잠재 추론 모델의 자발적 탐색과 역추적
초록
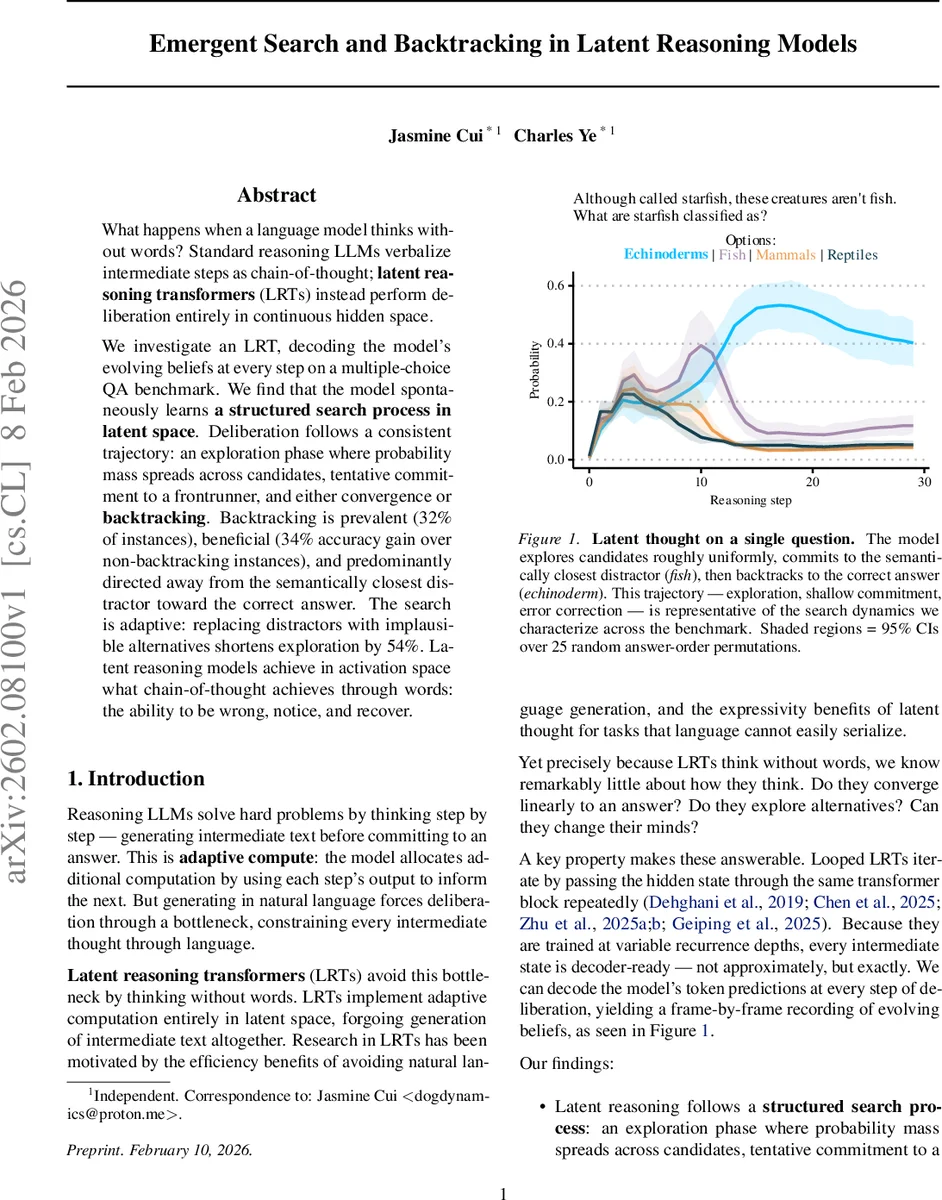
본 논문은 3.5 B 파라미터 루프형 잠재 추론 변환기(LRT)를 260개의 4선형 객관식 QA에 적용해, 매 반복 단계마다 디코더를 통해 예측 분포를 추출함으로써 모델의 내부 사고 과정을 시각화한다. 모델은 초기 탐색 단계에서 후보에 확률을 고르게 분산시키고, 얕은 의미 유사성에 기반해 가장 근접한 오답에 일시적으로 몰입한다. 이후 뒤로 돌아가(역추적) 올바른 정답으로 교정하는 과정을 보이며, 전체 32 %의 사례에서 역추적이 발생하고 이는 정확도를 34 % 향상시킨다. 난이도가 낮은 경우 탐색 단계가 짧아지는 등, 모델이 과제 난이도에 따라 적응적 검색을 수행한다는 점을 확인한다.
