LycheeMemory: 압축 메모리와 강화학습으로 구현하는 초장문 추론
초록
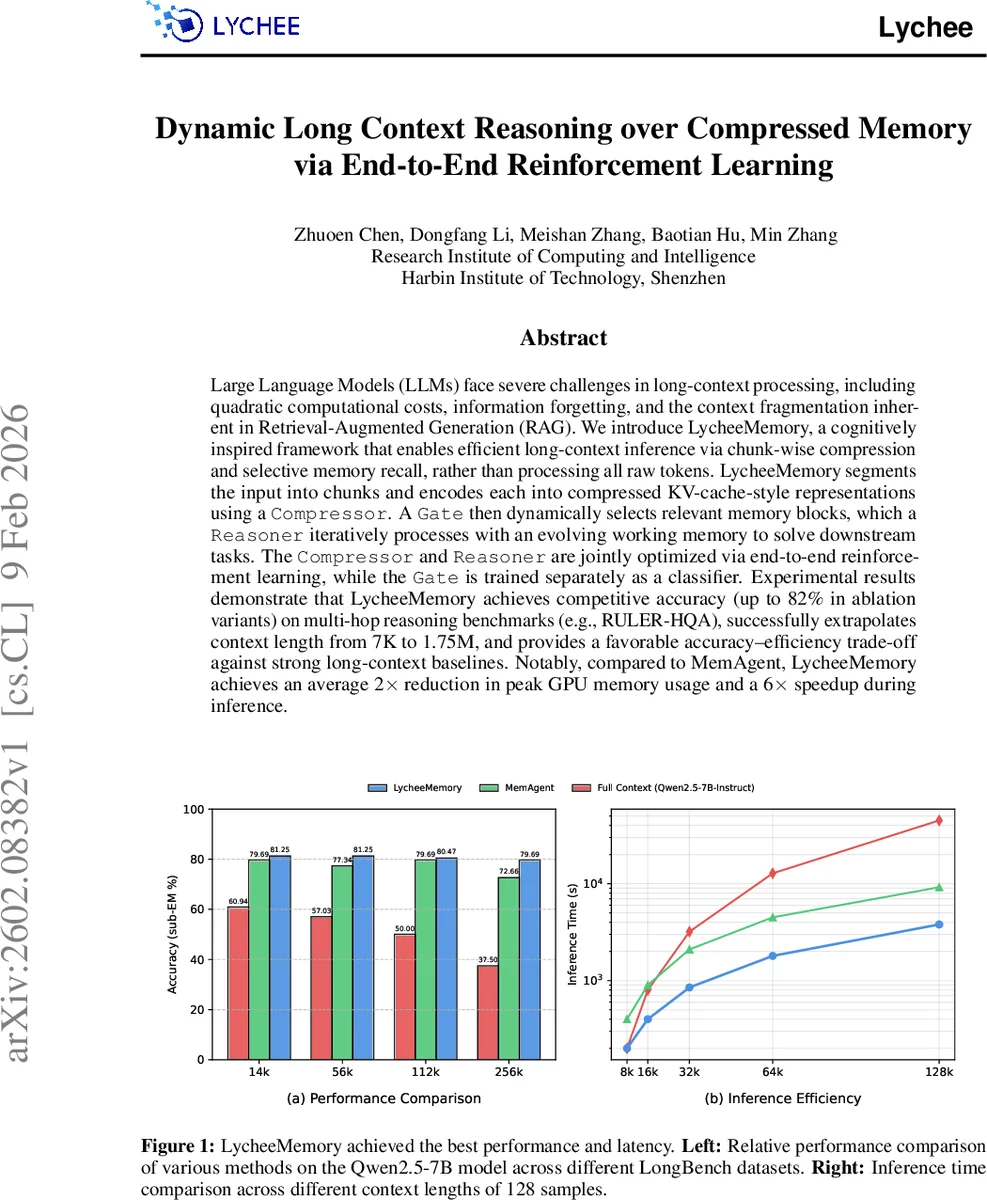
LycheeMemory는 긴 텍스트를 청크 단위로 압축하고, 동적 게이트와 추론 모듈을 통해 선택적으로 기억을 불러와 작업 메모리를 갱신한다. 압축기와 추론기를 강화학습으로 공동 최적화하고, 게이트는 별도 분류기로 학습한다. 실험에서 7K 토큰에서 1.75M 토큰까지 확장하면서도 정확도는 유지하고, MemAgent 대비 GPU 메모리 사용량을 2배 절감하고 추론 속도를 6배 가속한다.
