분산 블록체인 기반 LLM 평가 프레임워크 인피코이밸체인
초록
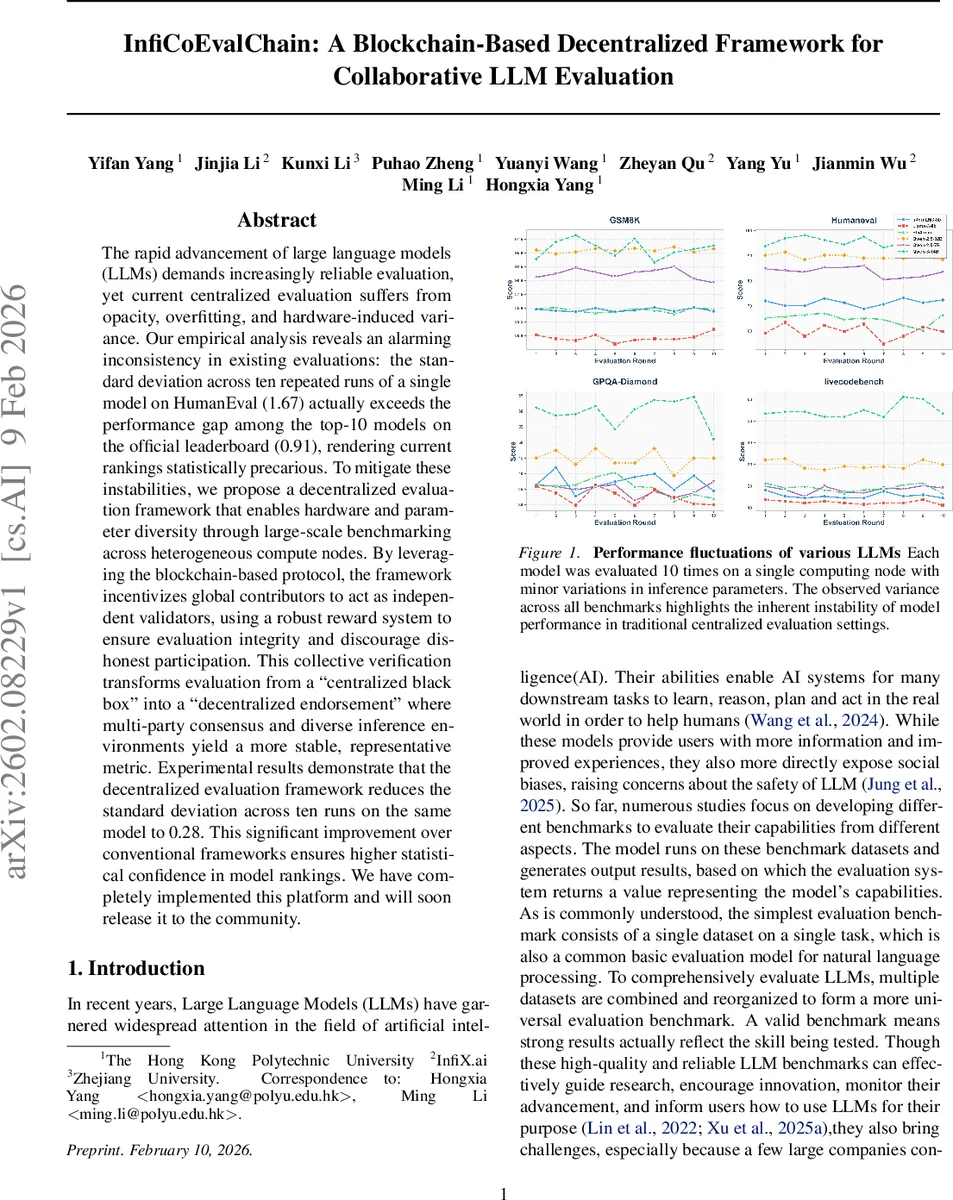
본 논문은 대형 언어 모델(LLM)의 평가가 하드웨어·시드 변동으로 인해 통계적으로 불안정함을 지적하고, 블록체인 기반의 분산 평가 시스템인 InfiCoEvalChain을 제안한다. 다양한 컴퓨팅 노드를 활용해 다중 실행을 수행하고, 토큰 스테이킹·커밋‑리빌 공개 방식을 통한 합의 메커니즘으로 결과 위변조를 방지한다. 실험 결과, 동일 모델을 10회 반복 평가했을 때 표준편차가 1.67에서 0.28로 크게 감소함을 보여, 보다 신뢰할 수 있는 모델 순위를 제공한다.
상세 분석
논문은 먼저 현재 중앙집중식 LLM 벤치마크가 “통계적 취약성”을 가지고 있음을 실증한다. HumanEval에서 동일 모델을 동일 환경에서 10번 실행했을 때 표준편차가 1.67에 달했으며, 이는 공식 리더보드 상위 10개 모델 간 성능 격차(0.91)보다 크게 앞선 수치다. 즉, 기존 순위는 환경 노이즈에 크게 좌우될 위험이 있다. 이를 해결하기 위해 저자들은 두 가지 핵심 설계를 제시한다. 첫째, 평가를 다수의 이질적인 하드웨어·GPU·인퍼런스 파라미터에서 동시에 수행함으로써 샘플링 노이즈를 평균화한다. 통계적 분석에서는 중앙극한정리를 적용해 신뢰구간을 95%로 확보하려면 최소 28개의 독립 실행이 필요함을 도출한다(ε=0.04, δ=0.2). 둘째, 블록체인 레이어를 도입해 투명하고 변조 불가능한 기록을 보장한다. 참여자는 토큰을 스테이킹해 Sybil 공격을 방지하고, 커밋‑리빌 스킴을 통해 평가 결과를 사전 공개 없이 안전하게 제출한다. 합의 메커니즘은 Schelling Point 게임이론을 차용해, 다수 노드가 동일 점수를 “자연스러운” 정답으로 인식하도록 설계되었다. 보상·벌점 구조는 정확한 결과를 제공한 노드에 토큰을 지급하고, 위조·복제 시 패널티를 부과한다. 실험에서는 다양한 모델(GSM8K, HumanEval, GPQA‑Diamond, LiveCodeBench)과 여러 하드웨어 구성을 활용해 10회 반복 평가 시 표준편차를 0.28로 낮추었다. 이는 기존 중앙식 프레임워크 대비 5배 이상 개선된 수치이며, 모델 간 실질적인 성능 차이를 통계적으로 구분할 수 있게 만든다. 구현된 프로토타입은 퍼블릭 블록체인 위에 스마트 계약으로 구축되었으며, 향후 오픈소스로 공개될 예정이다. 전체 설계는 평가의 투명성, 재현성, 공정성을 동시에 달성하려는 목표를 갖는다.
댓글 및 학술 토론
Loading comments...
의견 남기기