상세 분석
본 연구는 루프형 잠재 추론 변환기(LRT)의 내부 동작을 단계별로 해석하는 데 초점을 맞춘다. 모델은 프리루드(P) → 반복 블록(R) → 코다(C) 구조로 구성되며, R 블록이 K = 30번 반복될 때마다 중간 은닉 상태 h_i를 코다에 통과시켜 정확한 확률 분포 p_i = softmax(C(h_i))를 얻는다. 이렇게 얻은 p_i는 모델이 해당 단계에서 멈추었을 경우 실제 출력할 확률이며, 따라서 중간 단계의 신념 변화를 직접 관찰할 수 있다.
실험은 260개의 질문을 ‘Base’, ‘Easy’, ‘No correct answer’ 세 변형으로 구성하고, 각 변형마다 정답 순서를 25가지 무작위로 섞어 위치 편향을 제거한다. 결과는 크게 세 단계의 검색 패턴을 보여준다. 첫 번째 ‘탐색 단계’에서는 KL‑다이버전스가 높은 상태로 확률 질량이 고르게 퍼지며, 이는 모델이 후보들을 동등하게 고려하고 있음을 의미한다. 두 번째 ‘얕은 커밋 단계’에서는 질문과 의미적으로 가장 가까운 오답(예: ‘물고기’)에 확률이 집중되는데, 이는 표면적인 임베딩 매칭에 의존하는 초기 필터링 메커니즘으로 해석된다. 세 번째 ‘수렴 또는 역추적 단계’에서는 모델이 기존 커밋을 유지하거나, 최소 3스텝 연속으로 최고 확률을 차지하던 답을 포기하고 다른 후보로 전환한다. 역추적은 전체 사례의 32 %에서 관찰되었으며, 이때 포기된 답은 가장 의미적으로 가까운 오답일 확률이 72 %에 달한다(우연적 25 % 대비). 역추적이 발생한 경우 정답 정확도가 34 % 상승하는 등, 실제 오류 교정 메커니즘으로 작동한다는 증거가 된다.
난이도 조절 실험에서는 ‘Easy’ 변형이 ‘Base’보다 평균 54 % 적은 탐색 스텝을 필요로 함을 KL‑다이버전스 기반 탐색 종료 기준으로 확인하였다. 또한 ‘No correct answer’ 변형에서는 엔트로피가 전체 30스텝 동안 높은 수준을 유지해, 모델이 유효한 정답이 없을 때는 수렴하지 않고 불확실성을 유지한다는 점을 보여준다. 이러한 결과는 LRT가 외부 언어적 제약 없이 내부적으로 탐색‑필터‑교정이라는 두 단계의 연산 흐름을 자발적으로 학습한다는 강력한 증거가 된다.
본 논문은 LRT가 기존 체인‑오브‑생각(CoT) 방식과 유사한 ‘생각의 구조’를 내재하고 있음을 제시한다. CoT는 텍스트를 생성하면서 동시에 내부 검색을 수행하지만, 언어적 병목으로 인해 중간 사고가 왜곡될 수 있다. 반면 LRT는 모든 중간 상태가 직접 디코딩 가능하므로, 모델의 실제 추론 과정을 투명하게 관찰할 수 있다. 이는 적응형 계산(adaptive compute) 메커니즘을 이해하고, 향후 더 큰 규모의 LRT나 비루프형 적응형 아키텍처에 적용할 때 중요한 설계 인사이트를 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기