문서 파싱을 위한 구조 인식 관계 삼중 패러다임
초록
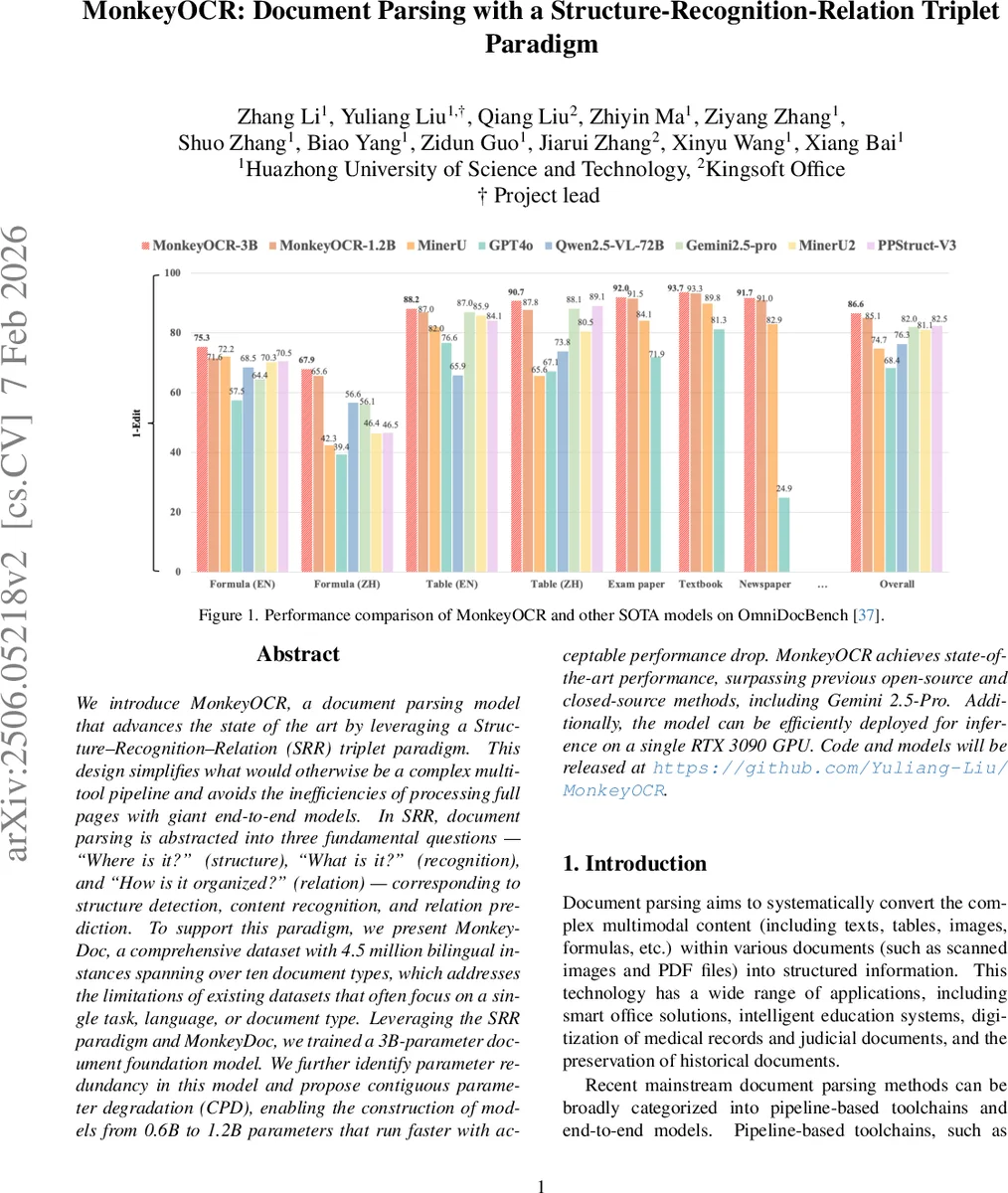
MonkeyOCR는 문서 파싱을 “구조‑인식‑관계”라는 세 단계 질문으로 분해하는 SRR 패러다임을 제안한다. 4.5 백만 개의 중·영문 이중 언어 데이터셋 MonkeyDoc을 기반으로 3 B 파라미터 문서 기반 모델을 학습하고, 연속 파라미터 감소(CPD) 기법으로 0.6 B‑1.2 B 규모의 경량 모델을 만든다. 구조 검출, 블록 단위 인식, 블록 레벨 읽기 순서 예측을 각각 하나의 모델로 처리해 파이프라인 오류를 최소화하고, 전체 페이지를 한 번에 처리하는 거대 모델보다 효율성을 크게 높였다. 실험 결과 Gemini 2.5‑Pro와 Qwen2.5‑VL‑72B 등 최신 상용·오픈소스 모델을 모두 능가했으며, RTX 3090 한 대에서 실시간 추론이 가능하다.
