비전 트랜스포머 파인튜닝, 비스무스 구성요소가 성능을 끌어올린다
초록
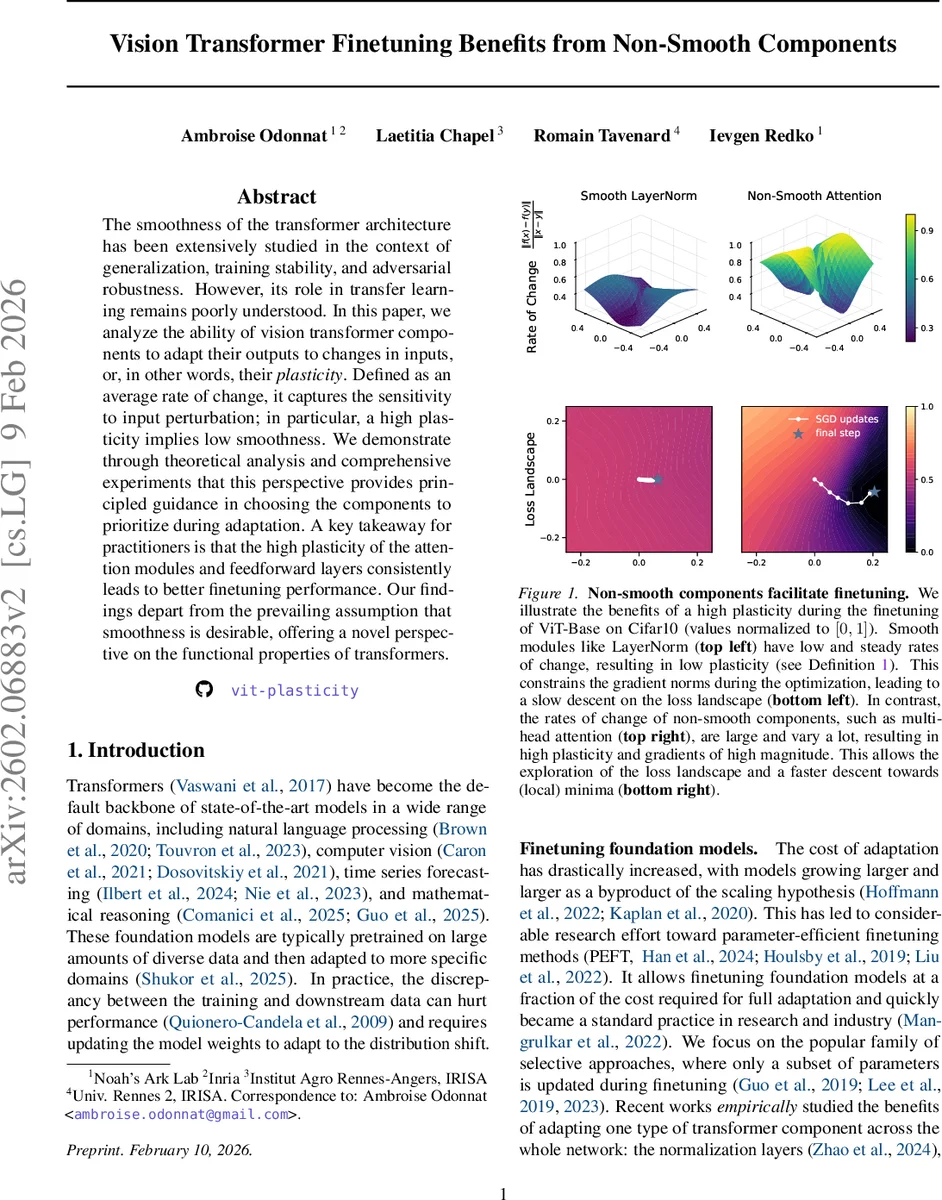
본 논문은 비전 트랜스포머(ViT)에서 각 모듈의 “플라스틱성”(입력 변화에 대한 평균 변화율)을 정의하고, 플라스틱성이 높은 비스무스(비부드러운) 모듈—특히 멀티헤드 어텐션과 피드포워드 레이어—가 파인튜닝 시 더 큰 성능 향상을 제공한다는 이론적·실험적 근거를 제시한다. 기존의 부드러움(스무스) 강조와는 달리, 높은 플라스틱성을 가진 모듈은 큰 그래디언트와 빠른 손실 감소를 가능하게 하여 적은 파라미터 업데이트만으로도 효과적인 적응을 이끈다.
