안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
본 논문은 비전‑언어 모델(VLM)에서 복잡한 추론 과제에 필요한 자기 교정 능력을 강화하기 위해, 기존 롤아웃을 재조합해 밀집된 교정 샘플을 생성하는 “Octopus” 롤아웃 증강 프레임워크를 제안한다. 응답 마스킹 전략으로 직접 추론과 교정 학습을 분리하고, 7개 벤치마크에서 오픈소스 VLM 중 최고 수준의 성능을 달성하면서 학습 효율도 크게 향상시켰다.
상세 분석
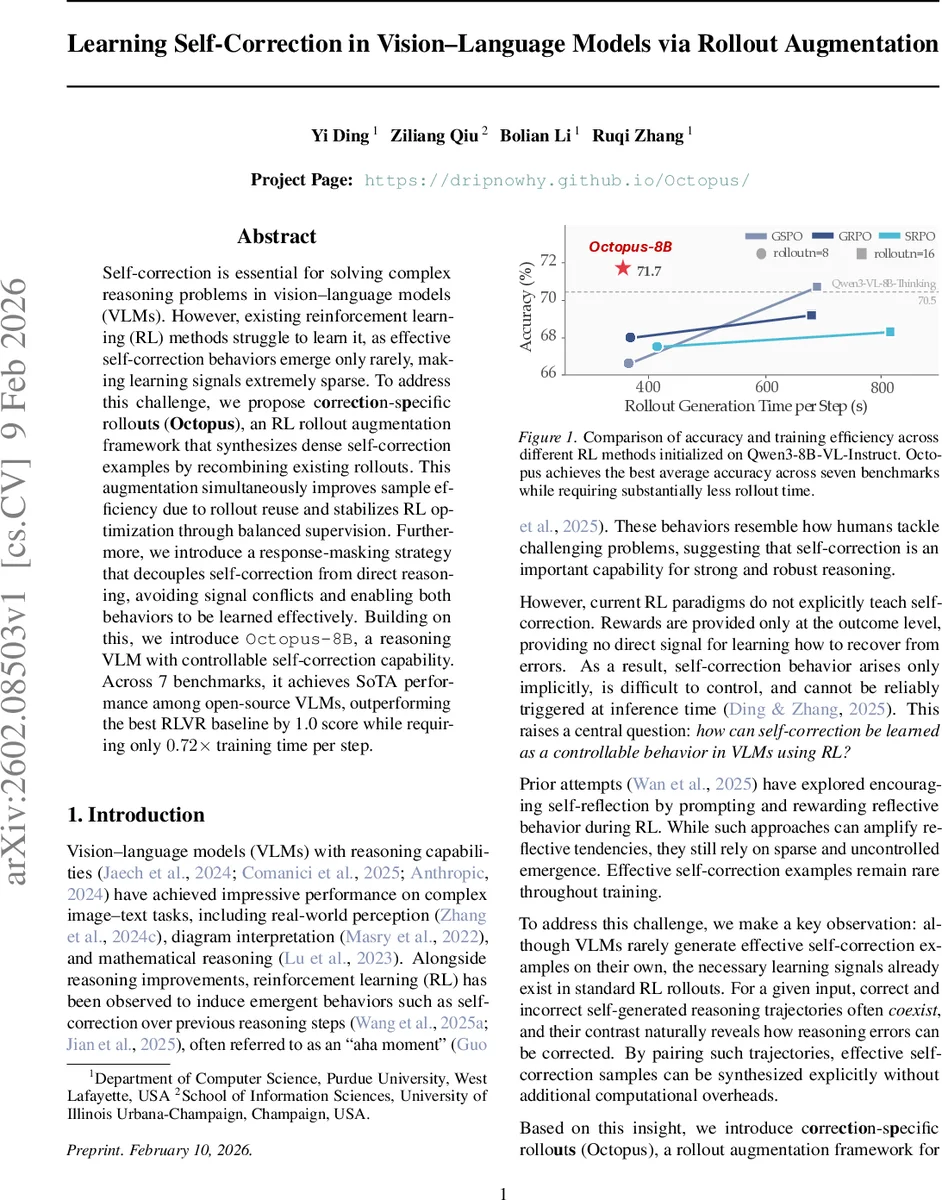
이 논문은 비전‑언어 모델(VLM)의 추론 과정에서 발생하는 오류를 스스로 수정하는 “자기 교정” 능력이 강력한 추론 시스템에 필수적이라는 점을 강조한다. 기존 강화학습(RL) 기반 방법은 최종 정답에만 보상을 주기 때문에, “잘못 → 올바른” 전이 형태의 교정 샘플이 매우 희소하게 나타난다. 저자들은 이러한 희소성을 해결하기 위해 두 가지 핵심 아이디어를 도입한다. 첫째, 동일 입력에 대해 생성된 여러 롤아웃을 재조합해 교정 전후 응답(o₁, o₂)을 짝지음으로써, 실제로는 존재하지 않던 교정 샘플을 인위적으로 만들지만, 이는 기존 롤아웃에서 이미 존재하는 정답·오답 대비 정보를 활용한다는 점에서 데이터 효율성이 높다. 이 과정을 “Octopus”라 명명하고, n개의 원본 롤아웃을 n²개의 조합으로 확장해 학습 배치를 풍부하게 만든다. 둘째, 교정 토큰() 이후의 응답과 교정 전 응답이 서로 다른 학습 신호를 제공한다는 점에서 충돌이 발생한다. 이를 해결하기 위해 “응답 마스킹” 전략을 제시한다. 구체적으로, 교정 전 응답(o₁)은 KL 정규화와 마스크를 적용해 직접 추론 신호와 분리하고, 교정 후 응답(o₂)만을 최종 보상에 연결한다. 이렇게 하면 모델이 “정답을 먼저 말한다”와 “오답을 교정한다” 두 행동을 독립적으로 최적화할 수 있다. 실험에서는 Qwen‑3‑VL‑8B‑Instruct를 베이스로 Octopus‑8B를 학습시켰으며, 7개의 복합 추론 벤치마크(수학, 도표 해석, 이미지‑텍스트 상호작용 등)에서 기존 RLVR 및 GSPO 대비 평균 정확도 1.0점 이상 향상시켰다. 특히, 롤아웃당 학습 시간은 0.72배로 감소해 샘플 효율성도 크게 개선되었다. 추가 실험에서는 “콜드 스타트” 단계에서 자체 교정 포맷을 학습시키는 것이 중요함을 확인했으며, “혼합 샘플링”(정책 모델이 생성한 o₁과 더 강력한 교정 모델이 생성한 o₂) 방식이 엔트로피 붕괴를 방지해 안정적인 RL 학습을 가능하게 한다. 전체적으로 이 논문은 교정 샘플의 희소성을 데이터 재구성을 통해 근본적으로 해결하고, 학습 신호의 충돌을 마스킹으로 해소함으로써 VLM의 자기 교정 능력을 실용적인 수준으로 끌어올렸다. 다만, 현재는 단일 패스 교정만을 다루며, 다중 단계 교정이나 외부 도구와의 연계에 대한 탐색은 향후 과제로 남는다.
댓글 및 학술 토론
Loading comments...
의견 남기기