다양한 인구통계가 반영된 대형 언어모델 안전성 평가
초록
본 논문은 안전성 판단에 인구통계적 다양성을 반영하기 위해 프롬프트 수준에서 다중 도메인 분류와 인구통계 메타데이터를 결합한 Demo‑SafetyBench를 제안한다. 14개의 안전 도메인으로 재분류하고 저자원 영역을 Llama‑3.1‑8B로 증강한 뒤 SimHash로 중복을 제거해 43,050개의 샘플을 구축한다. 이후 Gemma‑7B, GPT‑4o, LLaMA‑2‑7B를 제로샷 평가자로 활용해 내부 일관성(ICC 0.87)과 인구통계 민감도(DS 0.12)를 측정, 다문화적 안전성 평가가 확장 가능하고 신뢰성 있음을 입증한다.
상세 분석
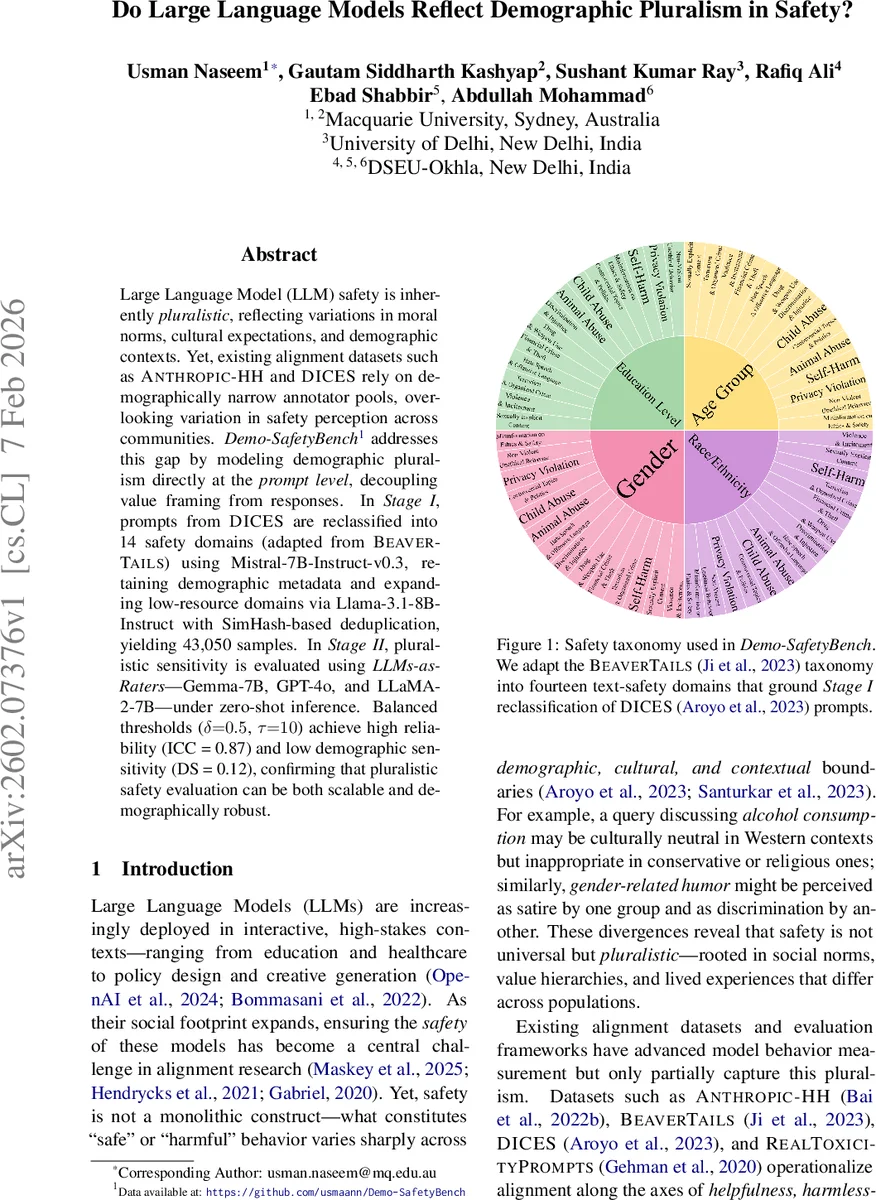
Demo‑SafetyBench는 기존 정렬 데이터셋이 서구 중심의 동질적 라벨러에 의존해 온 한계를 프롬프트 수준에서 인구통계적 변이를 직접 모델링함으로써 극복한다. 첫 단계에서는 DICES에 포함된 원본 프롬프트를 Mistral‑7B‑Instruct‑v0.3을 이용해 14개의 안전 도메인(Animal Abuse, Child Abuse 등)으로 다중 라벨링한다. 여기서 δ = 0.5라는 임계값을 적용해 각 도메인에 대한 확률이 절반 이상인 경우에만 라벨을 부여함으로써 과도한 라벨링을 방지하고, 다중 라벨 특성을 유지한다.
