스케일러블 비트폭 탐색을 통한 하드웨어 친화적 초저비트 LLM 혼합 정밀도 양자화
초록
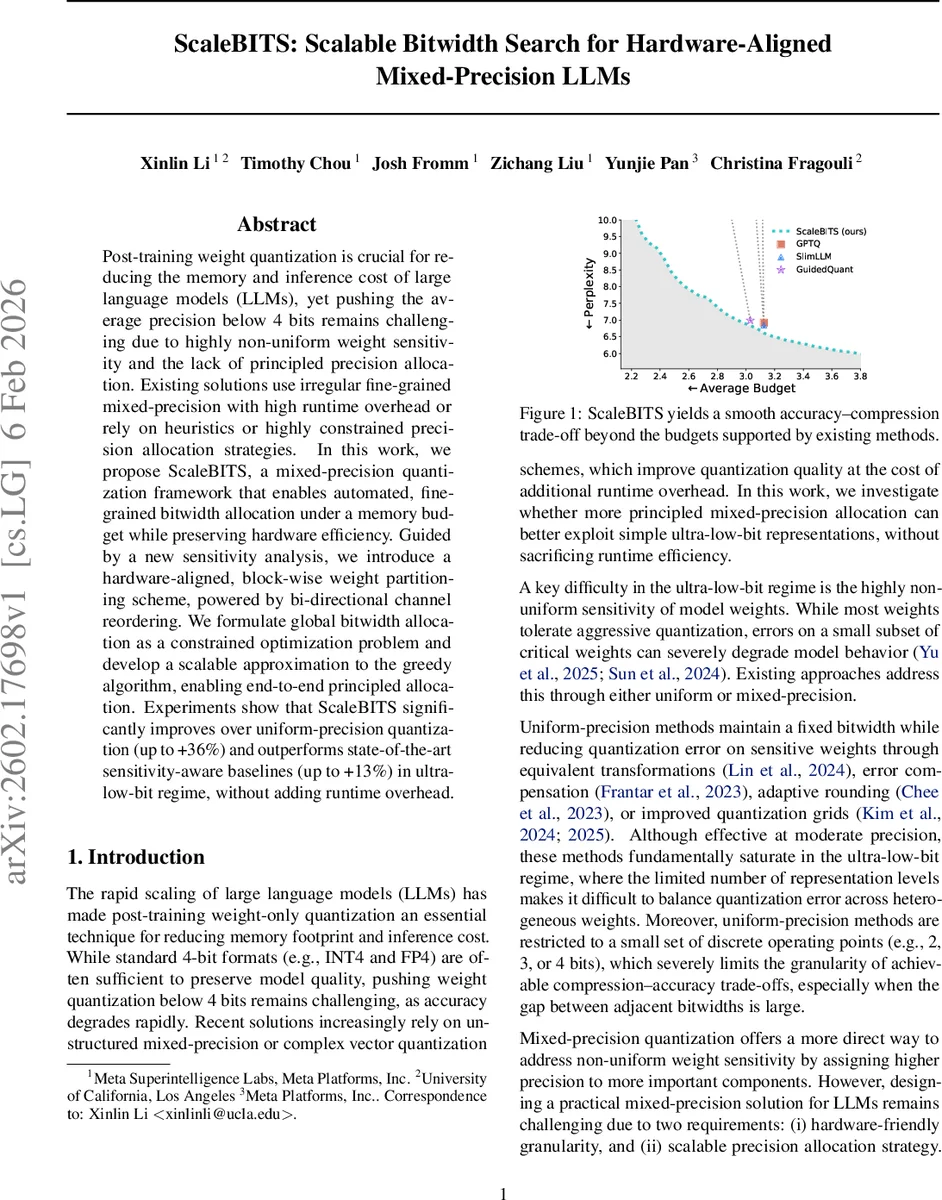
ScaleBITS는 LLM 가중치를 초저비트(4비트 이하)로 양자화하면서, 가중치 민감도에 기반한 블록 단위 비트폭 할당을 자동화한다. 양방향 채널 재배열로 민감 가중치를 연속적인 블록에 집중시키고, 메모리 예산을 만족하는 전역 최적화를 근사 그리디 알고리즘으로 해결한다. 실험 결과, 동일 메모리 한도에서 기존 균일·혼합 정밀도 방법보다 13%~36% 높은 정확도를 달성하고, 런타임 오버헤드 없이 하드웨어 효율성을 유지한다.
