하이퍼볼릭 밀집 검색으로 RAG 성능 혁신
초록
본 논문은 텍스트 임베딩을 유클리드 공간이 아닌 로렌츠 모델의 하이퍼볼릭 공간에 매핑함으로써 계층적 의미 구조를 보존한다. 완전 하이퍼볼릭 변환기(HyTE‑FH)와 유클리드 사전학습 모델을 하이퍼볼릭으로 투사하는 하이브리드 모델(HyTE‑H)을 제안하고, 토큰 집합을 문서 임베딩으로 집계할 때 계층 손실을 방지하는 ‘Outward Einstein Midpoint’ 풀링 연산을 도입한다. 실험 결과, 두 모델 모두 기존 유클리드 기반 리트리버를 크게 능가하며, 특히 HyTE‑H는 모델 크기를 2‑3배 줄이면서도 RAGBench에서 문맥·답변 관련성에서 최대 29% 향상을 달성한다.
상세 분석
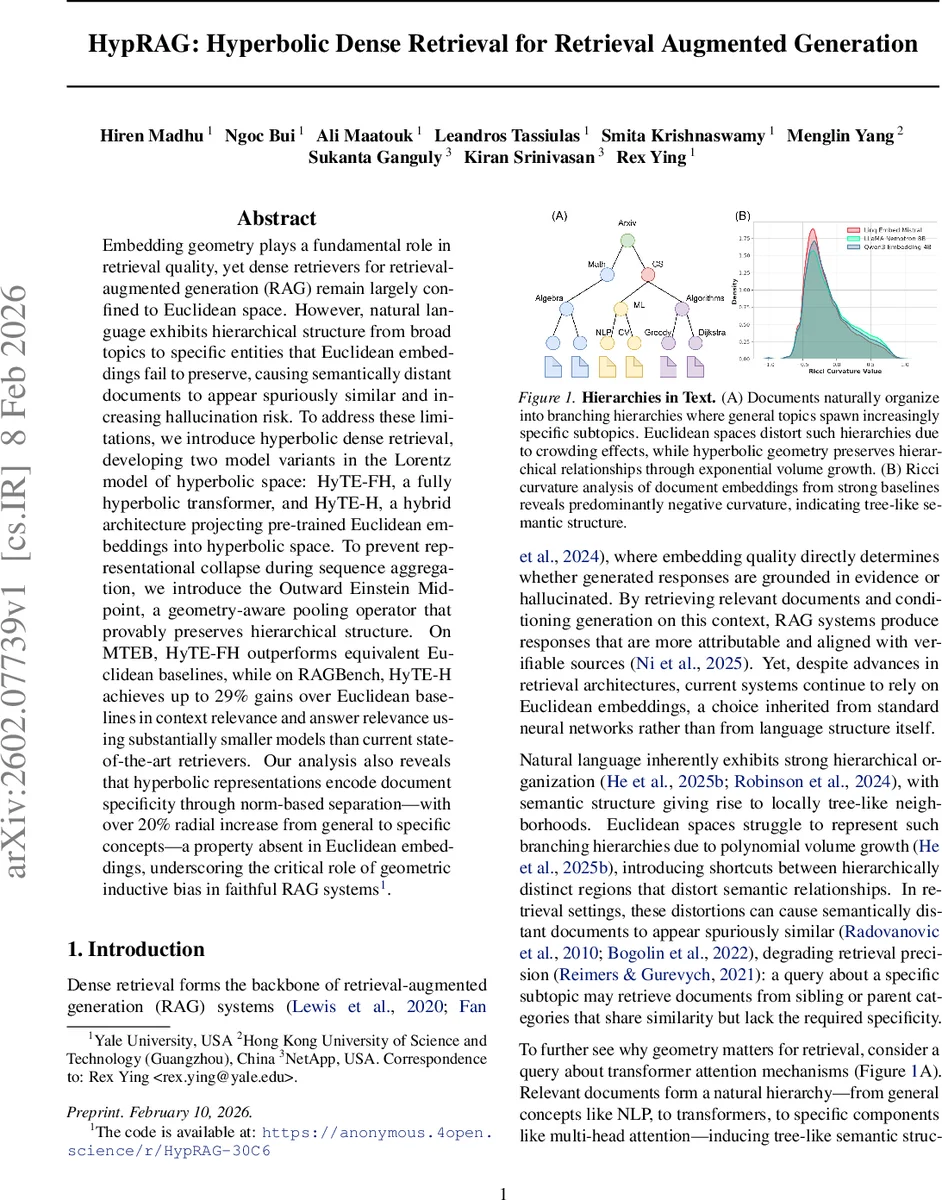
논문은 자연어가 토픽‑서브토픽‑엔터티와 같은 트리 구조를 내포한다는 점에 착안해, 거리와 부피가 지수적으로 증가하는 하이퍼볼릭 공간이 이러한 계층을 보다 자연스럽게 표현한다는 가설을 세운다. 이를 검증하기 위해 저자들은 MS MARCO 문서 임베딩에 Ollivier–Ricci curvature 분석을 적용했으며, 대부분의 모델에서 음의 곡률이 관측돼 트리‑유사 구조가 존재함을 확인한다. 하이퍼볼릭 임베딩을 구현하기 위해 로렌츠 모델을 선택했는데, 이는 닫힌 형태의 거리·로그·지수 사상과 라플라시안 연산을 제공해 최적화가 용이하다. 두 아키텍처는 각각 완전 하이퍼볼릭 변환기(HyTE‑FH)와 사전학습된 Euclidean 인코더를 하이퍼볼릭으로 투사하는 하이브리드(HyTE‑H)로 구분된다. HyTE‑FH는 모든 레이어(선형, 레이어 정규화, 잔차 연결, 셀프‑어텐션)를 로렌츠 공간에 맞게 재정의했으며, 특히 어텐션 가중치를 지오데식 거리 기반의 가우시안 형태로 계산해 유클리드 코사인 유사도 대신 하이퍼볼릭 근접성을 활용한다. 