대규모 GPU 클러스터 LLM 학습 이상 진단 프레임워크 Flare
초록
Flare는 6,000대 이상의 GPU를 운영하는 대규모 LLM 학습 환경에서 발생하는 성능 저하와 오류를 실시간으로 추적·진단하는 경량 트레이싱 데몬과 자동 진단 엔진으로 구성된 프레임워크이다. Python·C++ 양쪽 런타임을 비침투적으로 계측하고, 백엔드 확장성을 확보하면서도 평균 0.43% 이하의 오버헤드만 발생한다. 매크로·마이크로 지표를 결합해 성능 회귀와 급격한 슬로우다운을 구분하고, 원인 모듈을 자동으로 추출한다. 8개월 이상 6,000 GPU에 지속 배포돼 실제 운영 효율을 크게 향상시켰다.
상세 분석
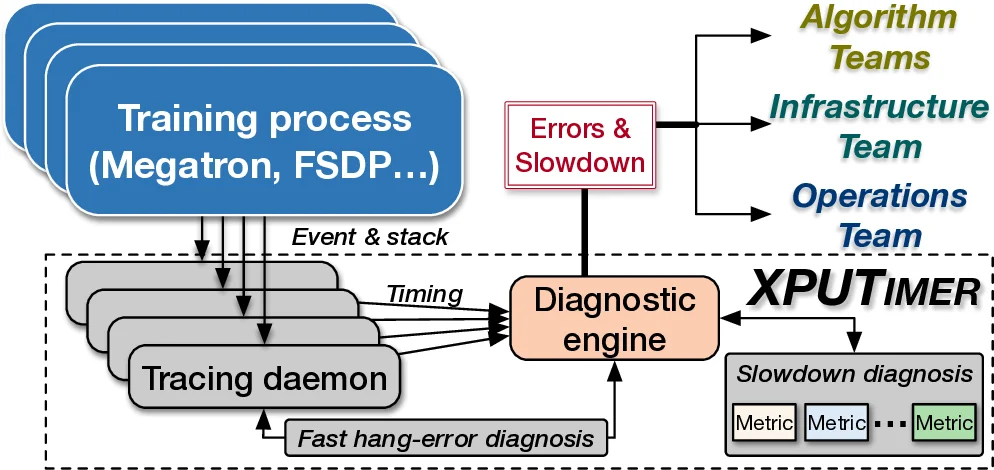
Flare는 대규모 LLM 학습에서 흔히 발생하는 세 가지 이상 유형—오류, 급격한 슬로우다운(fail‑slow), 지속적인 성능 회귀(regression)—을 통합적으로 다루기 위해 설계되었다. 핵심은 두 가지 컴포넌트, 즉 트레이싱 데몬과 진단 엔진이다. 트레이싱 데몬은 CPython의 tracing API를 활용해 Python 레이어의 함수 호출과 스택 정보를 실시간으로 캡처한다. 이는 기존 백엔드 코드에 패치를 가하거나 침투적인 프로파일링 툴(CUPTI 등)을 사용하는 방식과 달리, 백엔드‑별로 별도 수정 없이 플러그인 형태로 확장 가능하도록 설계되었다. 또한 C++ 런타임에서는 핵심 연산 라이브러리(cuBLAS, FlashAttention, NCCL 등)의 API 호출과 커널 실행 이벤트를 선택적으로 인터셉트해 최소한의 메모리 로그(GPU당 평균 1.5 MB)만을 생성한다.
진단 엔진은 빠른 오류 진단과 성능 회귀 탐지 두 축으로 동작한다. 오류 진단은 NCCL 통신 오류와 같은 hang 상황을 O(1) 복잡도로 파악하기 위해 intra‑kernel 검사 메커니즘을 도입했으며, 이는 기존의 블랙박스 NCCL 테스트와 달리 전체 클러스터를 순회하지 않고도 문제 노드를 즉시 식별한다. 성능 회귀 탐지는 전통적인 매크로 지표(전체 학습 throughput)만으로는 감지하기 어려운 미세 지표들을 도입함으로써 가능해졌다. 구체적으로 issue latency distribution, kernel execution time variance, Python GC 호출 빈도 등을 실시간 집계해 기준선과 비교한다. 이러한 마이크로 지표는 알고리즘 팀이 도입한 불필요한 동기화나 인프라 팀이 최적화하지 못한 커스텀 OP를 빠르게 드러낸다.
운영 평가에서는 1024 H800 GPU 환경에서 다양한 LLM(FSDP, Megatron, DeepSpeed 등)과 백엔드 조합에 대해 평균 0.43 %의 런타임 오버헤드만을 기록했으며, 1536 GPU 규모의 실제 모델 학습에서는 GPU당 1.5 MB 수준의 로그만을 생성했다. 6,000 GPU에 8개월 이상 지속 배포된 결과, 기존에 평균 2 시간 이상 소요되던 성능 회귀 원인 분석이 몇 분 내에 자동으로 완료되는 등 운영 효율이 크게 개선되었다.
Flare는 기존 도구(Greyhound, C4D, Holmes, MegaScale 등)가 각각 오류·fail‑slow 혹은 특정 백엔드에 국한된 반면, 전체 스택을 포괄하면서도 백엔드 독립적인 계측을 제공한다는 점에서 차별화된다. 또한 자동화된 원인 추출 파이프라인을 통해 팀 간 협업 비용을 최소화하고, 인프라·알고리즘 팀이 독립적으로 문제를 해결하도록 지원한다. 이러한 설계 철학은 대규모 GPU 클러스터 운영에서 반복적인 이상 대응을 자동화하고, 모델 개발 속도를 가속화하는 데 핵심적인 역할을 한다.
댓글 및 학술 토론
Loading comments...
의견 남기기