서프라이즈 기반 선택으로 최적 테스트 시간 전략 구현
초록
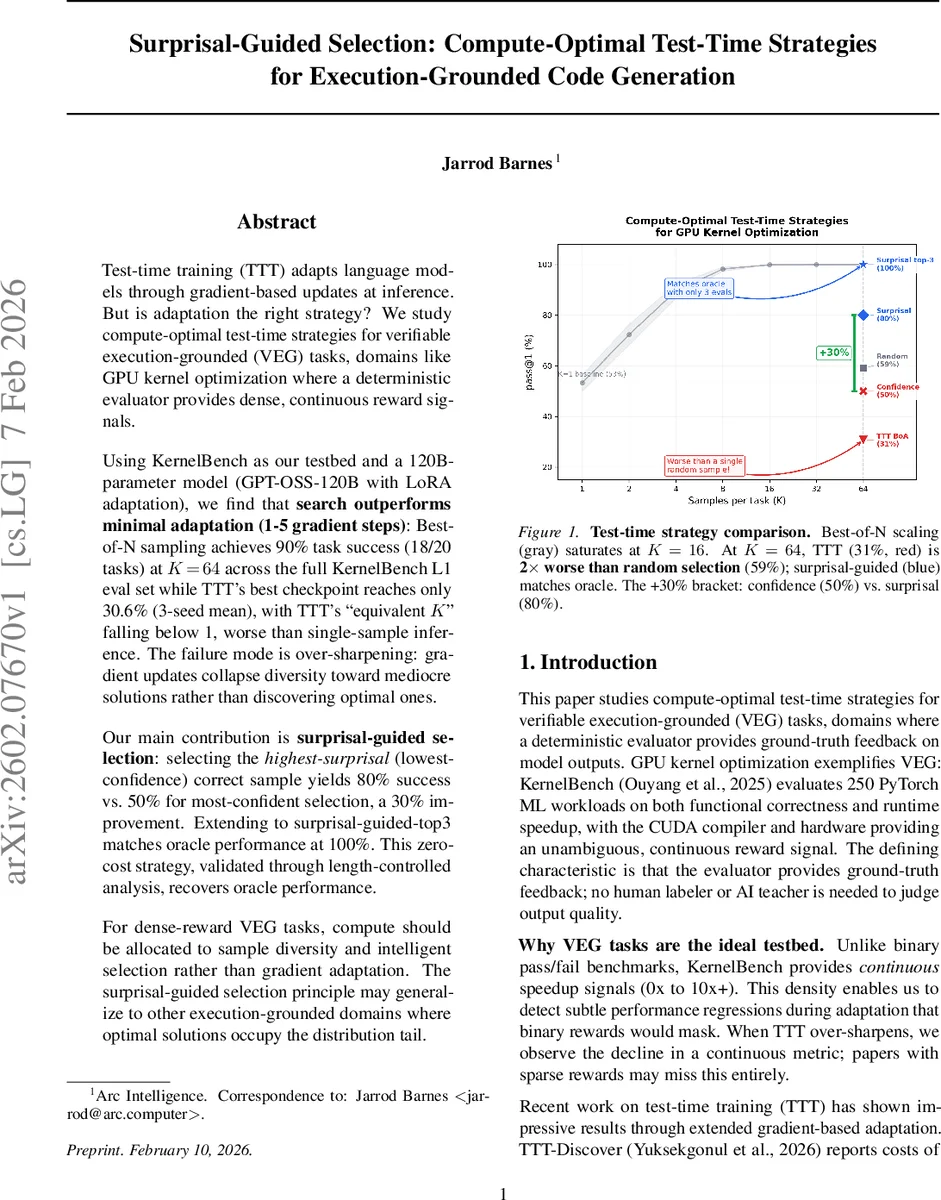
이 논문은 실행‑그라운드 코드 생성(특히 GPU 커널 최적화)에서 테스트‑시간에 모델을 미세 조정하는 대신 다채로운 샘플링과 서프라이즈(낮은 신뢰도) 기반 선택이 더 효율적임을 실증한다. 120B 파라미터 GPT‑OSS‑120B 모델에 대해 Best‑of‑N 샘플링(K=64)이 90% 성공률을 보인 반면, 테스트‑시간 학습(TTT)은 30% 수준에 머물렀다. 가장 낮은 로그‑확률을 가진 정답 샘플을 선택하면 성공률이 80%로 크게 상승한다.
