어텐션 엔트로피 기반 적응형 정책 최적화 AEGPO
안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
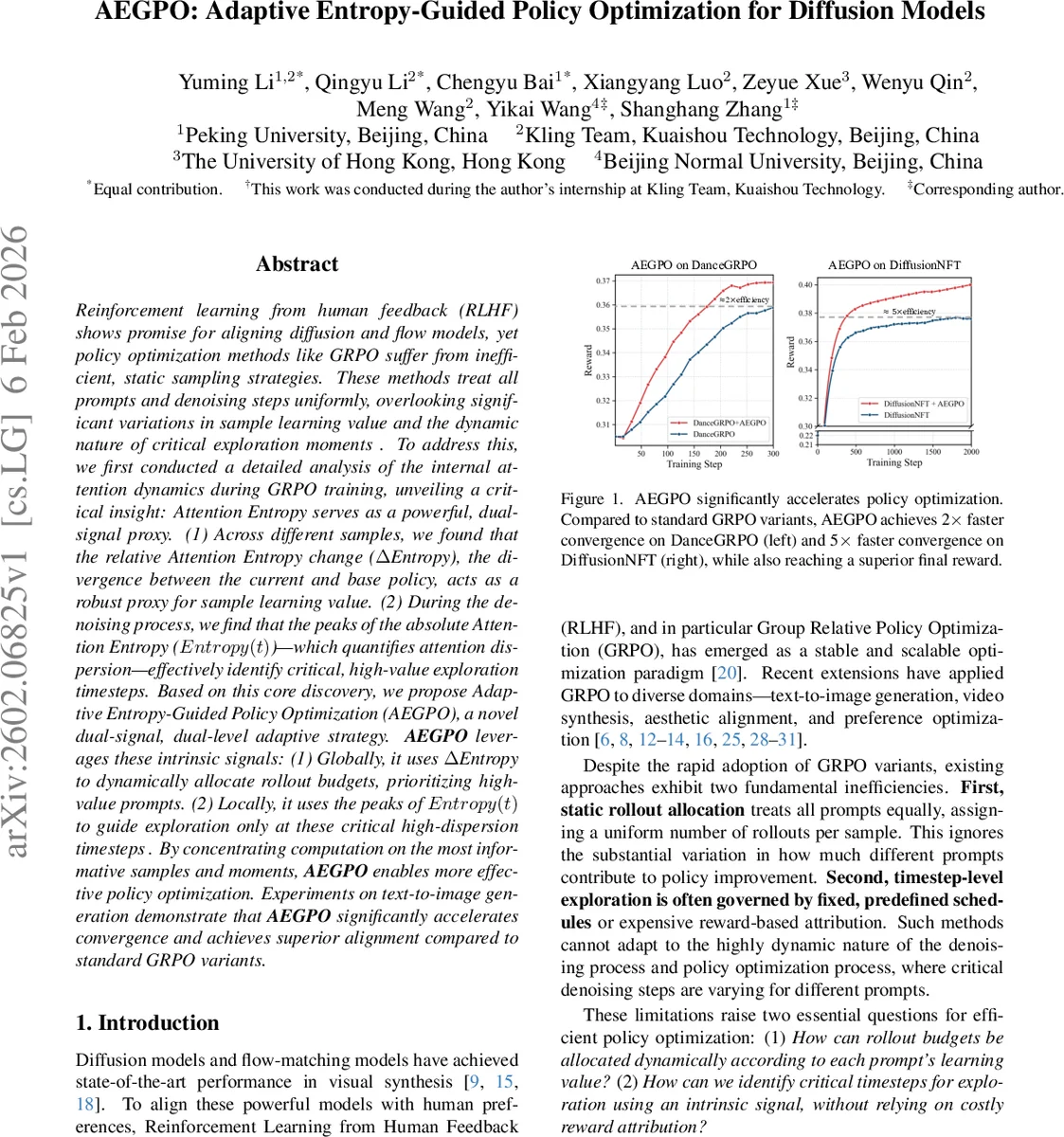
AEGPO는 확산 모델의 RLHF 학습에서 기존 GRPO가 보이는 균일한 샘플·시간 단계 할당의 비효율성을 극복한다. 모델 내부 어텐션 엔트로피 변화를 두 가지 신호(샘플 수준 ΔEntropy, 타임스텝 수준 Entropy(t))로 활용해, 학습 가치가 높은 프롬프트에 롤아웃을 집중하고, 어텐션 분산이 크게 나타나는 순간에만 탐색을 수행한다. 실험 결과 텍스트‑투‑이미지 작업에서 수렴 속도가 2~5배 가속화되고 최종 보상이 향상된다.
상세 분석
AEGPO의 핵심 아이디어는 어텐션 엔트로피가 모델 내부 상태 변화를 정량화하는 자연스러운 지표라는 점에 있다. 논문은 먼저 GRPO 학습 중 생성된 어텐션 맵 A_t를 여러 레이어와 헤드에 걸쳐 평균화하고, 각 이미지 피처 q_i에 대해 텍스트 토큰에 대한 확률 분포 Prob_t
댓글 및 학술 토론
Loading comments...
의견 남기기