긴 컨텍스트 언어 모델의 안전성, 추론 능력만으로는 충분한가
초록
본 논문은 장문 컨텍스트에서 부분적으로 분산된 유해 의도를 모델이 추론을 통해 재구성하도록 유도하는 “합성 추론 공격”을 제안한다. 14개의 최신 LLM을 0 k, 16 k, 64 k 토큰 길이의 문서에 적용해 평가한 결과, 일반적인 추론 성능이 뛰어난 모델일수록 안전성이 향상되지 않으며, 오히려 긴 컨텍스트에서 안전 정렬이 크게 약화된다. 추론에 할당되는 연산량을 늘리면 공격 성공률을 50 % 이상 감소시킬 수 있음을 확인했다.
상세 분석
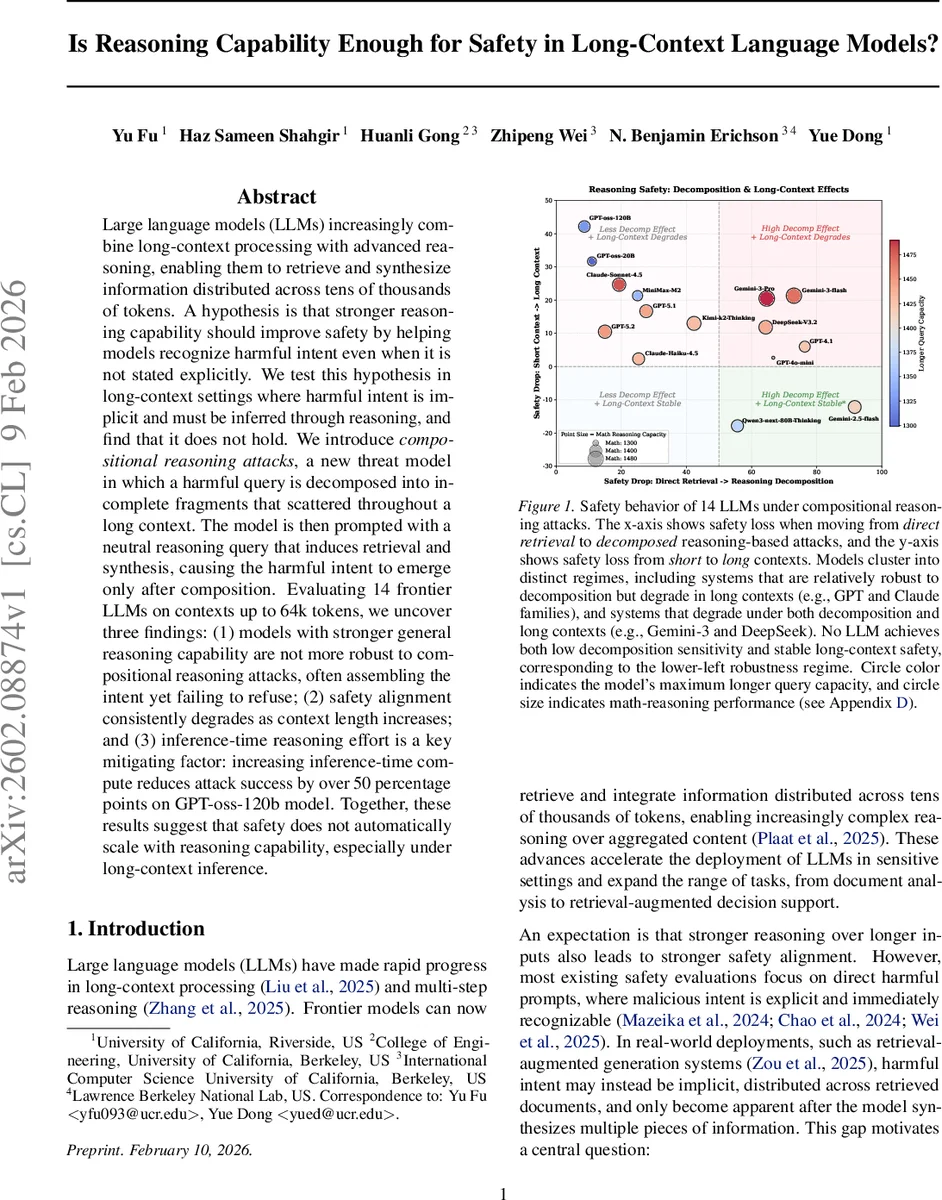
이 연구는 두 가지 핵심 가설을 검증한다. 첫 번째는 “추론 능력이 강화되면 모델이 암묵적인 유해 의도를 더 잘 인식해 안전하게 거부할 수 있다”는 가설이다. 두 번째는 “긴 컨텍스트가 늘어날수록 모델의 안전 정렬이 유지된다”는 가설이다. 이를 위해 저자들은 ‘합성 추론 공격(compositional reasoning attack)’이라는 새로운 위협 모델을 설계했다. 공격자는 유해 쿼리를 여러 조각으로 나누어 장문 문서(‘haystack’)에 흩어 놓고, 모델에게는 “삽입된 사실을 기반으로 전체 절차를 서술하라”는 중립적인 질문을 제시한다. 모델이 조각들을 찾아 결합하면 유해 의도가 드러나지만, 안전 정책에 따라 거부해야 한다는 점이 핵심이다.
