공동 경험 기반 베스트 응답으로 샘플 효율적인 PSRO 구현
초록
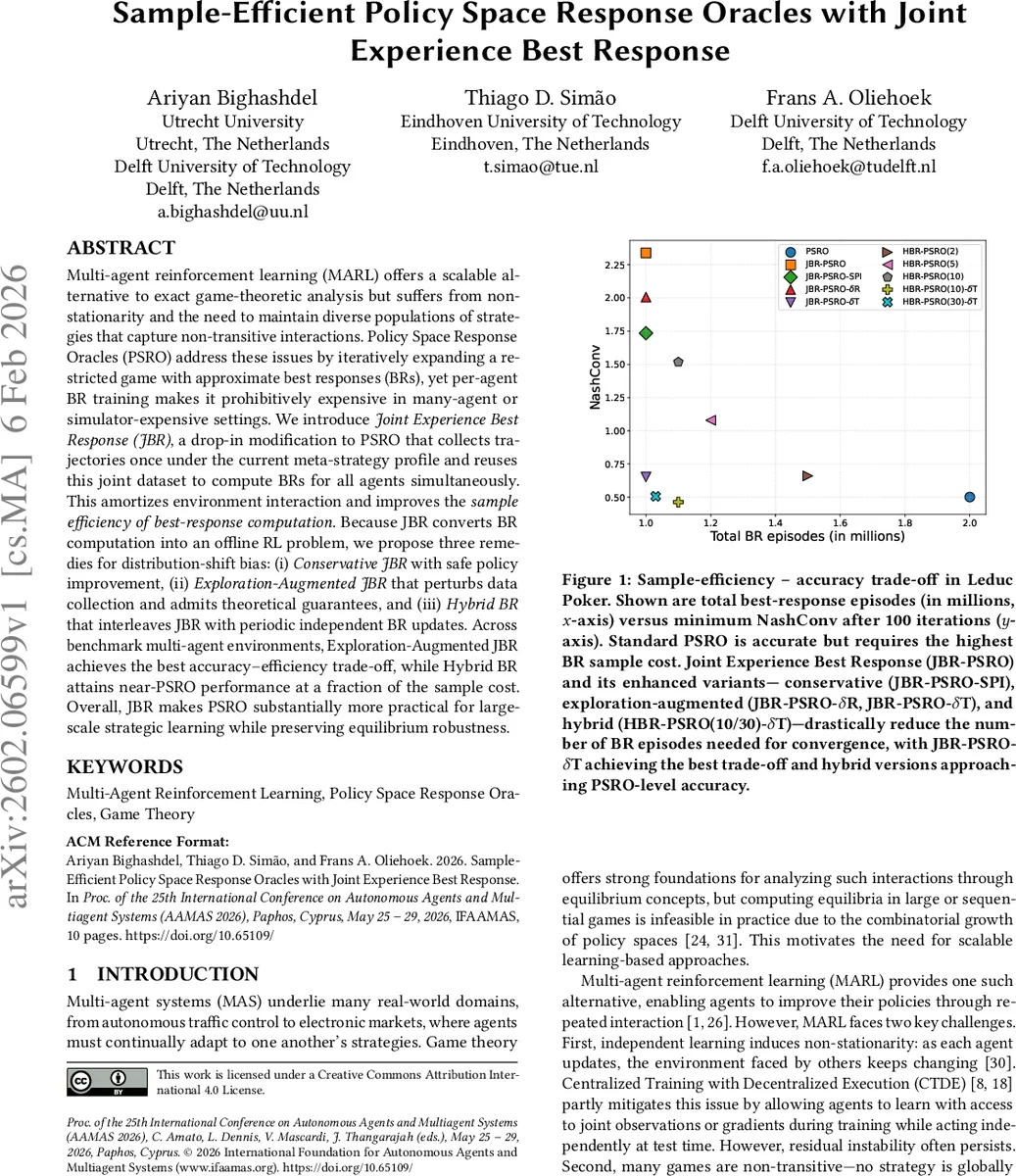
본 논문은 다중 에이전트 강화학습에서 PSRO의 샘플 비용을 크게 낮추는 Joint Experience Best Response(JBR) 방식을 제안한다. 현재 메타전략 프로필 아래 한 번의 시뮬레이션으로 수집한 공동 경험을 모든 에이전트의 베스트 응답 학습에 재활용함으로써 환경 상호작용을 절감한다. 오프라인 RL에서 발생하는 분포 이동 편향을 완화하기 위해 보수적 JBR, 탐색 강화 JBR, 그리고 독립 BR과 교차하는 Hybrid BR 세 가지 변형을 설계하고, 다양한 벤치마크에서 탐색 강화 JBR이 가장 높은 정확‑효율성을, Hybrid BR이 PSRO 수준의 성능을 적은 샘플로 달성함을 실험적으로 입증한다.