상세 분석
LycheeMemory는 인간의 장기·단기 기억 구조를 모방한 두 단계 시스템을 제안한다. 첫 단계인 압축기(Compressor)는 기존 LLM에 LoRA 기반 압축 모듈을 삽입해 입력 청크를 KV‑cache 형태의 압축 토큰 집합으로 변환한다. 이때 청크당 압축 비율 α를 사전에 정의하고, 원본 토큰 사이에 메모리 토큰을 삽입해 단일 순전파만으로 의미를 집약한다. 압축 토큰의 은닉 상태를 저장함으로써 원본 텍스트의 핵심 정보를 고밀도로 보존하면서도 토큰 수를 크게 줄인다.
두 번째 단계는 동적 게이트와 추론기(Reasoner)이다. 게이트는 현재 작업 메모리와 사용자 질의 Q를 조건으로 각 압축 블록 θ_i의 relevance 점수를 산출한다. 점수가 사전 정의된 임계값 τ를 초과하면 추론기가 호출되어 θ_i와 Q, 현재 작업 메모리 m_t를 입력으로 새로운 작업 메모리 m_{t+1}=Φ_reason(m_t,θ_i,Q)를 생성한다. 이렇게 선택적 업데이트를 반복함으로써 모델은 필요 없는 청크를 건너뛰고, 다중 홉 추론에 필요한 증거만 순차적으로 통합한다. 작업 메모리는 실제 토큰 시퀀스로 유지돼, 추론 과정이 명시적이고 해석 가능하도록 만든다.
학습 측면에서 압축기와 추론기는 공동 정책(policy)으로 정의되어 강화학습(RL) 프레임워크에서 최적화된다. 보상은 최종 QA 정확도와 압축 효율성을 동시에 고려하도록 설계되었으며, 정책 그래디언트 방식으로 파라미터를 업데이트한다. 게이트는 별도 이진 분류기로 사전 학습된 데이터(청크‑질의 매칭)로 학습되며, RL 루프와는 독립적으로 동작한다. 이 설계는 압축 단계와 선택적 기억 회수 단계 사이의 목표 불일치를 완화하고, 압축된 표현이 downstream task에 직접 활용될 수 있게 만든다.
복잡도 분석에서는 전체 FLOPs가 O(K·sz·α^{-1}) 수준으로 감소함을 보이며, 메모리 사용량은 KV‑cache 크기와 압축 비율에 비례한다. 실험에서는 Qwen2.5‑7B‑Instruct 기반 모델에 적용했으며, RULER‑HQA, WikiMultihopQA, StreamingQA 등 멀티홉 베이스라인에서 경쟁력 있는 정확도를 기록했다. 특히 7K→1.75M 토큰 확장 실험에서 정확도 저하가 미미했으며, MemAgent 대비 GPU 피크 메모리를 2배, 추론 시간을 6배 단축했다.
오류 분석에서는 압축으로 인한 의미 손실(17%), 단계적 의존성 불일치(35%), 조기 추론 고정(21%) 등이 주요 실패 원인으로 지적되었다. 이를 완화하기 위해 압축 비율을 동적으로 조정하거나, 게이트의 상태 의존성을 강화하는 방안이 제안된다. 전체적으로 LycheeMemory는 압축 메모리와 강화학습 기반 정책 최적화를 결합해 초장문 추론의 효율성과 정확도 사이의 트레이드오프를 크게 개선한 혁신적인 프레임워크라 할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기