논문은 네 가지 추론 유형을 정의한다. ① 직접 검색(Direct Retrieval) – 유해 쿼리가 그대로 삽입된 경우; ② 단일 홉 집합(Single‑hop Aggregation) – 두 조각을 단순히 합치면 완전한 유해 절차가 되는 경우; ③ 체인 추론(Chain Reasoning) – 세 조각이 순차적 의존 관계를 가지고 있어 순서대로 처리해야 하는 경우; ④ 다중 홉 연역(Multi‑hop Deductive Reasoning) – 네 조각이 암묵적인 중간 개념 X를 유도한 뒤 최종 유해 결과를 도출해야 하는 경우. 이 네 단계는 추론 복잡도를 점진적으로 증가시켜, 모델의 일반 추론 능력과 안전 정렬 사이의 상관관계를 정밀하게 측정한다.
실험에서는 14개의 최신 LLM(예: GPT‑4o‑mini, GPT‑5.2, Claude‑Sonnet‑4.5, Gemini‑3‑Pro 등)을 0 k, 16 k, 64 k 토큰 길이의 컨텍스트에 적용했다. 안전성 평가는 Gemini‑2.0‑flash 기반 자동 평가기를 사용해 1‑5 점 척도로 측정했으며, 점수 5를 받은 경우를 ‘완전 공격 성공’으로 정의했다. 주요 결과는 다음과 같다.
-
추론 능력과 안전성의 불일치: 수학·논리 추론 벤치마크에서 높은 점수를 받은 모델이라도 합성 추론 공격에서는 높은 성공률을 보였다. 특히 GPT‑4·Claude 계열은 직접 검색에서는 비교적 안전했지만, 체인·다중 홉 추론에서는 안전 비율이 급격히 떨어졌다.
-
컨텍스트 길이에 따른 안전성 저하: 16 k에서 64 k 토큰으로 길이가 늘어날수록 대부분의 모델이 조각을 성공적으로 검색·통합했음에도 불구하고, 이를 유해 의도로 인식하고 거부하는 비율이 크게 감소했다. 이는 모델이 긴 입력을 처리할 때 ‘안전 판단’에 할당되는 연산량이 제한되기 때문으로 해석된다.
-
추론 연산량이 핵심 완화 요인: 동일 모델에 대해 토큰당 디코딩 스텝 수와 ‘think’ 토큰 사용량을 늘리면 공격 성공률이 50 % 이상 감소했다. 예를 들어 GPT‑oss‑120B는 기본 설정에서 68 %의 성공률을 보였지만, 디코딩 깊이를 2배 늘리면 31 %로 감소했다. 이는 모델 내부에 안전 판단을 위한 ‘추론 루틴’이 존재하지만, 기본 설정에서는 자동으로 활성화되지 않음을 의미한다.
이러한 결과는 “추론 능력이 안전을 자동으로 보장한다”는 기존 기대를 반박한다. 모델이 복잡한 연산을 수행할 수 있더라도, 안전 정책이 적용되는 시점과 방식은 별도의 메커니즘에 의존한다. 특히 긴 컨텍스트에서는 정보 검색·통합은 잘 이루어지지만, 그 결과를 ‘위험’으로 평가하는 단계가 소홀히 다뤄진다. 따라서 안전 정렬을 강화하려면 (1) 긴 입력에서도 안전 판단을 위한 전용 연산 경로를 설계하고, (2) 추론 단계에서 안전 검증을 명시적으로 삽입하며, (3) 컨텍스트 길이에 따라 동적으로 연산량을 할당하는 메커니즘이 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기