Few Shot 비전 언어 행동 적응을 위한 가치 가이드 액션 청크 선택
초록
VGAS는 제한된 시연 데이터만으로 비전‑언어‑행동(VLA) 모델을 적응시키기 위해, 고리콜 제안 생성기와 기하학적으로 정밀한 선택기를 결합한다. 제안 단계에서는 미세 조정된 VLA가 다수의 액션 청크를 생성하고, 선택 단계에서는 Q‑Chunk‑Former라는 Transformer 기반 비평가가 명시적 기하학 정규화(EGR)를 통해 가치 함수를 학습한다. 이를 통해 Near‑miss 후보들 사이의 미세한 기하학 차이를 구분하고, 베스트‑오브‑N 선택으로 성공률과 로버스트성을 크게 향상시킨다.
상세 분석
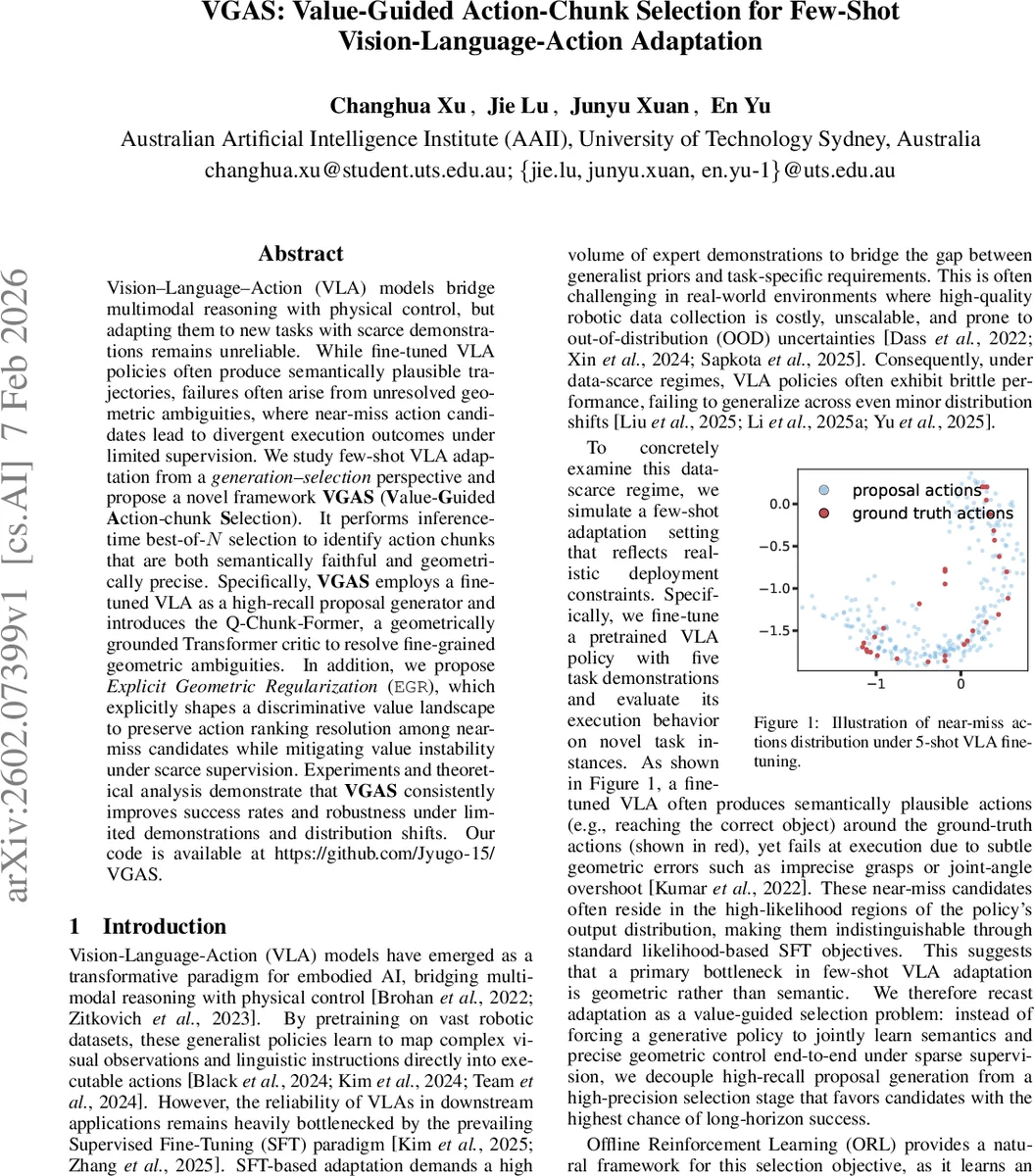
VGAS는 기존의 SFT(지도학습 미세조정) 방식이 시연이 부족한 상황에서 의미는 맞지만 기하학적 정밀도가 떨어지는 문제를 근본적으로 재구성한다. 핵심 아이디어는 “생성‑선택” 패러다임으로, 먼저 고리콜(높은 재현율) 제안기를 통해 다양한 액션 청크를 샘플링하고, 이후 가치 기반 선택기를 통해 최적 청크를 골라낸다. 이를 위해 두 가지 기술적 난제를 해결한다. 첫째, VLA가 출력하는 temporally‑extended action chunk를 평가할 수 있는 critic 구조가 필요하다. 기존 RL은 원자적 액션을 전제로 하여 SMDP(옵션 MDP) 상황에선 가치 추정이 불안정하다. VGAS는 Q‑Chunk‑Former라는 Transformer 기반 critic을 설계했는데, 여기서는 State‑Action Fusion(SAF) 모듈을 도입해 로봇의 proprioception(p_t)과 액션 청크(A_t)를 먼저 결합한다. 이 과정은 기하학적 제약을 토큰 수준에서 명시적으로 반영하도록 설계돼, 시각·언어 토큰에 압도당하지 않게 한다. 두번째 난제는 적은 시연 데이터에서도 near‑miss 후보들의 순위 구분력을 유지하는 가치 함수 학습이다. 이를 위해 VGAS는 Proposal‑Constrained Chunked Expected‑Max(EMaQ) 백업 연산과 Explicit Geometric Regularization(EGR)을 결합한다. EGR은 전문가 시연과의 기하학적 거리(예: 그립 포인트, 관절 각도)를 dense하게 활용해 가치 지형을 “깊은 퍼널” 형태로 shaping한다. 결과적으로 가치 함수는 작은 차이에도 큰 그래디언트를 제공해, 베스트‑오브‑N 선택 시 near‑miss와 실패 후보를 명확히 구분한다. 이론적으로는 chunk‑level Bellman 연산이 수렴함을 증명하고, 실험에서는 LIBERO 벤치마크와 다양한 OOD 시나리오에서 SFT 및 기존 오프라인 RL 대비 성공률 10~15%p 상승, 특히 5‑shot 이하 상황에서 강건성을 크게 개선한다. 또한, 베스트‑오브‑N의 N을 늘려도 가치 함수의 안정성이 유지되어, 실시간 로봇 시스템에서 샘플링 비용과 성능 사이의 트레이드오프를 유연하게 조절할 수 있다. 전체적으로 VGAS는 “가치‑가이드 선택”이라는 새로운 프레임워크를 제시함으로써, 제한된 시연 데이터와 복잡한 멀티모달 관측을 가진 로봇 제어 문제에 대한 실용적인 해결책을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기