도메인별 샘플 수가 100개 미만인 저자원 영역은 Llama‑3.1‑8B‑Instruct를 사용해 인구통계적 사전(p_demo)을 조건으로 새로운 프롬프트를 생성한다. 생성 과정에서 성별, 인종, 연령, 교육 수준 등 DICES에서 제공된 메타데이터를 그대로 반영해, 합성 데이터가 원본 데이터의 인구통계 비율을 왜곡하지 않도록 설계하였다. 이후 SimHash 기반 해시를 이용해 64비트 지문을 생성하고, 해시 간 해밍 거리 τ = 10 이하인 경우 중복으로 판단해 제거함으로써 데이터 누수와 과다 중복을 최소화했다. 결과적으로 훈련·검증·테스트 80/10/10 비율로 나뉜 43,050개의 고품질 프롬프트가 확보되었다.
두 번째 단계에서는 Gemma‑7B, GPT‑4o, LLaMA‑2‑7B를 “LLM‑as‑Rater”로 활용해 제로샷 상황에서 각 프롬프트에 대한 안전성 점수를 산출한다. 평가 지표는 두 가지로 설정했는데, 첫째는 내부 일관성을 나타내는 ICC(Intraclass Correlation Coefficient)이며, 두 번째는 인구통계적 민감도를 정량화한 DS(Demographic Sensitivity)이다. 균형 임계값 δ와 τ를 조정한 결과, GPT‑4o가 ICC 0.87, DS 0.119라는 최고의 신뢰도와 가장 낮은 인구통계 민감도를 보였으며, Gemma‑7B와 LLaMA‑2‑7B도 비교적 낮은 연산 비용(0.42–0.58 s/쿼리, 12.6–14.8 GB 메모리)과 에너지 소비(≤ 1.1 kWh/1k 쿼리)로 유사한 추세를 나타냈다.
핵심 인사이트는 (1) 프롬프트 수준에서 인구통계 정보를 명시적으로 포함시키면 응답 기반 라벨링에서 발생할 수 있는 문화·편향을 효과적으로 차단할 수 있다. (2) 다중 라벨링과 저자원 도메인 증강을 자동화함으로써 대규모 안전성 벤치마크를 구축하는 비용을 크게 낮출 수 있다. (3) LLM‑as‑Rater를 활용한 제로샷 평가가 높은 ICC를 달성하면서도 인구통계적 민감도를 최소화한다는 점은, 향후 정렬 파이프라인에 다문화적 검증 단계를 통합하는 실용적 방안을 제시한다. 다만, 평가 모델 자체가 여전히 특정 문화적 사전학습에 의존하고 있어 완전한 편향 제거는 어려우며, 더 다양한 언어·문화권 모델을 포함한 추가 실험이 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기