반면 HyTE‑H는 기존 대형 언어 모델의 임베딩을 그대로 사용해 학습 비용을 크게 절감한다. 핵심 기술적 기여는 ‘Outward Einstein Midpoint’ 풀링이다. 기존의 유클리드 평균 후 재투사 방식은 하이퍼볼릭 볼록성 때문에 평균점이 원점에 가까워져 반경(depth) 정보를 소실한다. 논문은 이를 정리·증명(Proposition 4.3)하고, 토큰 벡터를 원점에서 멀리 떨어진 정도에 비례해 가중치를 부여하는 Einstein 중점 연산을 제안한다. 이 연산은 토큰의 의미적 구체성을 반경으로 보존하면서도 문서 수준 임베딩을 안정적으로 생성한다. 실험에서는 MTEB 벤치마크에서 HyTE‑FH가 동일 차원의 Euclidean 베이스라인보다 전반적인 검색 정확도(NDCG, Recall)에서 우위를 차지했으며, RAGBench에서는 HyTE‑H가 문맥 관련성·답변 정확도에서 최대 29% 향상을 보였다. 특히 HyTE‑H는 파라미터 수가 2‑3배 적음에도 불구하고 성능이 뛰어나, 리소스 제한 환경에서의 적용 가능성을 시사한다. 마지막으로, 하이퍼볼릭 임베딩이 일반‑특정 개념을 반경 차이(≈20% 증가)로 구분한다는 정량적 분석을 통해, 기하학적 편향이 실제 의미 계층을 캡처한다는 증거를 제공한다. 전체적으로 이 연구는 임베딩 공간 선택이 RAG 시스템의 사실성·신뢰성에 미치는 영향을 체계적으로 조명하고, 하이퍼볼릭 공간이 그 해결책이 될 수 있음을 실험과 이론으로 뒷받침한다.
댓글 및 학술 토론
Loading comments...
의견 남기기