상세 분석
논문은 먼저 “플라스틱성”을 수학적으로 정의한다. 입력 토큰 쌍 (x, y)에 대해 ‖f(x)‑f(y)‖/‖x‑y‖의 평균값을 기대값으로 취한 것이 플라스틱성 P(f)이며, 이는 해당 모듈의 Lipschitz 상수 Lip(f)의 하한이다. P(f) > 1이면 평균적으로 입력 변동을 증폭시켜 비스무스, P(f) < 1이면 수축시켜 스무스한 특성을 가진다.
이 정의를 바탕으로 저자들은 세 종류의 모듈에 대해 상한을 도출한다.
- LayerNorm: P ≤ (‖γ‖∞)/(σ·) 로, 정규화 파라미터와 최소 표준편차에 의해 제한되어 플라스틱성이 가장 낮다.
- Feedforward(FC) 레이어: P ≤ ‖W‖₂ 로, 가중치 행렬의 스펙트럼 노름에 비례한다. 일반적으로 큰 차원 확대(4d)와 가중치 초기화 때문에 비교적 높은 플라스틱성을 가진다.
- Multi‑Head Self‑Attention(MHA): 복잡한 상한식 P ≤ Σ_h‖O_h‖₂‖V_h‖₂·q·n + (12n+3)r⁴‖A_h‖₂² 로, 헤드 수 H, 출력/값 가중치, 토큰 길이 n, 입력 토큰의 반경 r 등에 의존한다. 실험적으로 토큰이 정규화된 이미지 임베딩에 의해 제한되므로 이 상한은 실제 플라스틱성에 근접한다.
이론적 결과는 “어텐션 > 첫 번째 피드포워드 > 두 번째 피드포워드 > LayerNorm(전) > LayerNorm(후)” 순으로 플라스틱성이 높음을 예측한다.
실험에서는 86 M 파라미터 ViT‑Base을 CIFAR‑10, ImageNet‑R, VTAB‑1k 등 11개 베치마크에 대해 각 모듈을 독립적으로 파인튜닝한다. 결과는 플라스틱성이 높은 모듈을 업데이트했을 때 학습 곡선이 급격히 하강하고, 최종 정확도가 크게 향상됨을 보여준다. 특히 어텐션과 피드포워드 레이어는 학습률과 초기화에 대한 민감도가 낮아 안정적인 성능을 제공한다. 반면 LayerNorm만을 업데이트하면 그래디언트 크기가 작아 수렴이 느리고, 최종 성능이 크게 개선되지 않는다.
또한, 플라스틱성 측정값을 전체 베치마크에 평균하면 어텐션이 가장 높은 값을 기록하고, 이는 실제 파인튜닝 이득과 높은 상관관계를 보인다. 저자들은 이 현상을 “플라스틱성이 높은 모듈은 입력 변동을 증폭시켜 파라미터 공간에서 더 넓은 탐색을 가능하게 한다”는 직관으로 해석한다.
이러한 발견은 기존의 “스무스함을 높여 일반화·안정성을 개선한다”는 관점과는 정반대이며, 파인튜닝 단계에서는 오히려 비스무스한 특성을 활용해 빠른 적응을 도모해야 함을 시사한다. 이는 PEFT(파라미터 효율적 파인튜닝) 설계 시 어떤 모듈을 선택할지에 대한 새로운 이론적 근거를 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기