메모리 추출 공격 방어를 위한 최적화 허니팟
초록
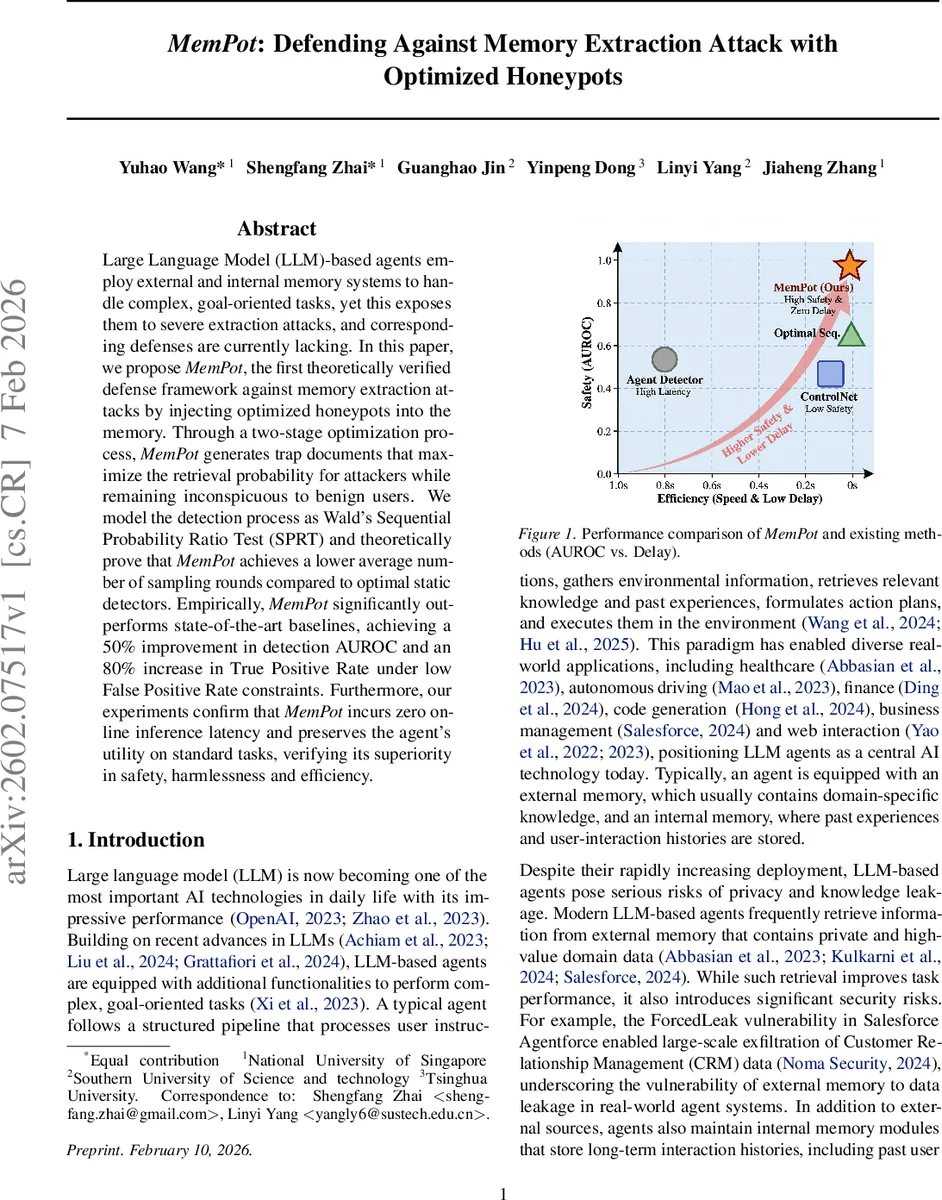
LLM 기반 에이전트의 외부·내부 메모리를 보호하기 위해, MemPot은 메모리에 함정 문서를 삽입하고 순차적 가설 검정(SPRT)을 활용해 공격자를 빠르게 탐지한다. 두 단계 최적화(대조 손실 기반 임베딩 설계와 안전한 텍스트 복원)를 통해 정상 사용자는 영향을 받지 않으며, 실험에서 AUROC 50%·TPR 80% 향상과 온라인 지연 0을 달성했다.
상세 분석
본 논문은 대규모 언어 모델(LLM) 에이전트가 외부·내부 메모리를 활용하면서 겪는 프라이버시 침해 위험을 근본적으로 해결하고자 한다. 기존 방어 기법은 실시간 쿼리당 탐지를 수행하지만, 공격자가 정상 사용자와 유사한 질의를 반복적으로 보내는 경우 탐지가 어려워진다. MemPot은 이러한 한계를 넘어, 메모리 자체에 ‘허니팟’ 문서를 삽입해 공격자를 유인하고, 연속적인 검색 결과를 누적해 순차 가설 검정(SPRT)으로 탐지한다는 새로운 패러다임을 제시한다.
핵심 기술은 두 단계 최적화에 있다. 1단계에서는 임베딩 공간에서 허니팟 벡터를 학습한다. 저자는 대조 손실(InfoNCE)을 이용해 공격자와 정상 사용자의 검색 패턴을 최대한 구분하도록 설계했으며, KL 발산을 통한 정보 드리프트(µ₁, µ₀)를 증대시켜 SPRT의 평균 샘플링 수(ASN)를 최소화한다. 또한, 다양성 손실을 추가해 허니팟 간 중복을 방지하고, 상위‑k 검색 결과에만 초점을 맞춤으로써 실제 시스템과의 정합성을 높였다.
2단계에서는 최적화된 임베딩을 실제 텍스트 문서로 변환한다. 안전 제약을 고려한 임베딩 역전사(embedding inversion) 과정을 통해, 생성된 문서는 인간 사용자에게 무해하고 의미적으로 일관되면서도, 공격자가 검색할 확률을 높이는 특성을 유지한다.
이론적 분석에서는 Wald의 SPRT를 기반으로, 허니팟을 삽입한 경우 정적(고정‑길이) 탐지기보다 기대 탐지 라운드가 항상 작아짐을 정리(정리 2)하고, 대조 손실 최소화가 정보 드리프트를 상향시켜 ASN을 감소시킴을 증명한다(정리 1). 따라서 MemPot은 동일한 오류 한계(α, β) 하에서 가장 빠르게 결정을 내릴 수 있는 최적 탐지기임을 보인다.
실험에서는 두 개의 데이터셋(외부 메모리 기반 RAG와 내부 대화 기록)과 두 종류의 에이전트 설정에서 최신 방어 기법(ControlNet, 텍스트‑레벨 LLM 탐지 등)을 비교했다. MemPot은 AUROC에서 평균 50% 상승, FPR 1% 이하에서 TPR이 80% 증가하는 등 현저한 성능 향상을 보였으며, 온라인 추론 지연이 거의 0에 가깝고, 정상 사용자에 대한 유틸리티(응답 정확도·사용자 만족도)에도 영향을 미치지 않았다.
이 논문은 메모리 보안 분야에 ‘공격 유인형’(honeypot) 개념을 도입하고, 순차 통계 검정을 통해 실시간 비용 없이 고효율 탐지를 구현한 점에서 혁신적이다. 다만 허니팟 문서의 내용이 도메인에 따라 민감할 수 있다는 점, 공격자가 허니팟을 인식하고 회피 전략을 학습할 가능성, 그리고 임베딩 역전사 과정에서 발생할 수 있는 텍스트 품질 저하 등에 대한 추가 연구가 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기