 이 세 손실을 동시에 최소화함으로써 모델은 개념 레벨에서 장기 의존성을 학습하고, 토큰 레벨에서는 세밀한 문법·형태소 정보를 유지한다.
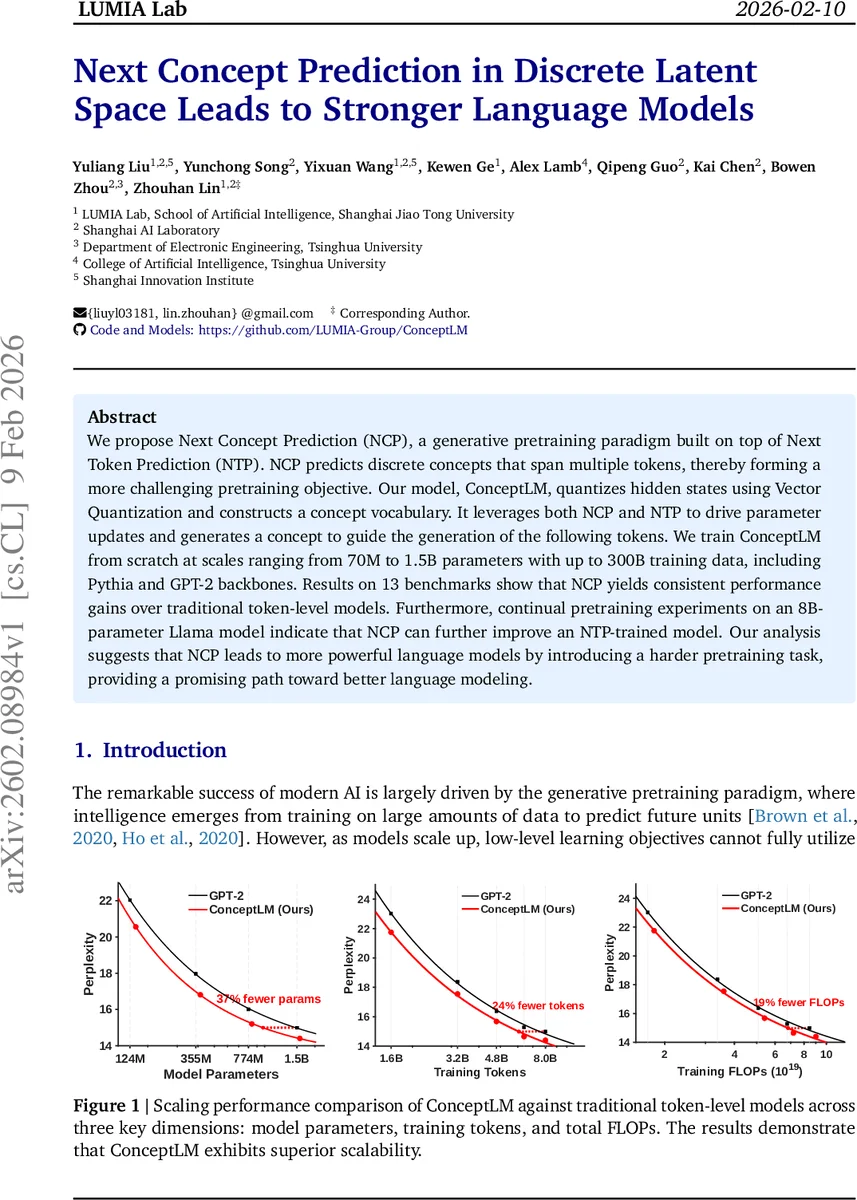
실험에서는 GPT‑2와 Pythia 백본을 각각 70M1.5B 파라미터 규모로 8B300B 토큰까지 학습시켰다. 13개 벤치마크(라바다, ARC, Winogrande, PIQA 등)에서 NCP를 적용한 ConceptLM이 토큰‑레벨 베이스라인보다 평균 5~15% 퍼플렉시티 감소와 정확도 향상을 보였다. 특히 모델 규모가 커질수록 성능 격차가 확대돼, 대규모 모델에서 NCP가 스케일링 효율을 높인다는 점이 강조된다. 또한 8B Llama‑3.1에 9.6B 토큰만 추가 사전학습한 결과, 4개 평가에서 평균 0.4점(≈2% 상대) 상승했으며, 이는 기존 토큰‑레벨 사전학습만으로는 얻기 어려운 이득이다.
분석 파트에서는 NCP가 장기 의존성을 강화한다는 정량적 증거를 제시한다. 개념이 여러 토큰을 포괄하므로, 개념 예측 과정에서 모델은 더 넓은 컨텍스트를 고려하게 되고, 이는 토큰 디코더가 보다 풍부한 전역 정보를 활용하도록 만든다. 또한 VQ 기반 이산 어휘는 제한된 코드북 크기(N=64)에도 불구하고 세그먼트 분할(S≈헤드 수) 덕분에 64^S개의 조합을 제공해 표현력을 크게 확장한다. 이는 기존 토큰 어휘(수십만)와는 다른 차원의 압축‑재구성 메커니즘이며, 학습 효율성 측면에서도 FLOP 대비 성능 향상이 관찰된다.
한계점으로는 개념 압축 비율(k)과 세그먼트 수(S) 선택이 모델 및 데이터에 민감하며, 코드북 업데이트 비용이 추가된다는 점을 들 수 있다. 또한 개념 예측이 잘못될 경우 토큰 디코더에 오류가 전파될 위험이 존재하지만, 논문에서는 MSE 기반 부드러운 지도와 정보 누수 방지를 위한 시프트 기법으로 이를 완화한다는 실험적 근거를 제시한다.
종합하면, NCP는 토큰‑레벨 예측에 개념‑레벨 예측을 결합함으로써 사전학습 목표 자체를 “더 어려운” 과제로 전환하고, 이는 모델의 스케일링 효율, 장기 의존성 학습, 그리고 실제 다운스트림 성능 모두에서 긍정적인 영향을 미친다.
댓글 및 학술 토론
Loading comments...
의견 남기기