시퀀스‑레벨 역방향 업데이트를 통한 다턴 에이전트 RL 수렴 보장
안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
본 논문은 대형 언어 모델(LLM) 기반 에이전트 학습에 널리 쓰이는 기존 강화학습(RL) 알고리즘이 다턴 상호작용에서 수렴 보장을 제공하지 못한다는 문제를 지적한다. 저자는 정책 업데이트 방식과 어드밴티지 추정 방법의 조합을 체계적으로 분석하고, REINFORCE + GRAE는 무할인 설정에서만 전역 최적에 수렴함을, PPO + GRAE는 단일턴 밴딧에서는 동작하지만 다턴 환경에서는 단조성(monotonic improvement) 특성을 깨뜨린다는 것을 증명한다. 이를 해결하기 위해 제안된 SeeUPO는 각 턴을 가상의 에이전트로 보는 다턴 멀티‑에이전트 밴딧 모델링과, 실행 순서를 역으로(마지막 턴부터 첫 턴까지) 업데이트하는 역방향 순차 정책 최적화를 도입한다. 이 메커니즘은 Heterogeneous‑Agent Mirror Learning(HAML) 이론을 기반으로 단조적 정책 개선과 전역 최적 수렴을 보장한다. 실험 결과, AppWorld와 BFCL‑v4 벤치마크에서 Qwen3‑14B·Qwen2.5‑14B 모델에 대해 43‑55%·24‑42%의 상대적 성능 향상을 달성했으며, 학습 안정성도 크게 개선되었다.
상세 분석
-
문제 정의와 기존 연구의 한계
- LLM 기반 에이전트는 다턴 대화·툴 사용 등 복합적인 상호작용을 필요로 하며, 이를 강화학습으로 최적화할 때는 시퀀스‑레벨 정책이 필수적이다. 기존에는 토큰‑레벨 PPO(critic‑dependent)와 RLOO·GRPO·GSPO와 같은 critic‑free 변형이 주로 사용되었지만, 다턴 MDP에서의 수렴 이론이 부재했다. 특히, PPO의 핵심인 클리핑 기반 근접 정책 업데이트(PPU)가 다턴 상황에서 전체 반환에 대한 단조적 개선을 보장하지 못한다는 점이 핵심 문제로 지적된다.
-
어드밴티지 추정 방법 비교
- GAE: TD‑error 기반으로 가치 네트워크(V‑critic)를 필요로 하며, 편향‑분산 트레이드오프를 λ 파라미터로 조절한다. 하지만 대규모 LLM에서는 V‑critic 학습 비용이 높고, 부정확한 가치 추정이 정책 업데이트에 악영향을 미친다.
- GRAE: 동일 쿼리에 대해 N개의 샘플을 수집하고, 전체 평균 보상과의 차이로 어드밴티지를 정의한다. 이 방식은 critic‑free이지만, 그룹 평균을 이용한 정규화(분산 나누기)는 편향을 도입하고, PPO와 결합될 경우 단조성 증명을 깨뜨린다.
-
정책 업데이트 메커니즘 분석
- REINFORCE: 완전 온‑policy이며, 어드밴티지 추정값을 그대로 사용해 정책 그라디언트를 계산한다. 무할인(discount = 1) 설정에서 GRAE와 결합하면 기대값이 정확히 전체 보상의 차이와 일치해 전역 최적에 수렴한다는 증명이 제공된다. 그러나 다턴 MDP에서는 타임스텝 간 상관관계를 반영하지 못해 샘플 효율이 낮다.
- PPU (PPO): 중요도 샘플링 비율 r(θ)와 클리핑을 통해 여러 번 업데이트가 가능하지만, 다턴 상황에서 각 턴의 어드밴티지를 독립적으로 추정하면 전체 정책의 단조적 개선을 보장할 수 없으며, 특히 GRAE와 결합될 경우 “그룹‑분산 정규화”가 drift function을 왜곡한다.
-
SeeUPO의 핵심 아이디어
- 멀티‑에이전트 밴딧 모델링: 다턴 인터랙션을 T개의 순차적인 단일턴 밴딧 게임으로 분해한다. 각 턴 t는 “가상 에이전트”라 간주하고, 해당 턴의 행동은 현재 상태와 이전 턴들의 정책에 의해 결정된다.
- 역방향 순차 업데이트: 마지막 턴 T부터 첫 턴 1까지 역순으로 정책을 업데이트한다. 이는 동적 계획법의 backward induction과 동일한 논리로, 이미 최적화된 후속 턴들의 정책을 고정한 상태에서 현재 턴을 최적화하면 전체 반환에 대한 최적성을 보장한다.
- HAML 기반 수렴 증명: Heterogeneous‑Agent Mirror Learning은 각 에이전트(턴)의 drift function과 advantage decomposition이 만족하면 전체 조인트 정책이 단조적으로 개선되고 Nash equilibrium(여기서는 전역 최적)으로 수렴한다는 정리를 제공한다. SeeUPO는 이 프레임워크에 맞게 drift를 “turn‑level KL‑divergence” 형태로 정의하고, 클리핑 없이 순수한 mirror operator를 적용해 이론적 보장을 얻는다.