상세 분석
PSRO는 제한된 전략 집합을 점진적으로 확장하며 메타전략을 계산하고, 각 에이전트에 대해 독립적인 베스트 응답(Best Response, BR)을 강화학습으로 구한다. 이 과정에서 에이전트 수가 늘어나거나 시뮬레이터 비용이 높을 경우, 매 반복마다 n개의 별도 RL 학습이 필요해 샘플 효율성이 급격히 떨어진다. 저자들은 이러한 구조적 비효율성을 근본적으로 바꾸는 방법으로 Joint Experience Best Response(JBR)를 제안한다. JBR은 현재 메타전략 σ에 따라 모든 에이전트가 동시에 행동하도록 환경을 실행하고, 그 결과로 얻은 공동 데이터 Dσ를 저장한다. 이후 각 에이전트는 동일한 Dσ를 사용해 오프라인 RL(예: 가치 반복, 행동 클로닝, 오프라인 Q‑학습 등)으로 자신의 BR을 추정한다. 이렇게 하면 환경과의 상호작용 횟수는 한 번으로 줄어들어 전체 샘플 비용이 O(1)으로 감소한다.
하지만 오프라인 학습은 데이터가 현재 메타전략에 의해 생성된 제한된 분포에 국한되므로, 학습된 정책이 실제 최적 BR과 차이가 나는 분포 이동(Distribution Shift) 문제가 발생한다. 이를 해결하기 위해 세 가지 보완책을 제시한다. 첫째, 보수적 JBR(Conservative JBR)은 Safe Policy Improvement 원칙을 적용해 기존 메타전략보다 성능이 떨어지지 않도록 정책 업데이트를 제한한다. 둘째, 탐색 강화 JBR(Exploration‑Augmented JBR)은 데이터 수집 단계에서 ε‑greedy 혹은 정책 교란(δ‑perturbation)을 도입해 경험의 다양성을 인위적으로 확대하고, 이를 통해 오프라인 학습의 편향을 이론적으로 제한한다. 셋째, Hybrid BR은 일정 주기마다 독립적인 온라인 BR 학습을 삽입해 JBR이 놓친 미세한 전략 공간을 보완한다. 실험에서는 특히 δ‑perturbation을 적용한 탐색 강화 JBR이 최소 NashConv(전략 수렴 지표)을 달성하면서도 전체 BR 에피소드 수를 기존 PSRO 대비 70 % 이상 절감하는 것을 확인했다. Hybrid 변형은 주기적 온라인 업데이트를 통해 거의 PSRO와 동일한 수렴 정확도를 유지했으며, 추가 샘플 비용은 미미했다.
이러한 결과는 PSRO가 대규모 다중 에이전트 게임(예: 레덕 포커, 협동 로봇 협상)에서 실용적으로 적용될 수 있는 길을 열어준다. JBR은 기존 PSRO의 핵심 구조를 그대로 유지하면서도, 환경 상호작용을 공동화함으로써 샘플 효율성을 크게 향상시킨다. 또한 제안된 보수적·탐색·Hybrid 변형은 오프라인 RL의 일반적인 한계를 보완하는 실용적인 설계 패턴을 제공한다. 향후 연구에서는 JBR을 메타학습, 전이 학습, 혹은 비정형 관측 공간을 갖는 POMDP에 확장하는 방향이 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기