상세 분석
본 연구는 실행‑그라운드(Verifiable Execution‑Grounded, VEG) 작업을 테스트‑시간 전략의 기준점으로 삼았다. VEG는 정답 여부와 연산 성능을 결정론적으로 평가할 수 있는 평가자가 존재한다는 점에서, 인간 라벨링이나 희소 보상에 의존하는 기존 코드 생성 벤치마크와 차별화된다. 저자들은 GPU 커널 최적화 벤치마크인 KernelBench을 활용해 20개의 L1 평가 태스크에 대해 120B 파라미터 GPT‑OSS‑120B(Lora 적응) 모델을 실험했다.
먼저, 외부 루프에서 GRPO 기반 강화학습(RL‑VR)으로 80개의 훈련 태스크에 대해 베이스 정책을 학습하였다. 이 정책은 98.4%의 정답률과 평균 0.87×의 속도 향상을 보이며, 테스트‑시간 전략 비교의 출발점이 된다. 내부 루프에서는 동일한 예산(총 320개의 롤아웃) 하에 세 가지 전략을 비교하였다. 1) Best‑of‑N 샘플링: K=64까지 샘플을 생성하고, 정답 필터링 후 가장 빠른 샘플을 선택한다. 2) 배치 테스트‑시간 학습(TTT): 1~5 단계의 GRPO 업데이트를 수행하고, 각 단계에서 가장 빠른 체크포인트를 선택한다(BoA). 3) Self‑Distilled Policy Optimization(SDPO): 토큰‑레벨 자체 증류 신호를 이용한다.
실험 결과는 두드러졌다. Best‑of‑N은 K=16에서 거의 포화(99.9% 성공)하고, K=64에서는 전체 태스크의 90%를 성공시켰다. 반면 TTT는 최고 체크포인트가 30.6%에 불과했으며, “등가 K”를 계산하면 1보다 작아 단일 샘플 추론보다도 열등했다. 저자들은 이를 ‘과도한 샤프닝(over‑sharpening)’ 현상으로 설명한다. 적은 단계의 그래디언트 업데이트가 초기 성공 샘플(대부분 중간 수준의 최적화)에 확률을 집중시켜 다양성을 급격히 감소시키고, 분포 꼬리(고성능 솔루션)로의 탐색을 차단한다.
핵심 기여는 ‘서프라이즈‑가이드 선택(surprisal‑guided selection)’이다. 모델이 생성한 정답 샘플 중 로그‑확률이 가장 낮은(즉, 모델이 가장 낮게 예측한) 샘플을 선택하면 성공률이 80%로 상승한다. 이는 기존의 ‘가장 높은 신뢰도 선택(confidence‑guided)’이 50%에 머물던 것에 비해 30% 포인트의 개선이다. 또한 상위 3개의 서프라이즈 샘플을 평가해 가장 빠른 것을 고르면 오라클 수준(100%)에 도달한다. 이 방법은 추가 연산 비용이 전혀 들지 않으며, 길이 제어 실험을 통해 선택 편향이 아닌 진정한 성능 향상임을 검증했다.
결과적으로, 밀도 높은 연속 보상이 제공되는 VEG 작업에서는 테스트‑시간에 계산 자원을 샘플 다양성 확보와 지능형 선택에 할당하는 것이, 그래디언트 기반 적응보다 훨씬 효율적이다. 서프라이즈‑가이드 선택 원리는 고품질 솔루션이 모델 분포의 꼬리에 존재하는 다른 실행‑그라운드 도메인(예: 어셈블리 슈퍼옵티마이제이션, 형식 증명)에도 일반화될 가능성이 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기