-
실험 설계 및 결과
- 벤치마크: AppWorld(툴 사용·웹 탐색)와 BFCL‑v4(복합 코드 작성) 두 개의 멀티턴 환경을 사용했다.
- 모델: Qwen3‑14B와 Qwen2.5‑14B 두 규모의 LLM을 동일한 프롬프트·리워드 설정으로 학습시켰다.
- 비교 대상: PPO‑GAE, PPO‑GRAE, REINFORCE‑GRAE(RLOO), GRPO, GSPO 등 기존 대표 알고리즘.
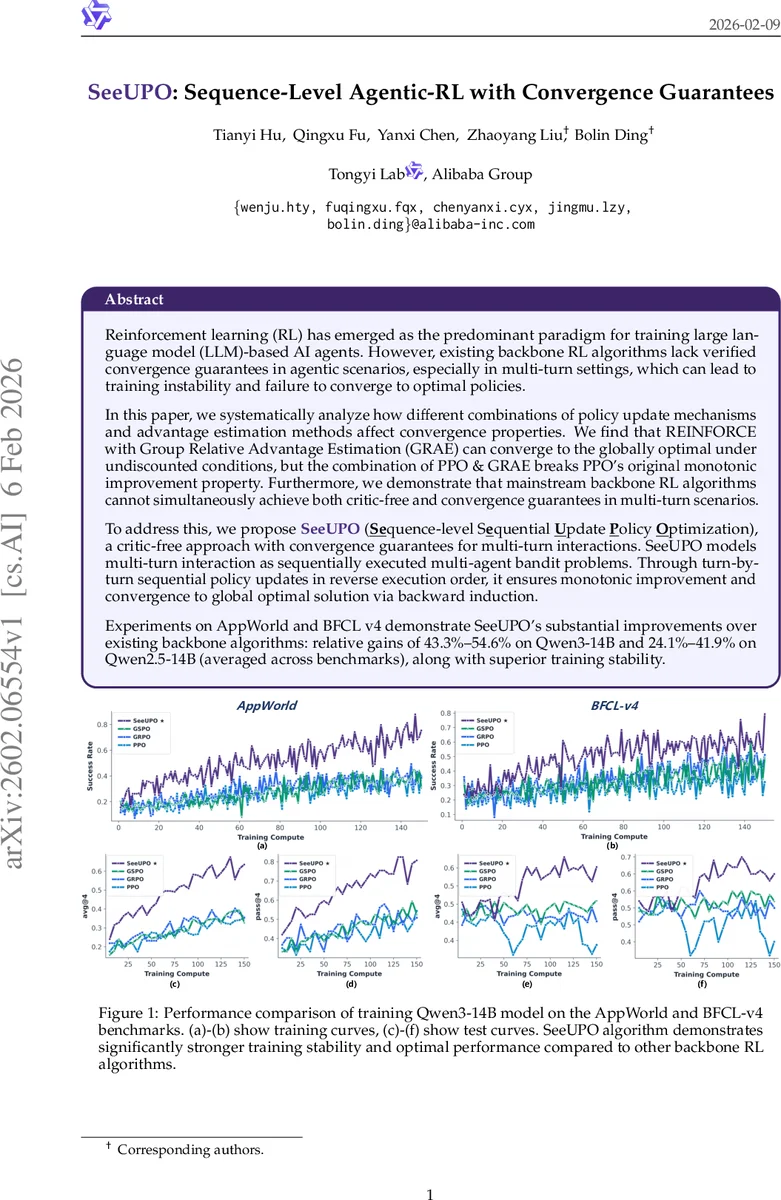
- 성능: SeeUPO는 avg@4와 pass@4 지표에서 각각 60.80%/72.85%(Qwen3)와 53.07%/63.59%(Qwen2.5)를 기록했으며, 이는 기존 방법 대비 43.3‑54.6% (Qwen3)와 24.1‑41.9% (Qwen2.5)의 상대적 향상을 의미한다.
- 안정성: 학습 곡선에서 급격한 손실 폭발이나 성능 급락이 거의 없었으며, PPO 기반 방법에서 관찰된 “catastrophic failure” 현상이 사라졌다. 추가 실험으로 역방향 업데이트가 아닌 순방향 업데이트를 적용하면 성능이 현저히 떨어짐을 확인, 이론적 증명의 실증적 타당성을 뒷받침한다.
-
의의와 한계
- SeeUPO는 “critic‑free + 수렴 보장”이라는 두 마리 토끼를 동시에 잡은 최초의 시퀀스‑레벨 RL 알고리즘으로, 대규모 LLM 에이전트의 다턴 학습에 실용적인 솔루션을 제공한다.
- 한계로는 (1) 역방향 업데이트를 위해 전체 턴이 사전에 정의되어야 하며, 동적 길이(가변 턴 수) 상황에서는 추가적인 패딩·마스킹 전략이 필요하다. (2) 현재 구현은 순수한 정책 네트워크만 사용하므로, 가치 기반 보조 신호를 활용한 하이브리드 접근법과의 비교는 아직 부족하다. 향후 연구에서는 가변 턴, 하이브리드 critic‑free 구조, 그리고 실제 로봇·시뮬레이션 환경으로의 확장이 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기