상세 분석
본 논문은 초저비트(≤4비트) 영역에서 LLM 가중치 양자화가 직면한 두 가지 핵심 난제, 즉 “가중치 민감도의 고비대”와 “실용적인 정밀도 할당 방법 부재”를 해결하고자 한다. 기존 연구는 레이어 단위의 거친 정밀도 할당이나, 비정형적인 요소별 혼합 정밀도로 정확도를 회복하려 했지만, 전자는 민감 가중치를 충분히 보호하지 못하고, 후자는 메타데이터와 제어 흐름 복잡도로 하드웨어 효율성을 크게 저하한다.
ScaleBITS는 먼저 진행형 양자화 기반 민감도 추정을 제안한다. 전통적인 1차·2차 테일러 전개는 전역 최적점에 가까운 풀프리시전 모델을 전제로 하지만, 초저비트 양자화 후 모델은 손실 곡면이 크게 변한다. 따라서 저자들은 현재 양자화된 모델 w_Q 주변에서 1차 미분(그라디언트)만을 이용해 민감도 s_i =|∇L(w_Q)_i·Δw_i| 를 계산한다. 실험적으로 이 추정치는 레이어·요소 수준에서 실제 손실 증가 순서를 정확히 재현하며, 풀프리시전 기반 추정보다 훨씬 신뢰성이 높다.
두 번째 핵심 기여는 양방향 채널 재배열을 통한 블록‑와이즈 가중치 파티셔닝이다. 감도 분석 결과, 높은 민감도 가중치는 특정 행(row)과 열(column) 채널에 집중되는 2차원 패턴을 보인다. 이를 이용해 행·열 채널을 동시에 정렬하면, 민감 가중치가 연속적인 작은 블록에 모이게 된다. 이렇게 정렬된 블록은 기존 GPU/TPU 매트릭스‑멀티플리케이션 커널에 그대로 매핑할 수 있어, 메타데이터 없이도 동일한 실행 흐름을 유지한다.
세 번째로, 전역 메모리 예산 B 하에서 비트폭 할당을 정수 최적화 문제로 정식화하고, 그리디 알고리즘의 근사 해를 제시한다. 전통적인 그리디는 O(N²) 평가 비용이 비현실적이지만, 저자들은 “마진 순위”만을 필요로 한다는 점에 착안해, 진행형 양자화 단계에서 얻은 민감도 s_i 를 이용해 마진을 빠르게 추정한다. 이를 통해 O(N log N) 복잡도로 거의 최적에 근접하는 비트폭 배분을 수행한다.
실험에서는 Gemma‑2‑9B, LLaMA‑2‑7B 등 여러 대형 모델에 대해 2‑3‑4‑비트 혼합 정밀도를 적용했으며, 동일 메모리 사용량 대비 기존 Uniform‑INT4, GPTQ, SlimLLM 등과 비교해 **정확도 향상 13%~36%**를 기록한다. 특히 초저비트(2‑3비트) 영역에서 민감 가중치를 적절히 보호함으로써, 기존 방법이 급격히 성능이 떨어지는 현상을 완화한다. 또한 블록‑와이즈 정밀도 할당은 기존 매트릭스 연산 파이프라인을 그대로 활용하므로, 런타임 오버헤드가 거의 없다.
요약하면, ScaleBITS는 (1) 양자화‑중심 민감도 추정, (2) 양방향 채널 재배열 기반 하드웨어‑친화적 블록 파티셔닝, (3) 효율적인 그리디 근사 비트폭 할당이라는 세 축을 결합해, 초저비트 LLM 양자화에서 정확도·메모리·속도 삼위일체를 동시에 만족시키는 실용적인 프레임워크를 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기