상세 분석
MonkeyOCR 논문은 기존 문서 파싱 방법론의 두 가지 큰 한계를 정확히 짚어낸다. 첫 번째는 파이프라인 기반 도구 체인에서 발생하는 누적 오류이다. 레이아웃 검출 → 텍스트·수식 검출 → 인식 → 블록 병합 → 읽기 순서 재구성 순으로 진행될 때, 앞 단계의 작은 오차가 뒤 단계에 증폭돼 최종 구조화 정확도가 급격히 떨어진다. 두 번째는 전체 페이지를 입력으로 하는 거대 엔드‑투‑엔드 모델이 고해상도 문서와 긴 시퀀스를 처리할 때 계산량이 제곱적으로 증가하고, 장문 컨텍스트에서 환각 현상이 빈번히 발생한다는 점이다.
이를 해결하기 위해 저자들은 “구조‑인식‑관계”(Structure‑Recognition‑Relation, SRR)라는 삼중 질문 프레임워크를 제안한다.
1️⃣ Structure 단계에서는 DETR 기반 객체 검출 모델을 활용해 텍스트 블록, 표, 수식, 이미지 등 문서 내 주요 영역을 좌표와 카테고리로 추출한다. 여기서 전경 확률을 이용한 쿼리 선택 모듈이 배경 노이즈를 효과적으로 억제한다.
2️⃣ Recognition 단계는 각 검출된 블록을 원본 해상도로 잘라낸 뒤, 비전 인코더와 MLP를 통해 시각 토큰으로 변환하고, 블록 유형에 맞는 프롬프트와 결합해 대형 언어 모델(LLM)에게 전달한다. 하나의 LLM이 텍스트, 표, 수식 모두를 동시에 처리하도록 설계돼, 별도 OCR·표 인식·수식 인식 모델을 별도로 유지할 필요가 없어진다.
3️⃣ Relation 단계는 블록 레벨의 읽기 순서를 예측한다. 좌표와 크기를 임베딩하고, 트랜스포머 블록을 통과시켜 블록 간 선후 관계를 분류한다. 이렇게 얻은 순서는 인식 결과를 올바르게 결합해 최종 구조화 문서를 만든다.
핵심 데이터셋인 MonkeyDoc은 4.5 백만 개의 이중 언어(중‑영) 인스턴스를 포함하고, 레이아웃, 읽기 순서, 텍스트, 표, 수식 등 다섯 가지 파싱 작업을 모두 포괄한다. 기존 공개 데이터셋이 특정 작업·언어·문서 유형에 국한된 반면, MonkeyDoc은 10여 종류의 문서(재무 보고서, 교과서, 학술 논문 등)를 아우르며, 자동 라벨링 파이프라인과 LLM 기반 생성·번역을 결합해 데이터 다양성과 품질을 동시에 확보한다.
모델 규모와 효율성 측면에서 저자들은 연속 파라미터 감소(Contiguous Parameter Degradation, CPD) 를 도입했다. 3 B 파라미터 모델에서 중간 레이어를 연속적으로 건너뛰어 0.6 B‑1.2 B 규모의 경량 모델을 만들었으며, 단순히 층을 제거하는 것이 아니라 각 블록의 입력‑출력 차원을 유지하도록 설계해 성능 저하를 최소화했다. 실험 결과, 텍스트 인식 같은 단순 작업에서는 거의 차이가 없었고, 표 인식처럼 복잡한 작업에서는 약 1‑2 % 정도의 성능 감소가 있었지만, 추론 속도는 34 % 이상 빨라졌다.
성능 평가에서는 OmniDocBench과 자체 구축한 테스트셋을 사용해 기존 파이프라인 모델(PPStruct‑V3)보다 4.1 %·전반적인 F1 점수에서 우수했으며, 거대 멀티모달 모델(Qwen2.5‑VL‑72B)과 상용 클로즈드소스 모델(Gemini 2.5‑Pro)보다도 높은 정확도와 2배 이상 빠른 추론 속도를 기록했다. 특히 RTX 3090 한 대에서 3 B 모델이 실시간 수준(초당 수 페이지)으로 동작한다는 점은 실제 서비스 적용 가능성을 크게 높인다.
전반적으로 이 논문은 문서 파싱을 “어디에?”, “무엇을?”, “어떻게 조직되어 있는가?”라는 세 질문으로 명확히 구분함으로써, 복잡한 파이프라인을 단순화하고, 대형 멀티모달 모델의 비효율성을 극복한다는 전략적 전환점을 제시한다. 데이터, 모델 설계, 효율화 기법이 유기적으로 결합돼 학계·산업 모두에 실용적인 로드맵을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기